自动文本到图像合成是一项具有挑战性的任务,其中训练模型仅根据文本描述生成图像,最近 受到了 广泛 关注。 它的研究为机器学习 (ML) 模型如何捕获视觉属性并将其与文本关联提供了丰富的见解。 与指导图像创建的其他类型的输入(例如草图、对象蒙版或鼠标轨迹(我们在之前的工作中重点介绍过))相比,描述性句子是一种更直观、更灵活的表达视觉概念的方式。 因此,强大的自动文本到图像生成系统也可以成为快速创建内容的有用工具,并且可以应用于许多其他创意应用,类似于将机器学习融入艺术创作的其他努力(例如,Magenta)。
最先进的图像合成结果通常是使用生成对抗网络(GAN) 实现的,该网络训练两个模型 - 一个生成器,试图创建逼真的图像,以及一个鉴别器,试图确定图像是真实的还是伪造的。许多文本到图像生成模型都是使用文本输入进行条件反射以生成语义相关图像的GAN 。这非常具有挑战性,尤其是在提供冗长而模糊的描述时。此外,GAN 训练容易出现模式崩溃,这是训练过程中常见的失败情况,其中生成器学习仅产生一组有限的输出,因此鉴别器无法学习稳健的策略来识别伪造的图像。为了缓解模式崩溃,一些方法使用多阶段细化网络来迭代细化图像。但是,这样的系统需要多阶段训练,效率低于更简单的单阶段端到端模型。其他努力依赖于分层方法,首先对对象布局进行建模,然后最终合成逼真的图像。这需要使用标记的分割数据,但这些数据可能很难获得。
在CVPR 2021上发表的 “跨模态对比学习文本到图像生成”中,我们介绍了跨模态对比生成对抗网络 (XMC-GAN),它通过学习使用模态间 (图像-文本) 和模态内 (图像-图像) 对比损失来最大化图像和文本之间的相互信息来解决文本到图像的生成问题。这种方法有助于鉴别器学习更稳健、更具鉴别力的特征,因此即使使用单阶段训练,XMC-GAN 也不太容易出现模式崩溃。重要的是,与之前的多阶段或分层方法相比,XMC-GAN 通过简单的单阶段生成实现了最先进的性能。它是端到端可训练的,并且只需要图像-文本对(而不是标记分割或边界框数据)。
文本到图像合成的对比损失
文本到图像合成系统的目标是生成清晰、逼真的场景,并使其与条件文本描述具有高语义保真度。为了实现这一目标,我们建议最大化以下对应对之间的相互信息:(1) 图像(真实或生成)和描述场景的句子;(2) 具有相同描述的生成图像和真实图像;(3) 图像(真实或生成)的区域及其相关的单词或短语。
在 XMC-GAN 中,这是使用对比损失来强制执行的。与其他 GAN 类似,XMC-GAN 包含一个用于合成图像的生成器,以及一个经过训练可充当真实图像和生成图像之间的批评者的鉴别器。三组数据导致了该系统的对比损失——真实图像、描述这些图像的文本以及根据文本描述生成的图像。生成器和鉴别器各自的损失函数是从整个图像与完整文本描述计算出的损失与从细分图像与相关单词或短语计算出的损失的组合。然后,对于每一批训练数据,我们计算每个文本描述与真实图像之间的余弦相似度得分,同样,计算每个文本描述与一批生成图像之间的余弦相似度得分。目标是使匹配对(文本到图像和真实图像到生成图像)具有高相似度得分,使不匹配对具有低得分。强制执行这种对比损失允许鉴别器学习更稳健和更具判别力的特征。
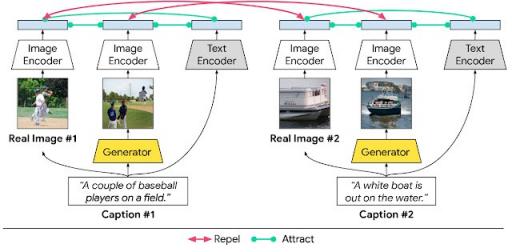
我们提出的 XMC-GAN 文本到图像合成模型中的模式间和模式内对比学习。
