表征学习是一种机器学习 (ML) 方法,它训练模型来识别可应用于各种下游任务的显著特征,从自然语言处理(例如BERT和ALBERT)到图像分析和分类(例如Inception 层和SimCLR)。去年,我们推出了一个用于比较语音表征的基准,以及一个新的、通用的语音表征模型 ( TRILL )。TRILL 基于时间接近度,并尝试将时间上接近的语音映射到可捕获嵌入空间中时间接近度的低维嵌入。自发布以来,研究界已将 TRILL 用于多种任务,例如年龄分类、视频缩略图选择和语言识别。然而,尽管实现了最先进的性能,但与处理简单特征(如响度、平均能量、音高等)的信号处理操作相比,TRILL 和其他基于神经网络的方法需要更多的内存,并且计算时间更长。
在我们最近的论文《FRILL:一种用于移动设备的非语义语音嵌入》中,该论文将在Interspeech 2021上发表,我们创建了一个新模型,其大小是 TRILL 的 40%,并且其特征集在手机上的计算速度可以提高 32 倍以上,平均准确率下降不到 2%。这标志着语音 ML 模型向设备端全面应用迈出了重要一步,这将带来更好的个性化、更好的用户体验和更大的隐私保护,这是负责任地开发 AI的一个重要方面。我们在 github 上发布了创建 FRILL 的代码,并在TensorFlow Hub上发布了预训练的 FRILL 模型。
FRILL:更小、更快的 TRILL
TRILL 架构基于ResNet50的修改版本,该架构对于硬件受限的手机或智能家居设备等计算量较大。另一方面,MobileNetV3等架构已设计有硬件感知的AutoML,可在移动设备上表现出色。为了利用这一点,我们利用知识提炼将 MobileNetV3 的性能优势与 TRILL 的表示相结合。
在提炼过程中,较小的模型(即“学生”)尝试在AudioSet数据集 上匹配较大模型(“老师”)的输出。原始 TRILL 模型通过优化自监督损失来学习权重,该损失将音频片段聚类到时间上接近,而学生模型则通过全监督损失来学习权重,该损失忽略时间匹配,而是尝试在训练数据上匹配 TRILL 输出。全监督学习信号通常比自监督更强,并允许我们更快地进行训练。
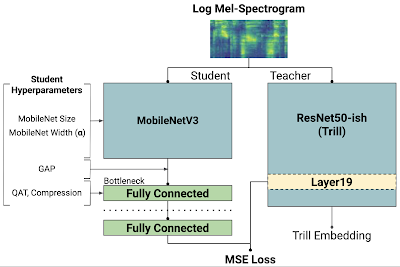
非语义语音嵌入的知识提炼。虚线显示学生模型输出。“教师网络”是 TRILL 网络,其中“第 19 层”是表现最佳的内部表示。左侧的“学生超参数”是本研究中探索的选项,其结果是 144 个不同的模型。这些模型经过 均方误差 (MSE) 训练,以尝试匹配 TRILL 的第 19 层。
选择最佳学生模型
我们使用各种学生模型进行蒸馏,每个模型都使用特定的架构选择组合进行训练(如下所述)。为了测量每个学生模型的延迟,我们利用TensorFlow Lite (TFLite),这是一个支持在边缘设备上执行 TensorFlow 模型的框架。每个候选模型首先转换为 TFLite 的flatbuffer格式以进行 32 位浮点推理,然后发送到目标设备(在本例中为 Pixel 1)进行基准测试。这些测量有助于我们准确评估所有学生模型的延迟与质量权衡,并最大限度地减少转换过程中的质量损失。
架构选择和优化
我们探索了不同的神经网络架构和功能,以平衡延迟和准确性——参数较少的模型通常更小、更快,但表示能力较弱,因此生成的表示不太通用。我们训练了 144 个不同的模型,涵盖多个超参数,所有模型均基于 MobileNetV3 架构:
MobileNetV3 的大小和宽度: MobileNetV3 发布了不同的大小,以用于不同的环境。大小指的是我们使用的 MobileNetV3 架构。宽度(有时称为alpha)按比例减少或增加每层中的过滤器数量。宽度 1.0 对应于原始论文中的过滤器数量。
