Google Quantum AI团队一直在构建由超导量子比特 ( qubits ) 制成的量子处理器,这些处理器已实现首次超经典计算,以及迄今为止最大的量子化学模拟。然而,当前一代量子处理器的运算错误率仍然很高——在每次运算 10 -3的范围内,而据信各种有用算法所需的错误率为 10 -12。弥补这一巨大的错误率差距需要的不仅仅是制造更好的量子比特——未来的量子计算机必须使用量子纠错(QEC)。
QEC 的核心思想是通过将量子态分布在许多物理数据量子位上来构造逻辑量子位。当发生物理错误时,可以通过反复检查量子位的某些属性来检测它,从而对其进行纠正,防止逻辑量子位状态发生任何错误。虽然如果一系列物理量子位同时出现错误,仍然可能会发生逻辑错误,但随着更多物理量子位的增加(需要涉及更多物理量子位才能导致逻辑错误),该错误率应该呈指数下降。这种指数级扩展行为依赖于物理量子位错误足够罕见且独立。特别是,抑制相关错误非常重要,其中一个物理错误会同时影响许多量子位,或者在许多错误纠正周期中持续存在。这种相关错误会产生更复杂的错误检测模式,更难以纠正,也更容易导致逻辑错误。
我们的团队最近使用量子重复代码 在我们的 Sycamore 架构中实现了 QEC 的理念。这些代码由一维量子比特链组成,这些量子比特在数据量子比特(对逻辑量子比特进行编码)和测量量子比特(我们用后者来检测逻辑状态中的错误)之间交替。虽然这些重复代码一次只能纠正一种量子错误1 ,但它们包含与更复杂的纠错码相同的所有成分,并且每个逻辑量子比特需要更少的物理量子比特,这使我们能够更好地探索逻辑错误如何随着逻辑量子比特大小的增加而减少。
在《自然通讯》上发表的 《超导量子纠错中消除泄漏引起的相关误差》中,我们使用这些重复代码展示了一种减少物理量子比特中相关误差数量的新技术。然后,在《利用重复纠错对位或相位翻转误差进行指数抑制》中,我们表明,随着我们添加越来越多的物理量子比特,这些重复代码的逻辑错误会呈指数级抑制,这与 QEC 理论的预期一致。
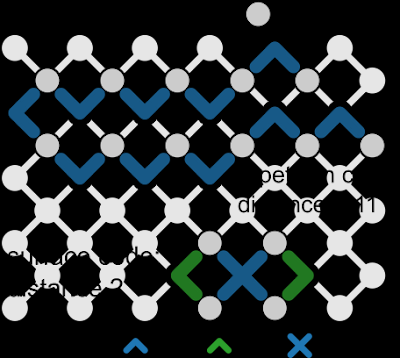
Sycamore 设备上重复代码(21 个量子比特,1D 链)和距离为 2 的表面代码(7 个量子比特)的布局。
泄漏的量子比特
重复代码的目的是检测数据量子比特上的错误,而无需直接测量它们的状态。它通过将每对数据量子比特与其共享的测量量子比特纠缠在一起来实现这一点,这种方式告诉我们这些数据量子比特的状态是相同还是不同(即它们的奇偶性),而无需告诉我们状态本身。我们在仅持续一微秒的回合中一遍又一遍地重复此过程。当测量的奇偶性在回合之间发生变化时,我们就检测到了错误。
然而,一个关键挑战来自于我们如何用超导电路制造量子比特。虽然一个量子比特只需要两个能态,通常被标记为|0⟩和|1⟩我们的设备具有能量状态阶梯,|0⟩,|1⟩,|2⟩,|3⟩等等。我们使用两个最低能量状态来编码我们的量子比特,其中包含用于计算的信息(我们称之为计算状态)。我们使用较高的能量状态(|2⟩,|3⟩及更高级别)来帮助实现高保真纠缠运算,但这些纠缠运算有时会允许量子比特“泄漏”到这些更高状态,因此被称为泄漏状态。
随着操作的实施,泄漏状态的数量不断增加,这会增加后续操作的错误,甚至会导致其他附近的量子比特也泄漏,从而产生一个特别具有挑战性的相关误差源。在2015年初的纠错实验中,我们观察到,随着错误纠正的轮次增多,性能会随着泄漏的增加而下降。