结果
我们将 XMC-GAN 应用于三个具有挑战性的数据集 - 第一个是MS-COCO 图像的MS-COCO描述的集合,另外两个是带有本地化叙述注释的数据集,其中一个涵盖 MS-COCO 图像(我们称之为 LN-COCO),另一个描述Open Images数据(LN-OpenImages)。我们发现 XMC-GAN 在每个数据集上都达到了新的最佳水平。XMC-GAN 生成的图像描绘的场景比使用其他技术生成的图像质量更高。在 MS-COCO 上,XMC-GAN 将最先进的Fréchet 初始距离(FID) 得分从 24.7 提高到 9.3,并且受到人类评估者的青睐。
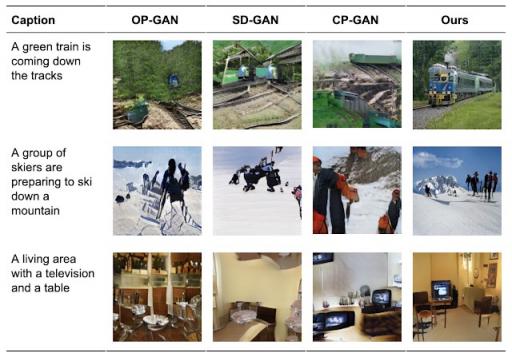
在MS-COCO上生成图像的选定定性结果。
类似地,与其他三种最先进的方法(CP-GAN、SD-GAN和 OP-GAN )相比,人类评分者 77.3% 的时间更喜欢 XMC-GAN 生成的图像的图像质量,74.1% 的时间更喜欢它的图像文本对齐。
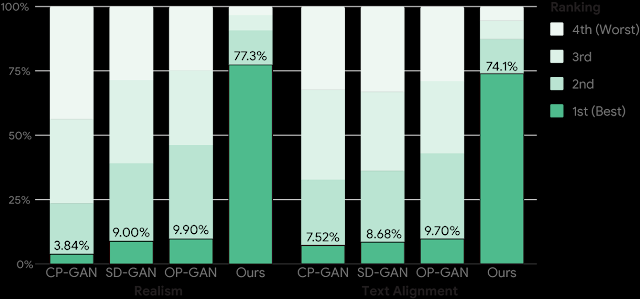
在MS-COCO上对图像质量和文本对齐进行人工评估。注释者将生成的图像(匿名且按随机顺序)从最好到最差进行排序。
XMC-GAN 还可以很好地推广到具有挑战性的本地化叙事数据集,其中包含更长、更详细的描述。我们之前的工作 TReCS使用鼠标轨迹输入来解决本地化叙事的文本到图像生成问题,以提高图像生成质量。尽管没有收到鼠标轨迹注释,但 XMC-GAN 在 LN-COCO 上的图像生成方面的表现明显优于 TReCS,将最先进的 FID 从 48.7 提高到 14.1。将鼠标轨迹和其他额外输入纳入 XMC-GAN 等端到端模型将是未来研究的有趣之举。
此外,我们还在 LN-OpenImages 上进行训练和评估,这比 MS-COCO 更具挑战性,因为数据集更大,图像涵盖的主题范围更广,也更复杂(平均 8.4 个对象)。据我们所知,XMC-GAN 是第一个在 Open Images 上进行训练和评估的文本到图像合成模型。XMC-GAN 能够生成高质量的结果,并在这项极具挑战性的任务上设定了 26.9 的强大基准 FID 分数。

Open Images 上真实图像和生成图像的随机样本。
结论和未来工作
在这项工作中,我们提出了一个跨模态对比学习框架来训练 GAN 模型进行文本到图像的合成。我们研究了几种跨模态对比损失,以加强图像和文本之间的对应关系。对于人工评估和定量指标,XMC-GAN 在多个数据集上都比以前的模型有了显著的改进。它生成与输入描述相匹配的高质量图像,包括长篇详细叙述,并且同时是一个更简单的端到端模型。我们相信,这代表了从自然语言描述生成图像的创造性应用的重大进步。随着我们继续这项研究,我们将根据我们的AI 原则不断评估负责任的方法、潜在应用和风险缓解措施。
致谢
这是与 Jason Baldridge、Honglak Lee 和 Yinfei Yang 合作完成的。我们要感谢 Kevin Murphy、Zizhao Zhang 和 Dilip Krishnan 提供的有益反馈。我们还要感谢 Google 数据计算团队在进行人工评估方面所做的工作。我们也非常感谢 Google 研究团队的总体支持。
评论