自然科学、社会科学和医学等学科都必须努力解决如何在不断变化的现实世界中评估和比较结果的问题。相比之下,大量机器学习 (ML) 研究使用了一种不同的方法,该方法依赖于固定世界的假设:在固定数据集上测量基线模型的性能,然后构建一个旨在改进基线的新模型,并通过将其性能与基线进行比较来评估其性能(在相同的固定数据上)。
研究机器人系统及其在现实世界中的应用需要重新思考这种实验设计。即使在受控的机器人实验室环境中,现实世界的变化也可能导致基线模型随着时间的推移而表现不一致,因此不清楚新模型的性能是相对于基线有所改进,还是仅仅是实验设置中无意的随机变化的结果。随着机器人研究进入更复杂、更具挑战性的现实世界场景,人们越来越需要了解不断变化的世界对基线的影响,并开发系统方法来生成信息丰富、清晰的结果。
在这篇文章中,我们将展示即使在相对受控的实验室环境中,机器人研究也会受到环境变化的重大影响,并讨论如何使用随机分配和A/B 测试解决这一基本挑战。虽然这些是经典的研究方法,但它们通常不是机器人研究中的默认方法——然而,它们对于在现实场景中为机器人产生有意义且可衡量的科学结果至关重要。此外,我们还介绍了使用这些方法的成本、好处和其他注意事项。
机器人技术不断变化的现实世界
即使在机器人实验室环境中,设计时会尽量减少实验条件以外的所有变化,但要设置一个完全可重复的实验也是非常困难的。机器人会受到撞击和磨损,照明变化会影响感知,电池电量会影响施加到电机上的扭矩——所有这些都可能以大大小小的方式影响结果。
为了在真实机器人数据上说明这一点,我们收集了最简单的设置之一的成功率数据——将相同的泡沫骰子从一个箱子移动到另一个箱子。对于这项任务,我们在五个多月的时间里使用相同的软件和 ML 模型在两个机器人上进行了大约 33000 次任务试验,并将过去两周的总体成功率作为基准。然后,我们在这个“控制得非常好”的环境中测量了一段时间内的历史表现。

真实机器人完成任务的视频:将相同的泡沫骰子从一个箱子移动到另一个箱子。
鉴于我们在数据收集过程中没有刻意改变任何东西,人们可以预期成功率在统计上会随着时间的推移而相似。然而,这并不是观察到的结果。
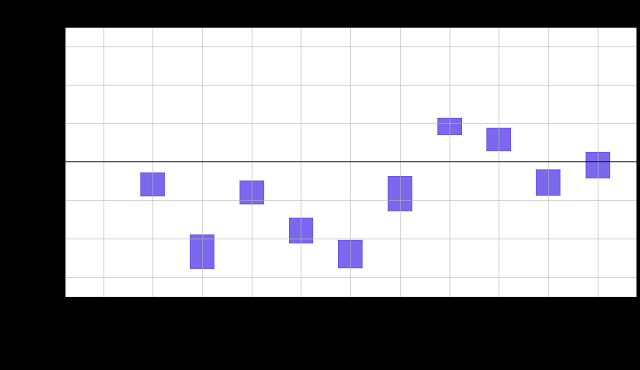
y 轴表示相对于基线的成功率变化百分比的 95% 置信区间。如果置信区间包含零,则表示成功率在统计上与基线的成功率相似。使用Jackknife计算置信区间,并使用Cochran-Mantel-Haenszel 校正来消除操作员偏差。
使用上图中的顺序数据,人们可能会得出这样的结论:运行于第 13-14 周的模型表现最佳,运行于第 9-10 周的模型表现最差。人们可能还认为上述大多数(如果不是全部)置信区间都包含 0,但只有一个包含 0。由于在这些试验期间没有进行任何更改,因此此示例有效地展示了无意的、随机的现实世界变化对即使是非常简单的设置的影响。还值得注意的是,每个实验进行更多试验不会消除这些差异,相反,它们更有可能产生更窄的置信区间,从而使影响更加明显。