全局平均池化: MobileNetV3 通常会生成一组二维特征图。这些图被展平、连接并传递到瓶颈层。但是,这个瓶颈通常仍然太大而无法快速计算。我们通过对每个输出特征图中的所有“像素”取全局平均值来减小瓶颈层内核的大小。我们的直觉是,由于信号的相关方面在时间上是稳定的,因此丢弃的时间信息对于学习非语义语音表示不太重要。
瓶颈压缩:学生模型权重的很大一部分位于瓶颈层。为了减小此层的大小,我们应用了基于奇异值分解(SVD) 的压缩算子,该算子学习瓶颈权重矩阵的低秩近似值。
量化感知训练:由于瓶颈层具有大部分模型权重,我们使用量化感知训练(QAT) 在训练期间逐渐降低瓶颈权重的数值精度。QAT 允许模型在训练期间适应较低的数值精度,而不是在训练完成后引入量化而可能导致性能下降。
结果
我们在非语义语音基准(NOSS) 和两个新任务 上评估了这些模型中的每一个——一个具有挑战性的任务是检测说话者是否戴着口罩,以及环境声音分类数据集的人为噪声子集,其中包括“咳嗽”和“打喷嚏”等标签。在排除了具有严格更好的替代方案的模型后,我们在质量与延迟曲线上剩下八个“前沿”模型,这些模型在我们的 144 个模型批次中,在相应的质量阈值或延迟下没有更快和更好的性能替代方案。我们在下面绘制了仅这些“前沿”模型的延迟与质量曲线,并忽略了严格更差的模型。
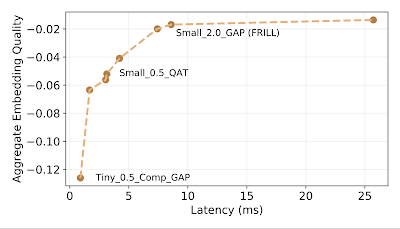
嵌入质量和延迟权衡。x 轴表示推理延迟,y 轴表示与 TRILL 性能的准确度差异,取基准数据集的平均值。
FRILL 是性能最佳的 10 毫秒以下推理模型,在 Pixel 1 上的推理时间为 8.5 毫秒(比 TRILL 快 32 倍左右),大小也约为 TRILL 的 40%。前沿曲线在延迟约 10 毫秒时达到稳定状态,这意味着在低延迟下,可以以最小的延迟成本实现更好的性能,而在延迟超过 10 毫秒时实现更好的性能则更加困难。这支持了我们对实验超参数的选择。FRILL 的每项任务性能如下表所示。
褶边 颤音
大小 (MB) 38.5 98.1
延迟(毫秒) 8.5 275.3
Voxceleb1 * 45.5 46.8
沃克斯福吉 78.8 84.5
语音命令 81.0 81.7
CREMA-D 71.3 65.9
保存 63.3 70.0
蒙面演说 68.0 65.8
ESC-50 HS 87.9 86.4
每个分类任务的准确率(越高越好)。
*我们研究的结果使用了根据内部隐私指南过滤的 Voxceleb1 的一小部分。感兴趣的读者可以使用 TensorFlow 数据集和我们的开源评估代码对完整数据集进行研究。
最后,我们评估每个超参数的相对贡献。我们发现,对于我们的实验,量化感知训练、瓶颈压缩和全局平均池化最能降低生成模型的延迟。同时,瓶颈压缩最能降低生成模型的质量,而池化对模型性能的降低最小。架构宽度参数是减小模型大小的重要因素,同时性能下降最小。
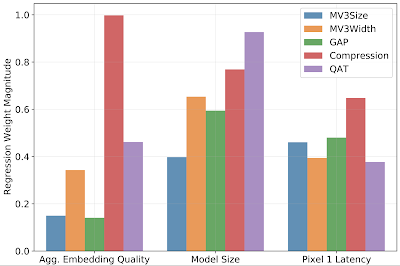
用于预测模型质量、延迟和大小的线性回归权重大小。权重表示改变输入超参数的预期影响。权重大小越高,预期影响越大。
我们的工作是将语音机器学习研究的全部优势引入移动设备的重要一步。我们还提供了我们的 公共模型、相应的模型卡和评估代码,以帮助研究界负责任地开发更多用于设备上语音表示研究的应用程序。
致谢
我们要感谢我们的论文合著者:Jacob Peplinski、Jake Garrison 和 Shwetak Patel。我们要感谢 Aren Jansen 对这个项目的技术支持、Françoise Beaufays 和 Tulsee Doshi 帮助开源该模型,以及 Google Research, Tokyo 提供的后勤支持。
评论