对于全球2.85 亿失明或视力低下的人来说,独立锻炼可能是一项挑战。今年早些时候,我们宣布了与盲人导盲组织合作开发的早期研究项目“指南计划” ,该项目使用机器学习引导跑步者穿越各种已用油漆线标记的环境。盲人导盲组织首席执行官托马斯·帕内克仅使用一部运行指南技术的手机和一副耳机,几十年来首次能够独立跑步,并在纽约市中央公园完成了无人协助的 5 公里跑步。
在不可预测的环境中安全可靠地引导盲人跑步者需要解决许多挑战。在这里,我们将介绍 Guideline 背后的技术,以及我们创建设备内置机器学习模型的过程,该模型可以引导 Thomas 进行独立的户外跑步。该项目仍处于开发阶段,但我们希望它可以帮助探索手机内置技术如何为盲人或视力低下者提供可靠、增强的移动和定位体验。

Thomas Panek 利用 Guideline 技术在户外独立跑步。
项目指南
Guideline 系统由一个佩戴在用户腰部、配有定制腰带和安全带的移动设备、用油漆或胶带标记的跑步路径上的辅助线以及骨传导耳机组成。Guideline 技术的核心是一个设备端分割模型,该模型以移动设备摄像头拍摄的帧作为输入,并将帧中的每个像素分为两类:“辅助线”和“非辅助线”。这个简单的置信度掩码应用于每一帧,使 Guideline 应用无需使用位置数据即可预测跑步者相对于路径上某条线的位置。根据这一预测和随后的平滑/过滤功能,应用会向跑步者发送音频信号,帮助他们确定方向并保持在路径上,或者发送音频警报,告诉跑步者在偏离路线太远时停止。
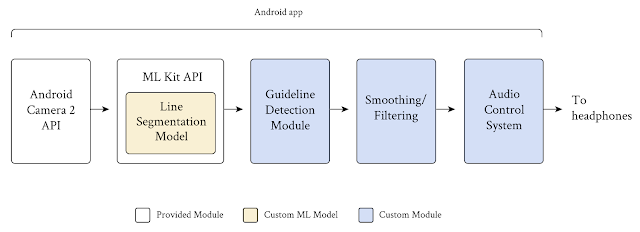
Project Guideline 使用 Android 内置的Camera 2和MLKit API,并添加自定义模块来分割指南、检测其位置和方向、过滤错误信号并实时向用户发送立体声音频信号。
在构建初步指南体系时,我们面临许多重大挑战:
系统精度:盲人和低视力人群的出行是一项挑战,其中用户安全至关重要。它要求机器学习模型能够生成准确且通用的分割结果,以确保跑步者在不同地点和各种环境条件下的安全。
系统性能:除了解决用户安全问题外,系统还需要性能出色、高效和可靠。它必须每秒处理至少 15 帧 (FPS),以便为跑步者提供实时反馈。它还必须能够运行至少 3 小时而不会耗尽手机电池,并且必须能够离线工作,如果步行/跑步路径位于没有数据服务的区域,则无需互联网连接。
缺乏领域内数据:为了训练分割模型,我们需要大量视频,视频中包含道路和跑道,上面有黄线。为了推广该模型,数据多样性与数据数量同样重要,需要在一天中的不同时间、不同的光照条件、不同的天气条件、不同的地点等条件下拍摄视频帧。
下面,我们针对每个挑战介绍解决方案。
网络架构
为了满足延迟和功率要求,我们在DeepLabv3框架 上构建了线分割模型,利用MobilenetV3-Small作为主干,同时将输出简化为两类——指导和背景。
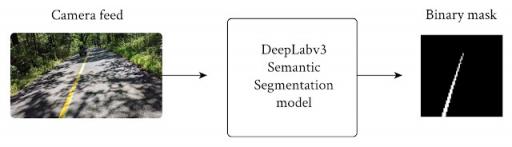
该模型采用 RGB 帧并生成输出灰度蒙版,表示每个像素预测的置信度。
为了提高吞吐速度,我们将摄像头馈送的图像尺寸从 1920 x 1080 像素缩小到 513 x 513 像素,作为 DeepLab 分割模型的输入。为了进一步加快 DeepLab 模型在移动设备上的使用速度,我们跳过了最后一个上采样层,直接输出 65 x 65 像素的预测蒙版。这些 65 x 65 像素的预测蒙版作为后处理的输入。通过在两个阶段最小化输入分辨率,我们能够缩短分割模型的运行时间并加快后处理速度。
数据收集
为了训练模型,我们需要目标域中的大量训练图像,这些图像展现了各种路径条件。毫不奇怪,公开可用的数据集是针对自动驾驶用例的,车顶安装有摄像头,汽车在车道线之间行驶,并不在目标域中。我们发现,由于领域差距很大,在这些数据集上训练模型的结果并不令人满意。相反,指南模型需要使用佩戴在人腰上的摄像头收集的数据,这些摄像头在线路上行驶,没有高速公路和拥挤的城市街道上发现的对抗物体。

