近年来,由于对比学习的应用,自监督表征学习已在各种图像和视频任务中得到应用,并取得了显著的进步。这些对比学习方法通常教会模型在嵌入空间中将目标图像(又称“锚点”)和匹配(“正”)图像的表征组合在一起,同时将锚点与许多不匹配(“负”)图像分开。由于在自监督学习中假设标签不可用,因此正例通常是锚点的增强,而负例则选择为来自训练小批量的其他样本。然而,由于这种随机抽样,假负例(即从与锚点同一类的样本生成的负例)会导致表征质量下降。此外,确定生成正例的最佳方法仍然是一个活跃的研究领域。
与自监督方法相比,全监督方法可以使用标记数据从现有的同类示例中生成正样本,从而在预训练中提供比仅通过增强锚点通常可以实现的更多变化。然而,在全监督领域成功应用对比学习的研究成果非常少。
在NeurIPS 2020上发表的 “有监督对比学习”中,我们提出了一种名为 SupCon 的新型损失函数,它弥合了自监督学习和全监督学习之间的差距,并使对比学习能够应用于监督设置。利用标记数据,SupCon 鼓励将来自同一类的规范化嵌入拉近,而将来自不同类的嵌入推开。这简化了正向选择的过程,同时避免了潜在的假阴性。由于它每个锚点可容纳多个正向样本,因此这种方法可以改进正向样本的选择,这些样本更加多样化,同时仍包含语义相关信息。SupCon 还允许标签信息在表示学习中发挥积极作用,而不是像传统对比学习那样将其限制在下游训练中。据我们所知,这是第一个在大规模图像分类问题上始终表现优于使用交叉熵损失直接训练模型的常用方法的对比损失。重要的是,SupCon 易于实现且训练稳定,为许多数据集和架构(包括Transformer架构)提供了 top-1 准确率的持续提升,并且对图像损坏和超参数变化具有很强的鲁棒性。
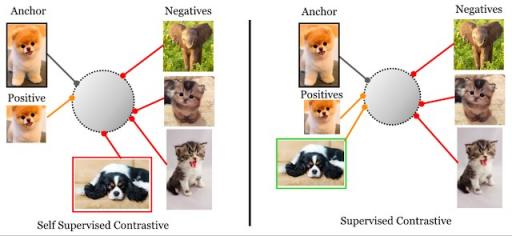
自监督(左)与监督(右)对比损失:自监督对比损失将每个锚点(即同一图像的增强版本)的单个正例与由整个小批量的其余部分组成的一组负例进行对比。然而,本文考虑的监督对比损失将来自同一类别的所有样本集作为正例与来自批量其余部分的负例进行对比。
监督对比学习框架
SupCon 可以看作是 SimCLR和N -pair损失的泛化——前者使用与锚点相同的样本生成的正样本,后者使用利用已知类别标签的不同样本生成的正样本。每个锚点使用大量正样本和大量负样本,使 SupCon 能够实现最佳性能,而无需进行难以适当调整的硬负样本挖掘(即搜索与锚点相似的负样本)。

SupCon 包含了文献中的多种损失,并且是 SimCLR 和 N-Pair 损失的概括。
该方法在结构上类似于自监督对比学习中使用的方法,但针对监督分类进行了修改。给定一个输入数据批次,我们首先应用两次数据增强来获得批次中每个样本的两个副本或“视图”(尽管可以创建和使用任意数量的增强视图)。两个副本都通过编码器网络前向传播,然后对得到的嵌入进行L2 归一化。按照标准做法,表示进一步通过可选的投影网络传播,以帮助识别有意义的特征。监督对比损失是在投影网络的归一化输出上计算的。锚点的正例由来自与锚点同一批实例或具有与锚点相同标签的其他实例的表示组成;负例则是所有剩余的实例。为了衡量下游任务的性能,我们在冻结的表示之上训练了一个线性分类器。
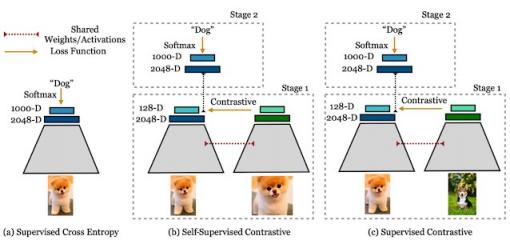
交叉熵、自监督对比损失和监督对比损失左:交叉熵损失使用标签和 softmax 损失来训练分类器。中:自监督对比损失使用对比损失和数据增强来学习表征。右:监督对比损失也使用对比损失来学习表征,但除了对同一幅图像进行增强外,还使用标签信息来采样正样本。
主要发现
