数据是机器学习 (ML) 的一个基础方面,会影响 ML 系统的性能、公平性、稳健性和可扩展性。矛盾的是,虽然构建 ML 模型通常具有很高的优先级,但与数据本身相关的工作往往是优先级最低的方面。这种数据工作可能需要多个角色(例如数据收集者、注释者和 ML 开发人员),并且通常涉及多个团队(例如数据库、法律或许可团队)来支持数据基础设施,这增加了任何与数据相关的项目的复杂性。因此,人机交互(HCI) 领域专注于让技术对人们有用和可用,它可以帮助识别潜在问题,并在数据相关工作不被优先考虑时评估对模型的影响。
在 2021 年ACM CHI 大会上发表的 “ ‘每个人都想做模型工作,而不是数据工作’:高风险 AI 中的数据级联”中,我们研究并验证了数据问题导致技术债务随时间推移而产生的下游影响(定义为“数据级联”)。具体来说,我们通过全球 ML 从业者在重要 ML 领域(例如癌症检测、山体滑坡检测、贷款分配等)的数据实践和挑战来说明数据级联现象——ML 系统在这些领域取得了进展,但也有机会通过解决数据级联问题来改进。据我们所知,这项工作首次将 ML 中的数据级联形式化、衡量和讨论,并将其应用于实际项目。我们进一步讨论了将机器学习数据集体重新想象为高优先级所带来的机遇,包括奖励机器学习数据工作和工作者、承认机器学习数据研究中的科学经验主义、提高数据管道的可见性以及改善全球数据公平性。
数据级联的起源
我们观察到,数据级联通常起源于机器学习系统生命周期的早期,即数据定义和收集阶段。级联在诊断和表现上也往往很复杂且不透明,因此通常没有明确的指标、工具或指标来检测和衡量其影响。正因为如此,与数据相关的小障碍可能会发展成更大、更复杂的挑战,影响模型的开发和部署方式。数据级联带来的挑战包括需要在开发过程的后期执行昂贵的系统级更改,或者由于数据问题导致的模型错误预测而导致用户信任度下降。然而,令人鼓舞的是,我们还观察到,通过对机器学习开发进行早期干预,可以避免此类数据级联。
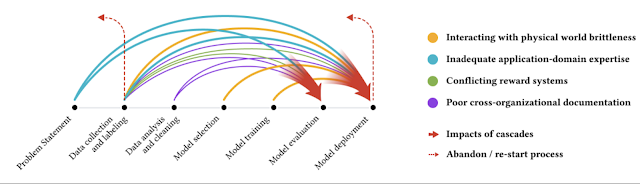
不同颜色的箭头表示不同类型的数据级联,通常起源于上游,在 ML 开发过程中复合,并在下游体现。
数据级联的示例
数据级联的最常见原因之一是当在无噪声数据集上训练的模型部署到通常充满噪声的现实世界中时。例如,一种常见的数据级联类型源于模型漂移,当目标变量和独立变量出现偏差时就会发生模型漂移,从而导致模型准确性降低。当模型与新的数字环境(包括高风险领域,如空气质量传感、海洋传感和超声波扫描)紧密交互时,由于没有预先存在和/或整理的数据集,漂移会更常见。这种漂移会导致更多因素进一步降低模型的性能(例如,与硬件、环境和人类知识相关)。例如,为了确保良好的模型性能,数据通常在受控的内部环境中收集。但在资源受限的新数字环境的实时系统中,更常见的是使用指纹、阴影、灰尘、不适当的照明和笔标记等物理伪影来收集数据,这些都会增加影响模型性能的噪音。在其他情况下,雨水和风等环境因素可能会意外地移动部署中的图像传感器,这也会引发连锁反应。正如我们采访的一位模型开发人员所报告的那样,即使是一滴油或水也会影响可用于训练癌症预测模型的数据,从而影响模型的性能。由于漂移通常是由现实环境中的噪音引起的,因此它们也需要最长的时间(长达 2-3 年)才能显现出来,几乎总是在生产过程中出现。
当 ML 从业者负责管理他们专业知识有限的领域的数据时,可能会发生另一种常见的数据级联。例如,某些类型的信息(如识别偷猎地点或在水下探索期间收集的数据)依赖于生物科学、社会科学和社区背景方面的专业知识。然而,我们研究中的一些开发人员描述了必须采取一系列超出其领域专业知识的数据相关操作(例如,丢弃数据、更正值、合并数据或重新开始数据收集)导致限制模型性能的数据级联。依赖技术专业知识而非领域专业知识的做法(例如,通过与领域专家合作)似乎是引发这些级联的原因。
本文观察到的另外两个连锁反应是由数据收集者、机器学习开发者和其他合作伙伴之间的激励机制和组织实践冲突造成的,例如,一个连锁反应是由糟糕的数据集文档引起的。虽然与数据相关的工作需要多个团队之间的仔细协调,但当利益相关者对优先事项或工作流程不一致时,这尤其具有挑战性。
如何解决数据级联
解决数据级联问题需要在机器学习研究和实践中采用多部分系统性的方法:
开发和传达机器学习系统所基于的数据优劣概念,类似于我们思考模型拟合优度的方式。这包括开发标准化指标,并经常使用这些指标来衡量数据方面,例如现象学保真度(数据如何准确全面地表示现象)和有效性(数据如何很好地解释与数据捕获的现象相关的事物),类似于我们开发良好指标来衡量模型性能的方式,例如F1 分数。
创新激励措施以认可数据工作,例如欢迎在会议轨道上进行数据实证研究、奖励数据集维护或奖励员工在组织中对数据(收集、标记、清理或维护)的工作。
数据工作通常需要跨多个角色和多个团队进行协调,但目前这种协调非常有限(部分原因是前面提到的因素,但并非完全如此)。我们的研究表明,促进数据收集者、领域专家和机器学习开发人员之间更好的协作、透明度和更公平的利益分配具有重要意义,尤其是对于依赖于收集或标记小众数据集的机器学习系统而言。
最后,我们在多个国家开展的研究表明,数据稀缺在低收入国家尤为突出,机器学习开发人员还面临着定义和手动整理新数据集的额外问题,这使得开始开发机器学习系统变得十分困难。为了解决当前全球数据不平等问题,重要的是启用开放数据集库、制定数据政策并培养政策制定者和民间社会的机器学习素养。
结论
在这项工作中,我们既提供了经验证据,又将 ML 系统中的数据级联概念形式化。我们希望让人们意识到激励数据卓越性可能带来的潜在价值。我们还希望为 HCI 引入一个尚未得到充分探索但意义重大的新研究议程。我们对数据级联的研究已在修订后的PAIR 指南中为数据收集和评估提供了有证据支持的、最先进的指南,该指南面向 ML 开发人员和设计人员。
致谢
本文由 Shivani Kapania、Hannah Highfill、Diana Akrong、Praveen Paritosh 和 Lora Aroyo 合作撰写。我们感谢研究参与者,以及 Sures Kumar Thoddu Srinivasan、Jose M. Faleiro、Kristen Olson、Biswajeet Malik、Siddhant Agarwal、Manish Gupta、Aneidi Udo-Obong、Divy Thakkar、Di Dang 和 Solomon Awosupin。
评论