监督学习是一种机器学习任务,使用具有已知结果的数据点(即标记数据)来训练预测模型,由于其简单性,通常是业界首选的方法。然而,监督学习需要准确标记的数据,而这些数据的收集往往是劳动密集型的。此外,随着模型效率随着架构、算法和硬件(GPU / TPU )的改进而提高,训练大型模型以实现更好的质量变得更加容易,而这反过来又需要更多的标记数据才能继续进步。
为了缓解此类数据采集挑战,半监督学习(一种将少量标记数据与大量未标记数据相结合的机器学习范例)最近已通过UDA、SimCLR等方法取得了成功。在我们之前的工作中,我们首次证明了半监督学习方法Noisy Student可以通过利用更多未标记的示例在ImageNet(一种大规模学术图像分类基准) 上实现最佳性能。
受这些结果的启发,今天我们很高兴地展示了半监督蒸馏 (SSD),这是 Noisy Student 的简化版本,并展示了它在语言领域的成功应用。我们将 SSD 应用于 Google 搜索环境中的语言理解,从而实现了高性能提升。这是半监督学习首次在如此大规模上应用的成功案例,并展示了此类方法对生产规模系统的潜在影响。
吵闹的学生培训
在我们开发 Noisy Student 之前,已经有大量关于半监督学习的研究。然而,尽管进行了广泛的研究,但此类系统通常仅在低数据环境下运行良好,例如CIFAR、SVHN和 10% ImageNet。当标记数据丰富时,此类模型无法与完全监督的学习系统竞争,这阻碍了半监督方法应用于重要的生产应用,例如搜索引擎和自动驾驶汽车。这一缺点促使我们开发了Noisy Student Training,这是一种半监督学习方法,在高数据环境下运行良好,并且当时使用 1.3 亿张额外的未标记图像在 ImageNet 上实现了最先进的准确率。
吵闹学生训练有 4 个简单的步骤:
在标记数据上训练分类器(老师)。
然后,老师在更大的未标记数据集上推断伪标签。
然后,它在组合的标记和伪标记数据上训练更大的分类器,同时还添加噪音(嘈杂的学生)。
(可选)回到步骤 2,该学生可以被用作新老师。
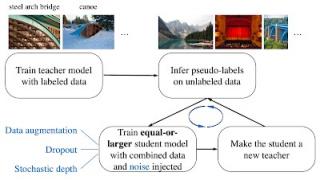
通过四个简单步骤说明噪声学生训练。我们使用两种类型的噪声:模型噪声(Dropout 、 随机深度)和输入噪声(数据增强,例如 RandAugment )。
可以将“嘈杂学生”视为一种自我训练的形式,因为模型会生成伪标签,然后利用这些伪标签重新训练自身以提高性能。“嘈杂学生训练”的一个令人惊讶的特性是,经过训练的模型在未优化的稳健性测试集(包括ImageNet-A、ImageNet-C 和 ImageNet-P)上表现极佳。我们假设,在训练过程中添加的噪声不仅有助于学习,而且还使模型更加稳健。

基线模型错误分类但 Noisy Student 正确分类的图像示例。左图: ImageNet-A 中未经修改的图像。中图和右图:从 ImageNet-C 中选择的添加了噪声的图像。有关包括 ImageNet-P 在内的更多示例,请参阅论文。
与知识提炼的联系
嘈杂学生类似于知识蒸馏,知识蒸馏是将知识从大型模型(即教师)转移到较小模型(学生)的过程。蒸馏的目标是提高速度,以便构建一个可以在生产中快速运行的模型,而不会与教师相比牺牲太多质量。蒸馏的最简单设置涉及单个教师并使用相同的数据,但在实践中,可以使用多个教师或为学生使用单独的数据集。
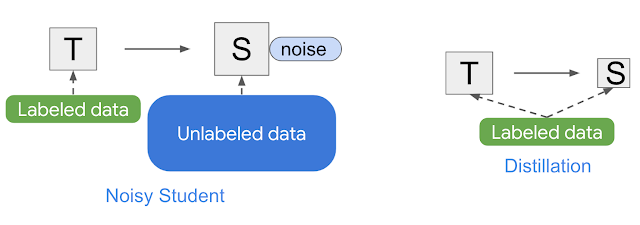