为了减轻泄漏的影响,我们需要开发一种新的量子比特操作,可以“清空”泄漏状态,称为多级重置。我们操纵量子比特,将能量快速泵入用于读出的结构中,在那里能量将快速移出芯片,使量子比特冷却到|0⟩州,即使它始于|2⟩或者|3⟩。将此操作应用于数据量子位会破坏我们试图保护的逻辑状态,但我们可以将其应用于测量量子位而不会干扰数据量子位。在每一轮结束时重置测量量子位可以动态稳定设备,因此泄漏不会继续增长和扩散,从而使我们的设备表现得更像理想量子位。
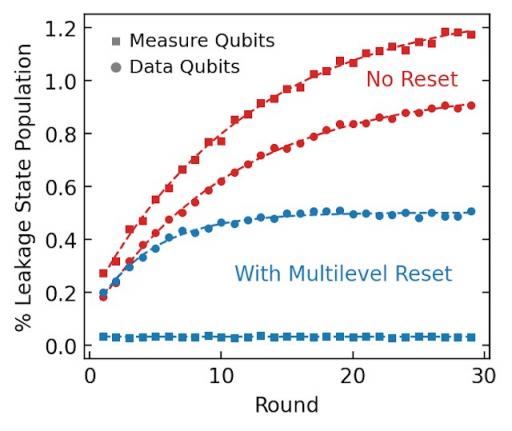
将多级复位门应用于测量量子位几乎完全消除了泄漏,同时也减少了数据量子位上泄漏的增长。
指数抑制
减轻了泄漏这个重要相关误差源的影响后,我们接下来着手测试重复代码是否能在增加量子比特数量时给我们带来预测的误差指数减少。每次我们运行重复代码时,它都会产生一组错误检测。由于检测与量子比特对而不是单个量子比特相关联,我们必须查看所有检测以尝试拼凑出错误发生的位置,这个过程称为解码。一旦我们解码了错误,我们就知道需要对数据量子比特应用哪些更正。但是,如果错误检测的数量超过所使用的数据量子比特数量,则解码可能会失败,从而导致逻辑错误。
为了测试我们的重复代码,我们运行大小从 5 到 21 个量子比特的代码,同时改变纠错轮数。我们还运行两种不同类型的重复代码——相位翻转代码或位翻转代码——它们对不同类型的量子错误敏感。通过找到逻辑错误概率与轮数的关系,我们可以为每种代码大小和代码类型拟合一个逻辑错误率。在我们的数据中,我们看到随着代码大小的增加,逻辑错误率确实会呈指数级下降。
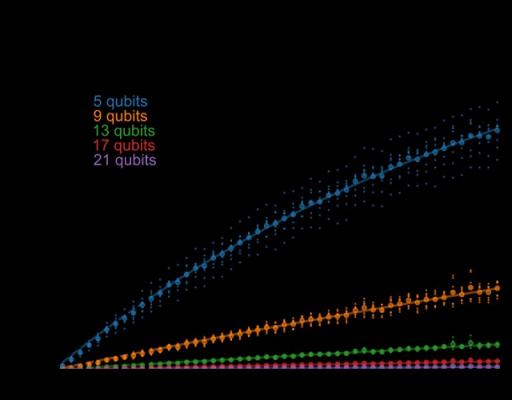
解码后出现逻辑错误的概率与运行轮数的关系,显示不同大小的相位翻转重复码。
我们可以用误差缩放参数 Lambda (Λ) 来量化误差抑制,其中 Lambda 值为 2 意味着每次我们在重复代码中添加四个数据量子位时,逻辑错误率就会减半。在我们的实验中,我们发现相位翻转代码的 Lambda 值为 3.18,位翻转代码的 Lambda 值为 2.99。我们可以将这些实验值与基于没有相关误差的简单误差模型的预期 Lambda 的数值模拟进行比较,该模型预测位翻转代码和相位翻转代码的 Lambda 值为 3.34 和 3.78。
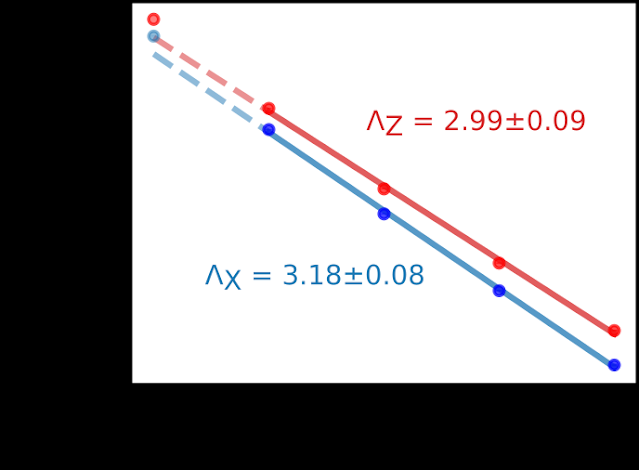
相位翻转 (X) 和位翻转 (Z) 重复代码的每轮逻辑错误率与量子比特数的关系。该线显示指数衰减拟合,Λ 是指数衰减的比例因子。
这是首次在任何平台上测量 Lambda,同时进行多轮错误检测。我们对实验和模拟的 Lambda 值如此接近感到特别兴奋,因为这意味着我们的系统可以用一个相当简单的错误模型来描述,而不会发生许多意外错误。然而,一致性并不完美,这表明在理解我们的 QEC 架构的非理想性方面还有更多的研究要做,包括额外的相关错误来源。
下一步
这项工作证明了 QEC 的两个重要先决条件:首先,得益于我们新的重置协议,Sycamore 设备可以运行多轮纠错,而不会随着时间的推移累积错误;其次,我们能够通过展示重复代码中错误的指数抑制来验证 QEC 理论和错误模型。这些实验是迄今为止 QEC 系统的最大压力测试,在我们最大的测试中使用了 1000 个纠缠门和 500 个量子比特测量。我们期待从这些实验中学到的知识并将其应用于我们的目标 QEC 架构,即 2D 表面代码,这将需要更多的量子比特和更好的性能。
评论