自然图像合成是一类广泛的机器学习 (ML) 任务,具有广泛的应用,带来了许多设计挑战。一个例子是图像超分辨率,其中训练模型将低分辨率图像转换为详细的高分辨率图像(例如RAISR)。超分辨率有许多应用,从恢复旧的家庭肖像到改进医学成像系统。另一个这样的图像合成任务是类条件图像生成,其中训练模型从输入类标签生成样本图像。生成的样本图像可用于提高图像分类、分割等下游模型的性能。
通常,这些图像合成任务由深度生成模型(例如GAN、VAE和自回归模型)完成。然而,这些生成模型在训练用于在困难的高分辨率数据集上合成高质量样本时都有其缺点。例如,GAN 通常存在训练不稳定和模式崩溃的问题,而自回归模型通常存在合成速度慢的问题。
另外,扩散模型最初于 2015 年提出,由于其训练稳定性及其在图像 和 音频 生成方面的良好样本质量结果,最近重新引起了人们的兴趣。因此,与其他类型的深度生成模型相比,它们提供了潜在的有利权衡。扩散模型的工作原理是通过逐步添加高斯噪声来破坏训练数据,慢慢消除数据中的细节直到它变成纯噪声,然后训练神经网络来逆转这一破坏过程。运行这个逆破坏过程通过逐渐对纯噪声进行去噪直到产生干净的样本来合成数据。这个合成过程可以解释为一种优化算法,它遵循数据密度的梯度来产生可能的样本。
今天,我们介绍了两种相互关联的方法,它们突破了扩散模型图像合成质量的界限——通过重复细化实现的超分辨率(SR3) 和类条件合成模型,称为级联扩散模型(CDM)。我们表明,通过扩展扩散模型并采用精心挑选的数据增强技术,我们可以超越现有方法。具体来说,SR3 实现了强大的图像超分辨率结果,在人工评估中超越了 GAN。CDM 生成的高保真 ImageNet 样本在FID 分数和分类准确度分数上都大大 超越了BigGAN-deep和VQ-VAE2 。
SR3:图像超分辨率
SR3是一种超分辨率扩散模型,它将低分辨率图像作为输入,并从纯噪声中构建相应的高分辨率图像。该模型在图像损坏过程中进行训练,在此过程中,噪声逐渐添加到高分辨率图像中,直到只剩下纯噪声。然后,它学会逆转这个过程,从纯噪声开始,并通过输入的低分辨率图像的指导逐步消除噪声以达到目标分布。
通过大规模训练,SR3 在将分辨率缩放到输入低分辨率图像的 4 倍至 8 倍时,在人脸和自然图像的超分辨率任务上取得了强大的基准测试结果。这些超分辨率模型可以进一步级联在一起,以增加有效的超分辨率比例因子,例如,将 64x64 → 256x256 和 256x256 → 1024x1024 人脸超分辨率模型堆叠在一起,以执行 64x64 → 1024x1024 超分辨率任务。
我们使用人工评估研究将 SR3 与现有方法进行比较。我们进行了一项两选一强制选择实验,实验中,受试者被要求在参考高分辨率图像和模型输出之间进行选择,当被问到“您猜哪张图像来自相机? ”的问题时,我们通过混淆率(评分者选择模型输出而不是参考图像的时间百分比,其中完美的算法将实现 50% 的混淆率)来衡量模型的性能。这项研究的结果如下图所示。
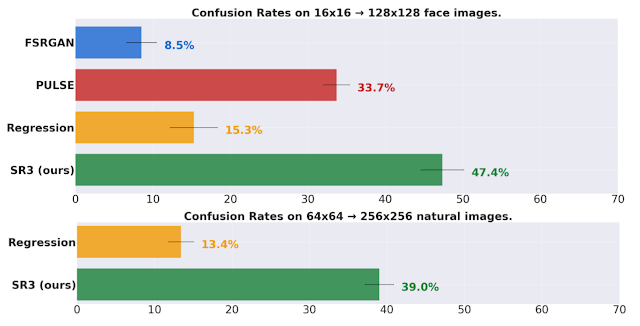
上图:我们在 16x16 → 128x128 人脸任务中实现了接近 50% 的混淆率,优于最先进的人脸超分辨率方法 PULSE 和 FSRGAN。下图:我们还在更困难的 64x64 → 256x256 自然图像任务中实现了 40% 的混淆率,大大超越了回归基线。
CDM:类条件 ImageNet 生成
