假设人们的面部表情是普遍的,这似乎是合理的——例如,无论一个人来自巴西、印度还是加拿大,他们见到亲密朋友时的微笑或在烟花表演时敬畏的表情基本上都是一样的。但这是真的吗?这些面部表情与不同地域的相关背景之间的关联真的具有普遍性吗?人们微笑或皱眉的情景之间的相似之处(或差异)能告诉我们不同文化之间的人们是如何联系在一起的吗?
科学家们试图回答这些问题,并揭示人们在不同文化和地域之间联系的程度,他们经常使用基于调查的研究,这种研究在很大程度上依赖于当地的语言、规范和价值观。然而,这类研究不具有可扩展性,而且往往样本量小,结果也不一致。
与基于调查的研究相比,研究面部运动模式可以更直接地了解表达行为。但要分析面部表情在日常生活中的实际使用方式,研究人员需要查看数百万小时的真实世界镜头,这太耗时了,无法手动完成。此外,面部表情及其表现的环境非常复杂,需要大量样本才能得出统计上合理的结论。虽然现有研究对特定环境中面部表情的普遍性问题得出了不同的 答案,但应用机器学习 (ML) 来适当扩展研究可能会提供清晰的答案。
在《自然》杂志发表的 《全球 16 种面部表情在相似环境中出现》一文中,我们介绍了与加州大学伯克利分校合作开展的研究,该研究首次对面部表情在日常生活中的实际使用情况进行了大规模的全球分析,利用深度神经网络(DNN) 以负责任和深思熟虑的方式大幅扩展表情分析。我们使用来自 144 个国家/地区的 600 万个公开视频数据集,分析了人们使用各种面部表情的环境,并表明面部行为的丰富细微差别(包括微妙的表情)在世界各地的类似社交场合中都有使用。
测量面部表情的深度神经网络
面部表情不是静态的。如果一个人一刻不停地观察一个人的表情,起初看起来是“愤怒”,但最终可能会变成“敬畏”、“惊讶”或“困惑”。解释取决于一个人面部表情的动态。因此,构建一个理解面部表情的神经网络的挑战在于,它必须在时间背景下解释表情。训练这样的系统需要一个庞大、多样、跨文化的视频数据集,其中包含完整的表情注释。
为了构建数据集,熟练的评估员手动搜索了大量可公开获取的视频,以找出可能包含涵盖我们所有预先选定的表情类别的剪辑的视频。为了确保视频与它们所代表的地区相匹配,在选择视频时优先考虑那些包含原产地理位置的视频。然后使用深度卷积神经网络 (CNN)(类似于 Google Cloud Face Detection API )找到视频中的人脸,该网络使用基于传统光流的方法在整个剪辑过程中跟踪人脸。然后,注释者使用类似于Google Crowdsource 的界面,标记剪辑过程中任何时候出现的28 个不同类别的面部表情。由于目标是抽样调查普通人如何看待表情,因此注释者没有接受过指导或培训,也没有提供目标表情的示例或定义。我们将在下文讨论其他实验,以评估从这些注释训练出来的模型是否存在偏差。
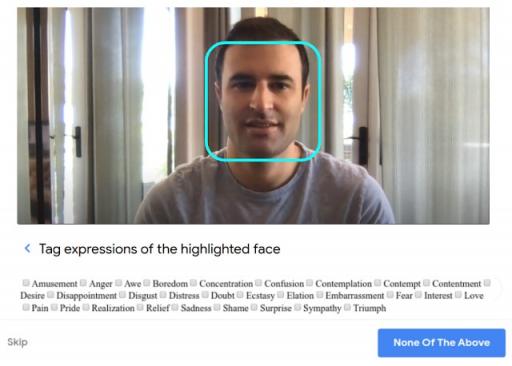
评分者观看的视频中,只有一张脸被突出显示以引起他们的注意。他们在整个视频过程中观察对象,并注释其表现出的面部表情。(源视频)
人脸检测算法确定了视频中每张脸的位置序列。然后,我们使用预先训练的Inception 网络从脸部中提取代表面部表情最显著方面的特征。然后,这些特征被输入到长短期记忆(LSTM) 网络中,这是一种循环神经网络,由于能够记住过去的显著信息,因此能够模拟面部表情随时间的变化方式。
为了确保模型在一系列人口群体中做出一致的预测,我们在使用类似面部表情标签构建的 现有数据集上评估了模型的公平性,目标是针对其表现出最佳性能的 16 种表情子集。
该模型的表现在评估数据集中代表的所有人口群体中都是一致的,这提供了支持证据,表明训练用于注释面部表情的模型没有明显的偏差。您可以在此处探索该模型对 1,500 张图像中这 16 种面部表情的注释。
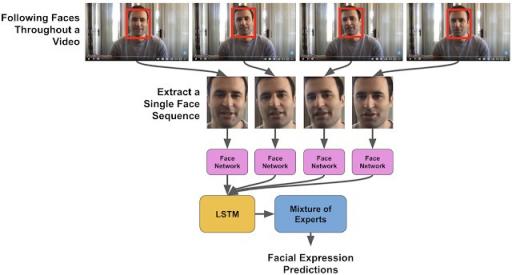
我们使用 CNN 从每帧的脸部中提取特征,对每个视频中选定的脸部进行建模,然后将其输入到 LSTM 网络中,以模拟表情随时间的变化。(源视频)
测量视频中捕捉到的情境
