图像和视频编辑操作通常依赖于精确的遮罩——定义前景和背景之间分离的图像。虽然最近的计算机视觉技术可以为自然图像和视频生成高质量的遮罩,从而实现现实世界中的应用,例如生成合成景深、编辑和合成图像或从图像中去除背景,但缺少一个基本要素:主体可能产生的各种场景效果,如阴影、反射或烟雾,通常被忽视。
在CVPR 2021上发表的 “ Omnimatte:将视频中的对象及其效果关联起来”中,我们描述了一种新的遮罩生成方法,该方法利用分层神经渲染将视频分成称为Omnimatte 的层,这些层不仅包括主体,还包括场景中与主体相关的所有效果。典型的最先进分割模型会提取场景中主体(例如人和狗)的遮罩,而此处提出的方法可以隔离和提取与主体相关的其他细节,例如投射在地面上的阴影。

最先进的分割网络(例如MaskRCNN)接收输入视频(左图)并为人物和动物生成可信的蒙版(中图),但却忽略了相关效果。我们的方法生成的遮罩不仅包括主体,还包括其阴影(右图;人物和狗的单独通道可视化为蓝色和绿色)。
此外,与分割蒙版不同的是,全向蒙版可以捕捉半透明的柔和效果,例如反射、飞溅或轮胎烟雾。与传统蒙版一样,全向蒙版是RGBA 图像,可以使用广泛使用的图像或视频编辑工具进行操作,并且可以在任何使用传统蒙版的地方使用,例如,在视频中烟雾轨迹下方插入文本。

视频分层分解
为了生成全景图,我们将输入视频分成一组图层:每个移动主体一个图层,静止背景物体一个附加图层。在下面的示例中,人有一层,狗有一层,背景有一层。使用传统的alpha 混合将这些图层合并在一起时,它们会重现输入视频。

除了重现视频之外,分解还必须捕捉每个图层中的正确效果。例如,如果人的影子出现在狗的图层中,合并的图层仍会重现输入视频,但在人和狗之间插入额外的元素会产生明显的错误。挑战在于找到一种分解,让每个主体的图层只捕捉该主体的效果,从而产生真正的全向效果。
我们的解决方案是应用我们之前开发的分层神经渲染方法来训练卷积神经网络(CNN),将主体的分割蒙版和背景噪声图像映射到全向遮罩中。由于其结构,CNN 自然倾向于学习图像效果之间的相关性,并且效果之间的相关性越强,CNN 就越容易学习。例如,在上面的视频中,当他们从右向左行走时,人与影子、狗与影子之间的空间关系保持相似。人与狗的影子或狗与人的影子之间的关系变化较大(因此相关性较弱) 。CNN 首先学习较强的相关性,从而得出正确的分解。
下面详细显示了 omnimatte 系统。在预处理中,用户选择主体并为每个主体指定一个图层。使用现成的分割网络(例如MaskRCNN )提取每个主体的分割蒙版,并使用标准相机稳定工具找到相对于背景的相机变换。在背景参考帧中定义随机噪声图像,并使用相机变换进行采样以生成每帧噪声图像。噪声图像提供随机但随时间持续跟踪背景的图像特征,为 CNN 提供自然输入以学习重建背景颜色。
渲染 CNN 将分割蒙版和每帧噪声图像作为输入,并生成 RGB 彩色图像和 alpha 图,以捕获每个层的透明度。这些输出使用传统的 alpha 混合合并以生成输出帧。CNN 从头开始训练,通过查找蒙版中未捕获的效果(例如阴影、反射或烟雾)并将其与给定的前景层关联来重建输入帧,并确保主体的 alpha 大致包含分割蒙版。为了确保前景层仅捕获前景元素而不捕获任何静止背景,还对前景 alpha 施加了稀疏性损失。
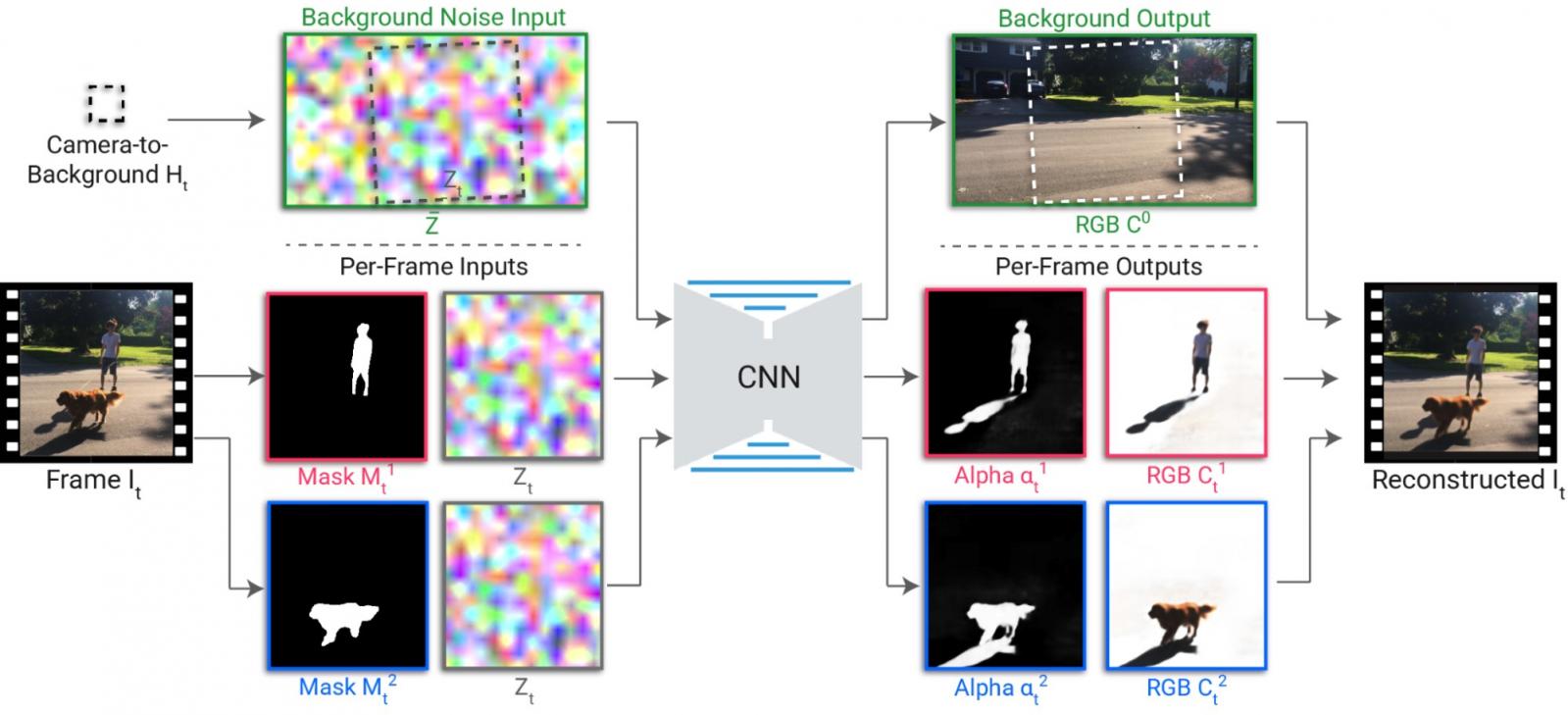
为每个视频训练一个新的渲染网络。由于网络只需要重建单个输入视频,因此除了分离每个主体的效果之外,它还能够捕捉精细结构和快速运动,如下所示。在步行示例中,全向遮挡包括投射在公园长椅板条上的阴影。在网球示例中,捕捉到了细小的阴影甚至网球。在足球示例中,球员和球的阴影被分解成适当的层(当球员的脚被球遮挡时会出现轻微错误)。