吵闹学生和知识提炼的简单插图。
与 Noisy Student 不同,知识蒸馏不会在训练过程中添加噪音(例如数据增强或模型正则化),并且通常涉及较小的学生模型。相反,人们可以将 Noisy Student 视为“知识扩展”的过程。
半监督蒸馏
训练生产模型的另一种策略是两次应用 Noisy Student 训练:首先获得较大的教师模型 T',然后获得较小的学生模型 S。这种方法产生的模型比单独使用监督学习或 Noisy Student 训练的效果更好。具体来说,当应用于一系列EfficientNet模型的视觉领域时,从具有 5.3M 个参数的 EfficientNet-B0 到具有 66M 个参数的 EfficientNet-B7,此策略在每个给定的模型大小下都能实现更好的性能(有关更多详细信息,请参阅Noisy Student 论文的表 9 )。
噪声学生训练需要数据增强,例如RandAugment(用于视觉)或SpecAugment(用于语音)才能正常工作。但在某些应用中,例如自然语言处理,这种类型的输入噪声并不容易获得。对于这些应用,可以简化噪声学生训练以使其没有噪声。在这种情况下,上述两阶段过程变成一种更简单的方法,我们称之为半监督蒸馏(SSD)。首先,教师模型在未标记的数据集上推断伪标签,然后我们从中训练一个新的教师模型(T'),其大小等于或大于原始教师模型。这个步骤本质上是自我训练,然后进行知识蒸馏以生成一个较小的学生模型用于生产。
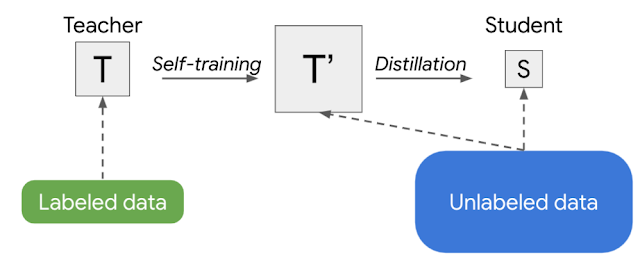
半监督蒸馏 (SSD) 的示意图,这是一个 2 阶段过程,在蒸馏为学生 (S) 之前,先自我训练一个等于或大于等于的老师 (T')。
改善搜索
在视觉领域取得成功后,谷歌搜索等语言理解领域的应用是合乎逻辑的下一步,它将对用户产生更广泛的影响。在这种情况下,我们专注于搜索中的一个重要排名组件,它基于BERT来更好地理解语言。事实证明,这项任务非常适合 SSD。事实上,将 SSD 应用于排名组件以更好地理解候选搜索结果与查询的相关性,在 2020 年搜索的顶级发布中取得了最高的性能提升之一。下面是一个查询示例,其中改进后的模型展示了更好的语言理解。
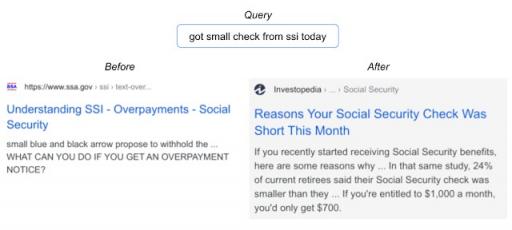
通过 SSD 的实现,搜索能够找到与用户查询更相关的文档。
未来的研究与挑战
我们在 Search 的生产规模环境中展示了半监督蒸馏 (SSD) 的成功实例。我们相信 SSD 将继续改变行业中机器学习的使用格局,从以监督学习为主转变为半监督学习。虽然我们的结果很有希望,但仍需要大量研究如何有效利用现实世界中通常充满噪声的未标记示例并将其应用于各个领域。
致谢
Zhenshuai Ding、Yanping Huang、Elizabeth Tucker、Hai Qian 和 Steve He 为此次成功发布做出了巨大贡献。如果没有 Brain 和 Search 团队的贡献,该项目不可能取得成功:Shuyuan Zhang、Rohan Anil、Zhifeng Chen、Rigel Swavely、Chris Waterson 和 Avinash Atreya。感谢 Qizhe Xie 和 Zihang Dai 对这项工作的反馈。还要感谢 Quoc Le、Yonghui Wu、Sundeep Tirumalareddy、Alexander Grushetsky 和 Pandu Nayak 的领导支持。
评论