为了理解数百万个视频中面部表情的背景,我们使用了能够捕捉细粒度内容并自动识别背景的 DNN。第一个 DNN 建模了与视频相关的文本特征(标题和描述)以及实际视觉内容的组合(视频主题模型)。此外,我们使用了仅依赖文本特征而不依赖任何视觉信息的 DNN(文本主题模型)。这些模型预测了数千个描述视频的标签。在我们的实验中,这些模型能够识别数百种独特的背景(例如婚礼、体育赛事或烟花),展示了我们用于分析的数据的多样性。
世界各地的表达方式与语境的共变
在我们的第一个实验中,我们分析了 300 万个用手机拍摄的公开视频。我们选择关注移动上传的视频,因为它们更有可能包含自然表情。我们将视频中出现的面部表情与从视频主题模型中得出的上下文注释相关联。我们发现 16 种面部表情与全球范围内一致的日常社交环境有着不同的关联。例如,人们与娱乐相关的表情更常出现在恶作剧视频中;人们与敬畏相关的表情更常出现在烟花视频中;而与胜利相关的表情则出现在体育赛事中。这些结果对于讨论面部表情中心理相关背景相对于其他因素(例如个人、文化或社会所独有的因素)的相对重要性具有重要意义。
我们的第二个实验分析了一组单独的 300 万个视频,但这次我们使用文本主题模型注释了上下文。结果证实,第一个实验中的发现不是由视频中的面部表情对视频主题模型注释的细微影响所驱动的。换句话说,我们利用这个实验来验证第一个实验的结论,因为视频主题模型在计算其内容标签时可能会隐式地考虑面部表情。
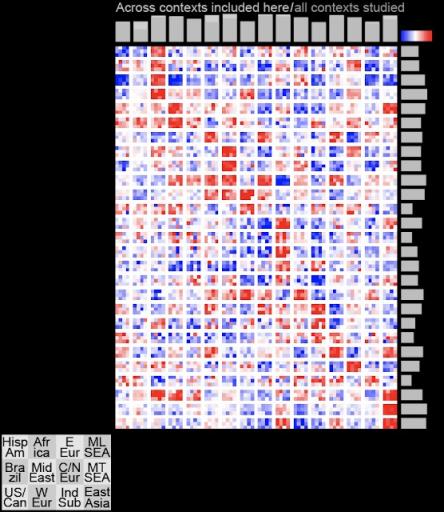
我们对每个地区的所有视频中的表情和上下文注释进行了关联。我们发现,每种表情都与不同的上下文有着特定的关联,这些关联在 12 个世界地区中都得到了保留。例如,这里用红色表示,我们可以看到,人们与敬畏相关的表情在烟花、宠物和玩具的上下文中出现的频率高于在其他上下文中出现的频率。
在两个实验中,表情和语境之间的相关性似乎在不同文化中都得到了很好的保留。为了量化我们所研究的 12 个不同世界地区表情和语境之间的关联究竟有多相似,我们计算了每对地区之间的二阶相关性。这些相关性确定了每个地区不同表情和语境之间的关系,然后将它们与其他地区进行比较。我们发现,每个地区发现的 70% 的语境-表情关联在整个现代世界中是相同的。
最后,我们想知道,我们测量的 16 种面部表情中,有多少种与世界各地保留的不同背景具有不同的关联。为此,我们应用了一种称为典型相关分析的方法,该方法表明,所有 16 种面部表情都具有世界各地保留的不同关联。
结论
我们能够以前所未有的规模研究不同文化中日常生活中面部表情出现的环境。机器学习使我们能够分析全球数百万个视频,并发现支持以下假设的证据:不同文化中的面部表情在相似的环境中会在一定程度上保留下来。
我们的结果也考虑到了文化差异。尽管面部表情和背景之间的相关性在世界各地有 70% 的一致性,但不同地区之间的差异高达 30%。邻近地区的面部表情和背景之间的关联通常比遥远地区的更相似,这表明人类文化的地理分布也可能对面部表情的含义产生影响。
这项研究表明,我们可以使用机器学习来更好地了解自己,并识别跨文化的共同沟通要素。DNN 等工具让我们有机会提供大量多样化的数据以服务于科学发现,从而对统计结论更有信心。我们希望我们的工作能为以负责任的方式使用机器学习工具提供一个模板,并激发其他科学领域的更多创新研究。
致谢
特别感谢我们的合著者、加州大学伯克利分校的 Dacher Keltner,以及 Google Research 的 Florian Schroff、Brendan Jou 和 Hartwig Adam。我们还感谢 Google 的 Laura Rapin、Reena Jana、Will Carter、Unni Nair、Christine Robson、Jen Gennai、Sourish Chaudhuri、Greg Corrado、Brian Eoff、Andrew Smart、Raine Serrano、Blaise Aguera y Arcas、Jay Yagnik 和 Carson Mcneil 提供的额外支持。
评论