这个基本模型已经运行良好,但可以通过使用额外的缓冲区(例如光流或纹理坐标)增强 CNN 的输入来 改善结果。
应用
一旦生成了全景图,它们该如何使用呢?如上所示,我们可以移除对象,只需从合成中删除它们的图层即可。我们还可以复制对象,通过在合成中重复它们的图层即可。在下面的示例中,视频被“展开”为全景图,并且马被复制了几次以产生频闪照片效果。请注意,马在地面和障碍物上投射的阴影被正确捕捉到了。

一个更微妙但更强大的应用是重新定时拍摄主题。时间操纵在电影中被广泛使用,但通常需要为每个主题拍摄单独的镜头并控制拍摄环境。分解为全向蒙版使得仅使用后期处理即可对日常视频进行重新定时效果,只需通过独立更改每个层的播放速率即可。由于全向蒙版是标准 RGBA 图像,因此可以使用常规视频编辑软件进行这种重新定时编辑。
下面的视频被分解成三个图层,每个孩子一个。孩子们最初不同步的跳跃通过简单调整图层的播放速率来对齐,从而为水中的溅水和反射产生逼真的重定时效果。

原始视频(左)中,每个孩子跳跃的时间都不同。经过剪辑(右)后,大家一起跳跃。
重要的是要考虑到,任何新颖的图像处理技术都应负责任地开发和应用,因为它可能会被滥用来产生虚假或误导性信息。我们的技术是根据我们的人工智能原则开发的,只允许重新排列视频中已经存在的内容,但即使是简单的重新排列也会显著改变视频的效果,如这些示例所示。研究人员应该意识到这些风险。
未来工作
有许多令人兴奋的方向可以提高全景图的质量。在实践层面上,该系统目前仅支持可以建模为全景图的背景,其中相机的位置是固定的。当相机位置移动时,全景模型无法准确捕捉整个背景,并且一些背景元素可能会扰乱前景层(有时在上图中可见)。处理完全一般的相机运动,例如穿过房间或沿着街道行走,需要 3D 背景模型。在存在移动物体和效果的情况下重建 3D 场景仍然是一项艰巨的研究挑战,但最近取得了令人鼓舞的进展。
从理论层面来看,CNN 学习相关性的能力非常强大,但仍然有些神秘,并且并不总是能够实现预期的层分解。虽然我们的系统允许在自动结果不完美时进行手动编辑,但更好的解决方案是充分了解 CNN 学习图像相关性的能力和局限性。除了层分解之外,这样的理解还可以改进去噪、修复和许多其他视频编辑应用。
致谢
牛津大学的 Erika Lu 在谷歌两次实习期间与谷歌研究人员 Forrester Cole、Tali Dekel、Michael Rubinstein、William T. Freeman 和 David Salesin 以及牛津大学研究人员 Weidi Xie 和 Andrew Zisserman 合作开发了 omnimatte 系统。
感谢同意出现在示例视频中的作者朋友和家人。“horse jump low”、“lucia”和“tennis”视频来自DAVIS 2016 数据集。足球视频经Online Soccer Skills许可使用。汽车漂移视频由 Shutterstock 授权。
评论