自动驾驶数据集与目标领域之间的巨大领域差距。
由于现有的开源数据集对我们的用例没有帮助,我们创建了自己的训练数据集,其内容如下:
手工收集的数据:团队成员用鲜艳颜色的胶带在铺好的道路上临时放置指导线,并记录自己在一天中的不同时间和不同天气条件下在线上和周围奔跑的情况。
合成数据:由于 COVID-19 的限制,数据采集工作变得复杂且受到严重限制。这促使我们构建了一个自定义渲染管道来合成数以万计的图像,这些图像包括不同的环境、天气、光照、阴影和对抗对象。当模型在实际测试中遇到某些条件时,我们能够生成特定的合成数据集来解决这种情况。例如,该模型最初难以在成堆的落叶中分割出指导线。借助额外的合成训练数据,我们能够在后续的模型版本中纠正这个问题。
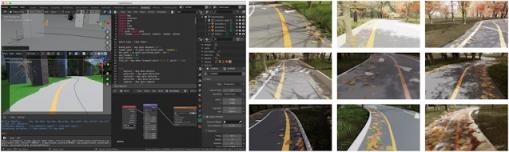
渲染管道生成合成图像来捕捉广泛的环境。
我们还创建了一个小型回归数据集,其中包含最常见场景和最具挑战性场景的注释样本,包括树木和人体阴影、落叶、对抗性道路标记、从指导线反射的阳光、急转弯、陡坡等。我们使用该数据集将新模型与之前的模型进行比较,以确保新模型准确度的整体提升不会掩盖在特别重要或具有挑战性的场景中准确度的下降。
训练过程
我们设计了一个三阶段训练程序,并使用迁移学习来克服领域内训练数据集有限的问题。我们首先使用在 Cityscape 上预先训练的模型,然后使用合成图像训练模型,因为这个数据集较大但质量较低。最后,我们使用收集到的有限领域内数据对模型进行微调。
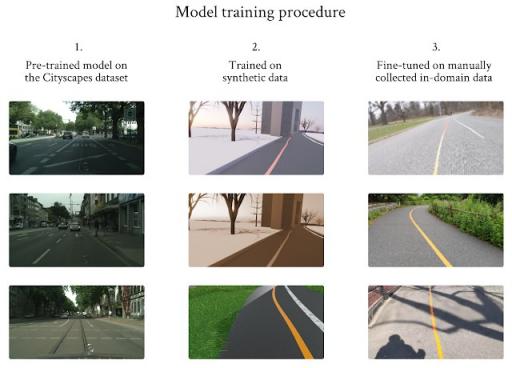
三阶段训练程序可克服数据有限的问题。左栏图片由 Cityscapes提供。
在开发初期,很明显分割模型的性能在图像帧的顶部受到影响。随着引导线在帧顶部远离相机的视点,线条本身开始消失。这导致预测的蒙版在帧的顶部不太准确。为了解决这个问题,我们计算了一个基于每帧前k个像素行的损失值。我们用这个值来选择那些包含模型难以处理的消失引导线的帧,并在这些帧上反复训练模型。这个过程不仅在解决消失线问题方面非常有用,而且在解决我们遇到的其他问题方面也非常有用,例如模糊的帧、曲线和对抗性物体的线条遮挡。

即使在具有挑战性的情况下,分割模型的准确性和稳健性也在不断提高。
系统性能
结合Tensorflow Lite和ML Kit,端到端系统在 Pixel 设备上运行速度非常快,在 Pixel 4 XL 上达到 29+ FPS,在 Pixel 5 上达到 20+ FPS。我们将分割模型完全部署在 DSP 上,在 Pixel 4 XL 上以 6 毫秒运行,在 Pixel 5 上以 12 毫秒运行,准确率很高。端到端系统在我们的评估数据集上实现了 99.5% 的帧成功率、93% 的mIoU,并通过了我们的回归测试。这些模型性能指标非常重要,使系统能够向用户提供实时反馈。
下一步
我们的探索仍处于起步阶段,但我们对我们的进展和未来感到兴奋。我们开始与其他为盲人和低视力群体服务的领先非营利组织合作,在公园、学校和公共场所制定更多指南。通过绘制更多线条、获得用户的直接反馈以及在更广泛的条件下收集更多数据,我们希望进一步推广我们的分割模型并改进现有的功能集。同时,我们正在研究新的研究和技术,以及可以提高整个系统稳健性和可靠性的新功能和能力。
要了解有关该项目及其起源的更多信息,请阅读 Thomas Panek 的故事。
致谢
Project Guideline 是 Google Research、Google Creative Lab 和无障碍团队共同合作的成果。我们特别要感谢我们的团队成员:Mikhail Sirotenko、Sagar Waghmare、Lucian Lonita、Tomer Meron、Hartwig Adam、Ryan Burke、Dror Ayalon、Amit Pitaru、Matt Hall、John Watkinson、Phil Bayer、John Mernacaj、Cliff Lungaretti、Dorian Douglass、Kyndra LoCoco。我们还要感谢 Fangting Xia、Jack Sim 以及来自 Mobile Vision 团队和 Guiding Eyes for the Blind 的其他同事和朋友。
评论