但是,如果使用随机分配来比较结果,将数据随机分组而不是按顺序分组,会发生什么情况?为了回答这个问题,我们将上述数据随机分配到相同数量的组中,以便与基线进行比较。这相当于进行 A/B 测试,其中所有组都接受相同的处理。
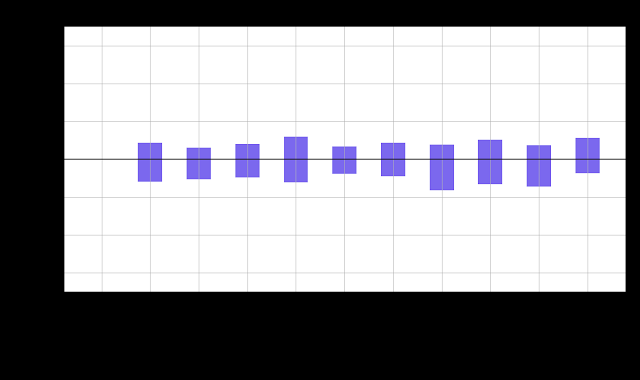
查看图表,我们发现置信区间包含零,表明成功与基线相似,正如预期的那样。
我们对其他一些机器人任务进行了类似的研究,比较了顺序任务和随机任务。它们都得出了类似的结果。
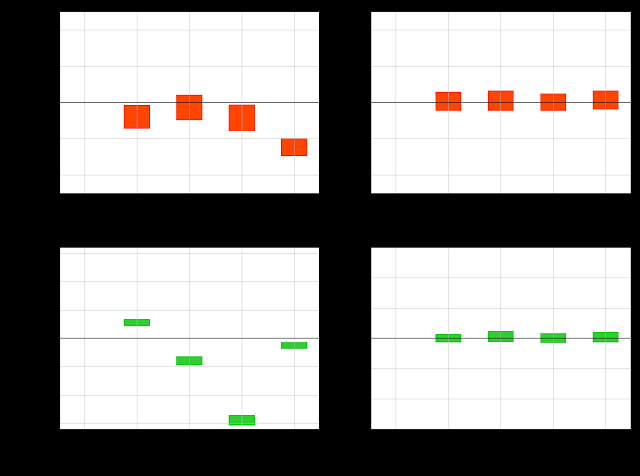
我们发现,即使没有刻意改变,顺序分配也会存在统计学上的显著差异,而随机分配则显示出预期的结果,即没有统计学上的显著差异。
机器人技术中 A/B 测试的注意事项
虽然根据上述内容可以清楚地看出,使用随机分配的 A/B 测试是控制机器人技术中现实世界无法解释的差异的有效方法,但在采用这种方法时仍需考虑一些因素。以下是其中的一些因素,以及它们的优点、缺点和解决方案:
绝对性能与相对性能:每个实验都需要根据同时运行的基线进行测量。基线和实验之间的相对性能指标以置信区间的形式发布。绝对性能指标(在基线或实验中)的信息量较少,因为它在一定程度上取决于测量时的世界状况。然而,我们测量的实验和基线之间的统计差异是合理的,并且对再现性具有鲁棒性。
数据效率: 使用这种方法时,基线始终需要与实验条件并行运行,以便可以相互比较。虽然这看起来有点浪费,但与根据陈旧的基线做出无效推断的缺点相比,这样做是值得的。此外,随着随机分配实验数量的增加,我们可以利用Google的重叠实验基础设施,使用单个基线组和多个跨独立因素的同步实验组。数据效率随着规模的扩大而提高。
环境偏差:如果有任何外部因素影响整体表现(照明、光滑表面等),基线和所有实验组都会以相似的概率遇到该因素,因此如果没有相对影响,其影响将会抵消。如果环境因素和实验组之间存在相关性,这将随着时间的推移显示为差异(每个环境因素都会在收集的事件中累积)。这可以大大减少或消除费力的环境重置的需要,并让我们能够进行终身实验,同时仍能衡量实验组的改进情况。
人为偏见:随机分配的一个优点是可以减少人为偏见。由于人类操作员无法知道哪个数据样本会被分配到哪个实验组,因此有偏见的实验者很难影响任何特定结果。
前进的道路
长期以来,A/B 测试实验框架已成功应用于许多科学学科,用于衡量在不断变化且不可预测的现实环境中的性能。在这篇博文中,我们展示了机器人研究可以从使用相同的方法中受益:它提高了研究结果的质量和可信度,并避免了完美控制根本变化的环境的所有元素这一不可能完成的任务。要做好这一点,需要基础设施来持续操作机器人、收集数据,以及工具,使研究人员可以轻松访问统计框架。
致谢
Arnab Bose、Tuna Toksoz、Yuheng Kuang、Anthony Brohan 和 Razvan Sudulescu 开发了实验基础设施并开展了研究。Matthieu Devin 建议使用 A/A 分析来展示使用现有数据的差异。特别感谢 Bill Heavlin、Chris Harris 和 Vincent Vanhoucke 为这项工作提供了宝贵的反馈和支持。
评论