在展示了 SR3 在执行自然图像超分辨率方面的有效性之后,我们更进一步,使用这些 SR3 模型进行类条件图像生成。CDM是一个在 ImageNet 数据上训练的类条件扩散模型,用于生成高分辨率自然图像。由于 ImageNet 是一个困难的高熵数据集,我们将 CDM 构建为多个扩散模型的级联。这种级联方法涉及将多个生成模型链接在一起,覆盖多个空间分辨率:一个扩散模型以低分辨率生成数据,然后是一系列 SR3 超分辨率扩散模型,这些模型逐渐将生成的图像的分辨率提高到最高分辨率。众所周知,级联可以提高高分辨率数据的质量和训练速度,正如先前的研究(例如在自回归模型和VQ-VAE-2中)以及扩散模型的并行 工作所示。正如我们下面的定量结果所示,CDM 进一步强调了扩散模型中级联对样本质量的有效性以及在下游任务(例如图像分类)中的实用性。

包含一系列扩散模型的级联管道示例:第一个生成低分辨率图像,其余执行上采样以生成最终的高分辨率图像。此处的管道用于类条件 ImageNet 生成,首先是 32x32 分辨率的类条件扩散模型,然后是使用 SR3 的 2x 和 4x 类条件超分辨率。

从我们的 256x256 级联类条件 ImageNet 模型中选择生成的图像。
除了将 SR3 模型纳入级联流水线外,我们还引入了一种新的数据增强技术,我们称之为条件增强,它进一步改善了 CDM 的样本质量结果。虽然 CDM 中的超分辨率模型是在数据集中的原始图像上训练的,但在生成过程中,它们需要对低分辨率基础模型生成的图像执行超分辨率,这些图像与原始图像相比可能质量不够高。这会导致超分辨率模型的训练-测试不匹配。条件增强是指对级联流水线中每个超分辨率模型的低分辨率输入图像应用数据增强。这些增强(在我们的例子中包括高斯噪声和高斯模糊)可防止每个超分辨率模型过度拟合其低分辨率条件输入,最终为 CDM 带来更好的高分辨率样本质量。
总而言之,CDM 生成的高保真样本在FID 分数和分类准确度分数 方面均优于 BigGAN-deep 和 VQ-VAE-2(在类条件 ImageNet 生成中)。与ADM和 VQ-VAE-2等其他模型不同,CDM 是一种纯生成模型,不使用分类器来提高样本质量。有关样本质量的定量结果,请参见下文。
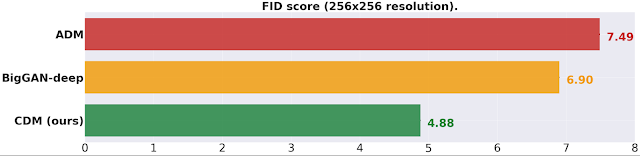
对于不使用额外分类器来提高样本质量的方法,类条件 ImageNet FID 在 256x256 分辨率下的得分。BigGAN-deep 报告了其最佳截断值。(越低越好。)
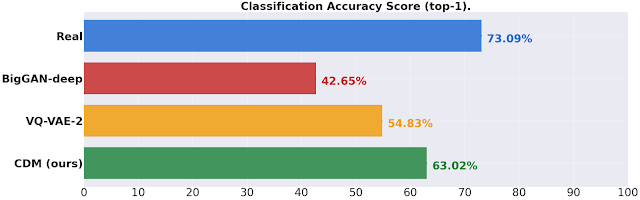
ImageNet 分类准确度得分在 256x256 分辨率下,衡量在生成数据上训练的分类器的验证集准确度。CDM 生成的数据比现有方法取得了显著的进步,缩小了真实数据和生成数据之间的分类准确度差距。(越高越好。)
结论
借助 SR3 和 CDM,我们在超分辨率和类条件 ImageNet 生成基准上将扩散模型的性能推向了最先进的水平。我们很高兴能够进一步测试扩散模型在各种生成建模问题中的极限。有关我们工作的更多信息,请访问通过迭代细化实现图像超分辨率和用于高保真图像生成的级联扩散模型。
致谢
我们感谢合著者 William Chan、Mohammad Norouzi、Tim Salimans 和 David Fleet,也感谢 Ben Poole、Jascha Sohl-Dickstein、Doug Eck 和 Google Research Brain Team 其他成员的研究讨论和协助。感谢 Tom Small 帮助我们制作动画。
评论