大型预训练自然语言处理(NLP) 模型(例如BERT、RoBERTa、GPT-3、T5和REALM)利用来自 Web 并针对特定任务数据进行微调的自然语言语料库,并在各种 NLP 任务中取得了重大进展。然而,自然语言文本本身所代表的知识覆盖范围有限,事实可能以多种不同的方式包含在冗长的句子中。此外,文本中非事实信息和有害内容的存在最终会导致生成的模型 出现偏差。
替代信息来源是知识图谱(KG),它由结构化数据组成。知识图谱本质上是事实性的,因为信息通常是从更可信的来源提取的,而后处理过滤器和人工编辑可确保删除不适当和不正确的内容。因此,可以整合它们的模型具有提高事实准确性和降低毒性的优势。然而,它们不同的结构格式使得很难将它们与语言模型中现有的预训练语料库集成。
在NAACL 2021上接受的 “基于知识图谱的合成语料库生成,用于知识增强型语言模型预训练”(KELM)中,我们探索将 KG 转换为合成自然语言句子,以增强现有的预训练语料库,使其能够集成到语言模型的预训练中,而无需进行架构更改。为此,我们利用公开可用的英语 Wikidata KG 并将其转换为自然语言文本,以创建合成语料库。然后,我们使用合成语料库来增强基于检索的语言模型REALM ,作为在预训练中整合自然语言语料库和 KG 的一种方法。我们已向更广泛的研究社区公开发布了这个语料库。
将知识图谱转换为自然语言文本
知识图谱由以结构化格式明确表示的事实信息组成,通常采用 [主体实体,关系,客体实体]三元组的形式,例如 [10x10 photobooks,inception,2012]。一组相关的三元组称为实体子图。基于上一个三元组示例构建的实体子图的示例是 { [10x10 photobooks,instance of,Nonprofit Organization],[10x10 photobooks,inception,2012] },如下图所示。知识图谱可以看作是相互连接的实体子图。
将子图转换为自然语言文本是 NLP 中的一项标准任务,称为数据到文本生成。尽管在WebNLG等基准数据集上,数据到文本生成已经取得了重大进展,但将整个KG转换为自然文本仍有更多挑战。大型 KG 中的实体和关系比小型基准数据集更加庞大和多样化。此外,基准数据集由预定义的子图组成,这些子图可以形成流畅而有意义的句子。对于整个 KG,也需要创建这种实体子图的细分。
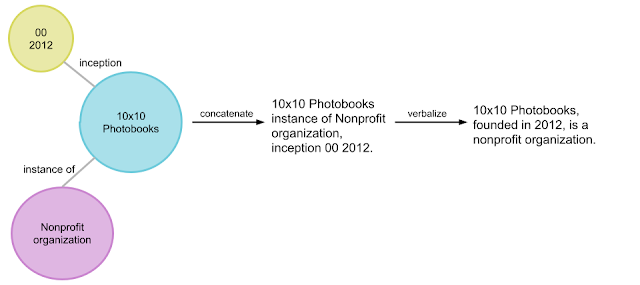
管道如何将实体子图(在气泡中)转换为合成自然句子(最右边)的示例说明。
为了将 Wikidata KG 转换为合成的自然句子,我们开发了一个名为“来自 KG 生成器的文本”(TEKGEN)的言语化流程,它由以下组件组成:一个由启发式对齐的 Wikipedia 文本和 Wikidata KG 三元组组成的大型训练语料库,一个文本到文本生成器(T5),用于将 KG 三元组转换为文本,一个实体子图创建器,用于生成要一起言语化的三元组组,最后是一个后处理过滤器,用于删除低质量输出。结果是一个包含整个 Wikidata KG 作为自然文本的语料库,我们将其称为知识增强语言模型(KELM)语料库。它包含约 1800 万个句子,涵盖约 4500 万个三元组和约 1500 个关系。

将知识图谱转换为自然语言,然后用于语言模型增强
融合知识图谱与自然文本进行语言模型预训练
我们的评估表明,知识图谱言语化是将知识图谱与自然语言文本相结合的有效方法。我们通过扩充 REALM 的检索语料库(仅包含维基百科文本)来证明这一点。
为了评估言语化的有效性,我们使用 KELM 语料库(即“言语化三元组”)扩充了 REALM 检索语料库,并将其性能与不使用言语化的串联三元组扩充进行比较。我们在两个流行的开放域问答数据集上测量了每种数据扩充技术的准确率:自然问题和网络问题。
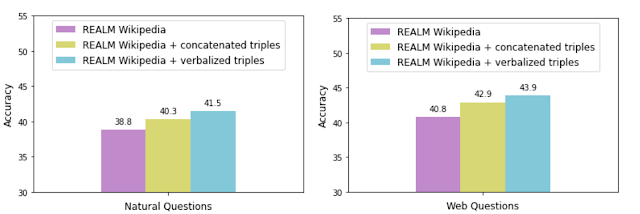
甚至使用串联三元组来增强 REALM 也能提高准确率,可能会添加未在文本中明确表达或根本没有表达的信息。但是,使用言语化三元组进行增强可以使 KG 与自然语言文本语料库更顺畅地集成,准确率更高就是明证。我们还在名为LAMA的知识探测器上观察到了同样的趋势,该探测器使用填空问题来查询模型。
结论
借助 KELM,我们以自然文本的形式提供公开可用的KG 语料库。我们表明,KG 言语化可用于将 KG 与自然文本语料库集成,以克服它们的结构差异。这对于知识密集型任务(例如问答)具有实际应用,在这些任务中,提供事实知识至关重要。此外,此类语料库可应用于大型语言模型的预训练,并有可能降低毒性并提高事实性。我们希望这项工作能够促进将结构化知识源集成到大型语言模型的预训练中的进一步发展。
致谢
这项工作是 Oshin Agarwal、Heming Ge、Siamak Shakeri 和 Rami Al-Rfou 的合作成果。我们感谢 William Woods、Jonni Kanerva、Tania Rojas-Esponda、Jianmo Ni、Aaron Cohen 和 Itai Rolnick 对合成语料库样本进行评级以评估其质量。我们还感谢 Kelvin Guu 对本文提出的宝贵反馈。
评论