模拟使各种工程学科能够以最少的人力快速制作原型。在机器人技术领域,物理模拟为机器人提供了一个安全且廉价的虚拟游乐场,使其能够利用深度强化学习(DRL)等技术获得物理技能。然而,由于模拟中手工推导的物理与现实世界并不完全匹配,因此完全在模拟中训练的控制策略在真实硬件上测试时可能会失败——这一挑战被称为模拟与现实差距或领域适应问题。感知型任务(如抓取)的模拟与现实差距已通过使用RL-CycleGAN 和 RetinaGAN得到解决,但机器人系统的动态特性仍会造成差距。这促使我们问自己,我们能否从少数真实的机器人轨迹中学习到更精确的物理模拟器?如果是这样,这种改进的模拟器可用于使用标准 DRL 训练来改进机器人控制器,使其在现实世界中取得成功。
在我们的ICRA 2021出版物“ SimGAN:通过对抗性强化学习实现域自适应的混合模拟器识别”中,我们建议将物理模拟器视为一个可学习的组件,该组件由 DRL 训练,并带有特殊的奖励函数,该函数会惩罚模拟中生成的轨迹(即机器人随时间的运动)与在真实机器人上收集的少量轨迹之间的差异。我们使用生成对抗网络(GAN) 来提供这样的奖励,并制定了一个结合可学习神经网络和分析物理方程的混合模拟器,以平衡模型表达力和物理正确性。在机器人运动任务上,我们的方法优于多个强基线,包括域随机化。
可学习的混合模拟器
传统的物理模拟器是一个通过求解微分方程来模拟虚拟世界中物体的运动或相互作用的程序。为了完成这项工作,需要构建不同的物理模型来表示不同的环境——如果机器人在床垫上行走,就需要考虑床垫的变形(例如,使用有限元方法)。然而,由于机器人在现实世界中可能遇到的场景多种多样,这种针对特定环境的建模技术会非常繁琐(甚至不可能),这就是为什么采用基于机器学习的方法会很有用的原因。虽然模拟器可以完全从数据中 学习,但如果训练数据没有包含足够多种情况,那么学习到的模拟器如果需要模拟未经训练的情况,可能会违反物理定律(即偏离现实世界的动态)。因此,在这种有限的模拟器中训练的机器人更有可能在现实世界中失败。
为了克服这一复杂情况,我们构建了一个混合模拟器,它结合了可学习的神经网络和物理方程。具体来说,我们用可学习的模拟参数函数替换通常手动定义的模拟器参数——接触参数(例如摩擦和恢复系数)和电机参数(例如电机增益),因为未建模的接触和电机动力学细节是模拟与现实差距的主要原因。与将这些参数视为常量的传统模拟器不同,在混合模拟器中,它们是状态相关的——它们可以根据机器人的状态而变化。例如,电机在高速下会变弱。可以使用状态相关的模拟参数函数捕获这些通常未建模的物理现象。此外,虽然接触和电机参数通常难以识别并且会因磨损而发生变化,但我们的混合模拟器可以从数据中自动学习它们。例如,模拟无需手动指定机器人脚部可能接触的每个可能表面的参数,而是从训练数据中学习这些参数。
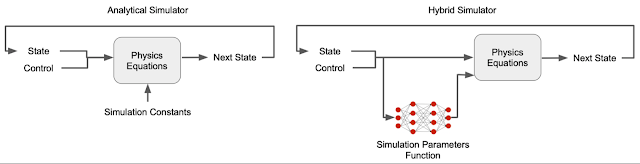
传统模拟器和我们的混合模拟器之间的比较。
混合模拟器的另一部分由物理方程组成,确保模拟遵循物理基本定律,例如能量守恒定律,使其更接近现实世界,从而缩小模拟与现实的差距。
在我们之前的床垫示例中,可学习的混合模拟器能够模拟床垫的接触力。由于学习到的接触参数与状态相关,因此模拟器可以根据机器人脚相对于床垫的距离和速度调节接触力,从而模拟可变形表面的刚度和阻尼的影响。因此,我们不需要专门为可变形表面设计一个分析模型。
使用 GAN 进行模拟器学习
成功学习上面讨论的模拟参数函数将产生一个混合模拟器,它可以生成与在真实机器人上收集的轨迹相似的轨迹。实现这种学习的关键是定义轨迹之间相似性的度量。GAN最初设计用于生成与少量真实图像具有相同分布或“风格”的合成图像,可用于生成与真实轨迹难以区分的合成轨迹。GAN 有两个主要部分:一个学习生成新实例的生成器,以及一个评估新实例与训练数据的相似程度的鉴别器。在这种情况下,可学习的混合模拟器充当 GAN 生成器,而 GAN 鉴别器提供相似度分数。