与交叉熵、边缘分类器(使用标签)和自监督对比学习技术相比,SupCon 在CIFAR-10 和 CIFAR-100以及ImageNet数据集上持续提升了 top-1 准确率。借助 SupCon,我们在ResNet-50 和 ResNet-200架构的 ImageNet 数据集上实现了出色的 top-1 准确率。在 ResNet-200 上,我们实现了 81.4% 的 top-1 准确率,比使用相同架构的最先进的交叉熵损失提高了 0.8% (这对 ImageNet 来说是一个重大进步)。我们还在基于 Transformer 的 ViT-B/16模型上比较了交叉熵和 SupCon ,发现在相同的数据增强方案下(未进行任何更高分辨率的微调),交叉熵得到了持续的改进(ImageNet 为 77.8% 对比 76%;CIFAR-10 为 92.6% 对比 91.6%)。
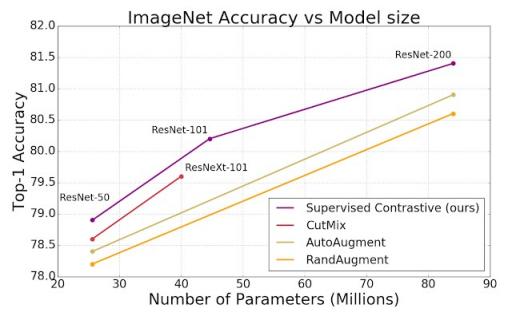
使用标准数据增强策略( AutoAugment、RandAugment和CutMix ), SupCon 损失始终优于交叉熵。我们在 ResNet-50、ResNet-101 和 ResNet200 上展示了 ImageNet 的 top-1 准确率。
我们还通过分析证明了我们的损失函数的梯度鼓励从困难正例和困难负例中学习。困难正例/负例的梯度贡献很大,而容易正例/负例的梯度贡献很小。这种隐式属性使对比损失可以避开显式硬挖掘的需要,这是许多损失(例如三重态损失)中微妙但关键的部分。请参阅我们论文的补充材料以了解完整的推导。
SupCon 对自然损坏(例如噪声、模糊和 JPEG 压缩)也具有更强的鲁棒性。平均损坏误差(mCE) 衡量与基准ImageNet-C数据集相比的平均性能下降。与交叉熵模型相比,SupCon 模型在不同损坏情况下的 mCE 值较低,表明鲁棒性有所提高。
我们通过实证研究证明,SupCon 损失对一系列超参数的敏感度低于交叉熵。随着增强、优化器和学习率的变化,我们观察到对比损失输出的方差明显降低。此外,在保持所有其他超参数不变的情况下应用不同的批次大小,SupCon 的 top-1 准确率始终优于交叉熵。
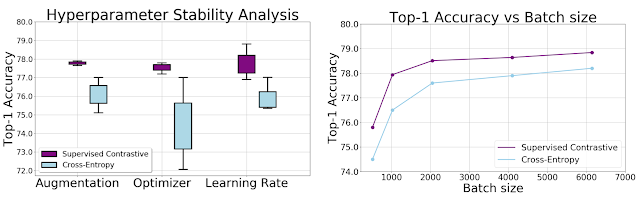
使用 ResNet-50 编码器在 ImageNet 上测量的交叉熵和监督对比损失的准确度与超参数和训练数据大小的关系。左图:箱线图显示 Top-1 准确度与增强、优化器和学习率的变化。SupCon 在每个变化中产生更一致的结果,这在最佳策略先验未知时很有用。右图: Top-1 准确度与批次大小的关系表明,两种损失都受益于较大的批次大小,而 SupCon 具有更高的 Top-1 准确度,即使在使用小批次大小进行训练时也是如此。
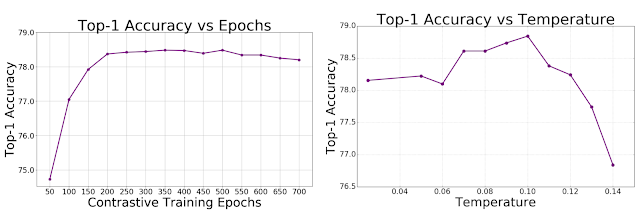
使用 ResNet-50 编码器在 ImageNet 上测量的监督对比损失的准确度与训练持续时间和温度超参数的关系。左图: Top-1 准确度与 SupCon 预训练时期的关系。右图: Top-1 准确度与 SupCon 预训练阶段的温度的关系。温度是对比学习中的一个重要超参数,降低对温度的敏感性是可取的。
更广泛的影响和后续步骤
这项工作为监督分类领域带来了技术进步。监督对比学习可以以最小的复杂性提高分类器的准确性和鲁棒性。经典的交叉熵损失可以看作是 SupCon 的一个特例,其中视图对应于图像,而最终线性层中学习到的嵌入对应于标签。我们注意到 SupCon 受益于大批量,能够在较小的批量上训练模型是未来研究的重要课题。
我们的 Github 存储库包含用于训练论文中模型的 Tensorflow 代码。我们的预训练模型也在TF-Hub 上 发布。
致谢
NeurIPS 论文由 Prannay Khosla、Piotr Teterwak、Chen Wang、Aaron Sarna、Yonglong Tian、Phillip Isola、Aaron Maschinot、Ce Liu 和 Dilip Krishnan 共同撰写。特别感谢 Jenny Huang 领导这篇博文的撰写过程。
评论