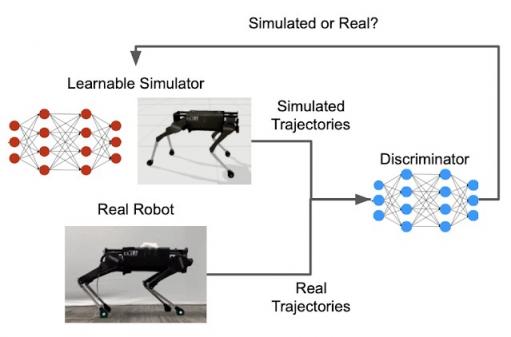
GAN 鉴别器提供了相似度度量,用于比较模拟机器人和真实机器人的运动。
将模拟模型的参数与现实世界中收集的数据进行拟合,这一过程称为系统识别(SysID),在许多工程领域是一种常见的做法。例如,可以通过测量不同压力下表面的位移来识别可变形表面的刚度参数。这个过程通常是手动的,很繁琐,但使用 GAN 可以提高效率。例如,SysID 通常需要手工制作模拟轨迹和真实轨迹之间差异的度量。使用 GAN,鉴别器会自动学习这样的度量。此外,为了计算差异度量,传统的 SysID 需要将每个模拟轨迹与使用相同控制策略生成的相应真实世界轨迹配对。由于 GAN 鉴别器仅将一条轨迹作为输入并计算其在现实世界中被收集的可能性,因此不需要这种一对一的配对。
使用强化学习 (RL) 来学习模拟器并完善策略
综上所述,我们将模拟学习表述为强化学习问题。神经网络从少量真实世界轨迹中学习状态相关的接触和运动参数。神经网络经过优化,可最大限度地减少模拟轨迹与真实轨迹之间的误差。请注意,在较长时间内最小化此误差非常重要——准确预测更远未来的模拟将带来更好的控制策略。强化学习非常适合此目的,因为它可以优化随时间推移的累积奖励,而不仅仅是优化单步奖励。
在混合模拟器学习并变得更加准确之后,我们再次使用 RL 来完善机器人在模拟中的控制策略(例如,在表面上行走,如下所示)。
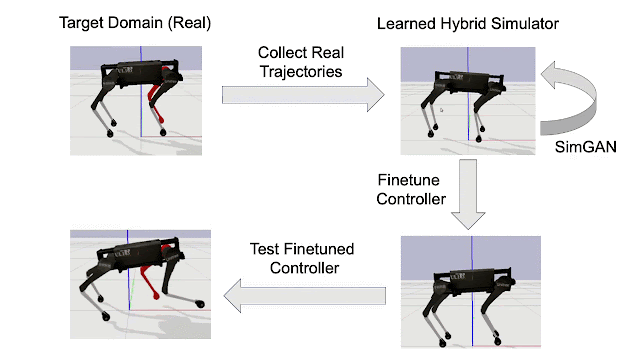
按照箭头顺时针方向:(左上)记录机器人在目标域中少量的失败尝试(例如,真实世界的代理,其中红色的腿被修改为比源域重得多);(右上)学习混合模拟器以匹配在目标域中收集的轨迹;(右下)在这个学习过的模拟器中改进控制策略;(左下)直接在目标域中测试改进后的控制器。
评估
由于 2020 年期间无法接触到真实机器人,我们创建了第二个不同的模拟(目标域)作为现实世界的代理。源域和目标域之间的动态变化足够大,可以近似不同的模拟与现实差距(例如,让一条腿更重,在可变形的表面而不是硬地板上行走)。我们评估了我们的混合模拟器在不了解这些变化的情况下是否可以学习匹配目标域中的动态,以及此学习模拟器中的改进策略是否可以成功部署到目标域中。
下面的定性结果表明,使用在目标域(地板可变形)中收集的少于 10 分钟的数据进行模拟学习能够生成精细的策略,该策略对于具有不同形态和动态的两个机器人来说表现更好。
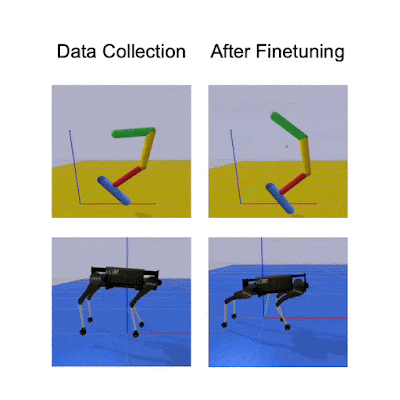
比较料斗和四足机器人在目标域(可变形地板)中的初始策略与改进策略之间的性能。
下面的定量结果表明,SimGAN 的表现优于多个最先进的基线,包括域随机化 (DR) 和目标域中的直接微调 (FT)。
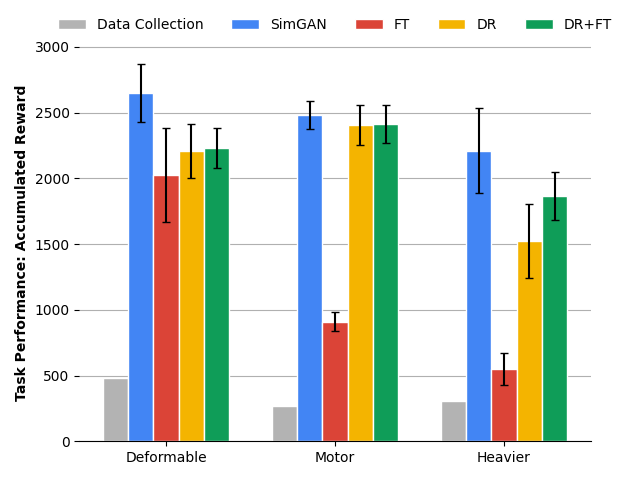
使用不同的模拟到现实传输方法在四足机器人的三个不同目标领域中比较策略性能:在可变形表面上运动、使用较弱的马达运动和使用较重的机身运动。
结论
模拟与现实之间的差距是阻碍机器人利用强化学习能力的关键瓶颈之一。我们通过学习一个能够更忠实地模拟现实世界动态的模拟器来应对这一挑战,同时仅使用少量现实世界数据。在此模拟器中改进的控制策略可以成功部署。为了实现这一点,我们用可学习的组件增强了一个经典物理模拟器,并使用对抗性强化学习训练这个混合模拟器。到目前为止,我们已经测试了它在运动任务中的应用,我们希望通过将其应用于其他机器人学习任务(例如导航和操纵)来构建这个通用框架。
致谢
我们要感谢我们的论文合著者:Tingnan Zhang、Daniel Ho、Yunfei Bai、C. Karen Liu 和 Sergey Levine。我们还要感谢 Google 机器人团队的讨论和反馈。
评论