近年来,人们对将深度学习应用于医学成像任务的兴趣日益浓厚,并在放射学、病理学和皮肤病学等各种应用方面取得了令人振奋的进展。尽管人们对它感兴趣,但开发医学成像模型仍然具有挑战性,因为由于注释医学图像需要耗费大量时间,因此高质量标记数据通常很少。鉴于此,迁移学习是构建医学成像模型的一种流行范例。通过这种方法,首先使用监督学习在大型标记数据集(如ImageNet )上对模型进行预训练,然后在领域内医学数据上对学习到的通用表示进行微调。
其他较新的方法已被证明在自然图像识别任务中取得成功,尤其是在标记示例稀缺的情况下,它们使用自监督对比预训练,然后进行监督微调(例如SimCLR和MoCo )。在使用对比学习的预训练中,通过同时最大化同一图像的不同变换视图之间的一致性并最小化不同图像的变换视图之间的一致性来学习通用表示。尽管这些对比学习方法取得了成功,但它们在医学图像分析中受到的关注有限,其有效性尚待探索。
在即将于国际计算机视觉会议(ICCV 2021)上发表的 “大型自监督模型推动医学图像分类”中,我们研究了自监督对比学习作为医学图像分类领域预训练策略的有效性。我们还提出了多实例对比学习 (MICLe),这是一种新颖的方法,它将对比学习推广到利用医学图像数据集的特殊特征。我们对两个不同的医学图像分类任务进行了实验:从数码相机图像 (27 个类别) 进行皮肤病分类和多标签胸部 X 光分类 (5 个类别)。我们观察到,在 ImageNet 上进行自监督学习,然后在未标记的特定领域医学图像上进行额外的自监督学习,可以显著提高医学图像分类器的准确性。具体而言,我们证明,即使使用完整的 ImageNet 数据集 (14M 张图像和 21.8K 个类别) 进行监督预训练,自监督预训练的表现也优于监督预训练。
SimCLR 和多实例对比学习 (MICLe)
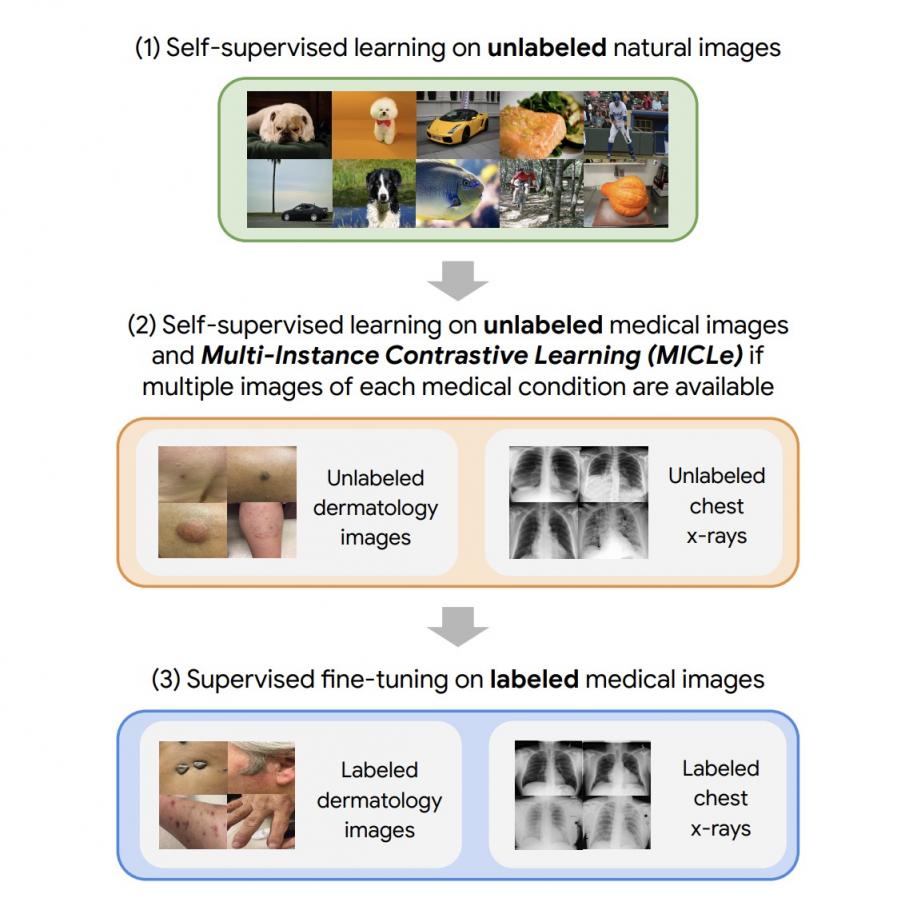
我们的方法包括三个步骤:(1)对未标记的自然图像进行自监督预训练(使用 SimCLR);(2)使用未标记的医疗数据进行进一步的自监督预训练(使用 SimCLR 或 MICLe);然后(3)使用标记的医疗数据进行特定于任务的监督微调。
我们的方法包括三个步骤:(1) 使用SimCLR在未标记的 ImageNet 上进行自监督预训练(2) 使用未标记的医学图像进行额外的自监督预训练。如果每种医疗状况都有多张图像,则使用新颖的多实例对比学习 (MICLe) 策略根据不同的图像构建更具信息量的正对。(3) 在标记的医学图像上进行监督微调。请注意,与步骤 (1) 不同,步骤 (2) 和 (3) 是特定于任务和数据集的。
使用 SimCLR 对未标记的自然图像进行初始预训练后,我们会训练模型以捕捉医学图像数据集的特殊特征。这也可以使用 SimCLR 完成,但此方法仅通过增强来构建正例对,无法轻松利用患者的元数据来构建正例对。或者,我们使用 MICLe,它会在可用时使用每个患者病例的多个潜在病理图像来构建更具信息量的正例对,以进行自监督学习。此类多实例数据通常存在于医学成像数据集中 - 例如乳房 X 光检查的正面和侧面视图、每只眼睛的视网膜眼底图像等。
给定一个给定病例的多张图像,MICLe 通过从同一病例的两个不同图像中抽取两张裁剪图像,为自监督对比学习构建一个正对。这些图像可能从不同的视角拍摄,并显示具有相同潜在病理的不同身体部位。这为自监督学习算法提供了一个很好的机会,可以直接学习对视点、成像条件和其他混杂因素的变化具有鲁棒性的表示。MICLe 不需要类别标签信息,只依赖于潜在病理的不同图像,其类型可能未知。
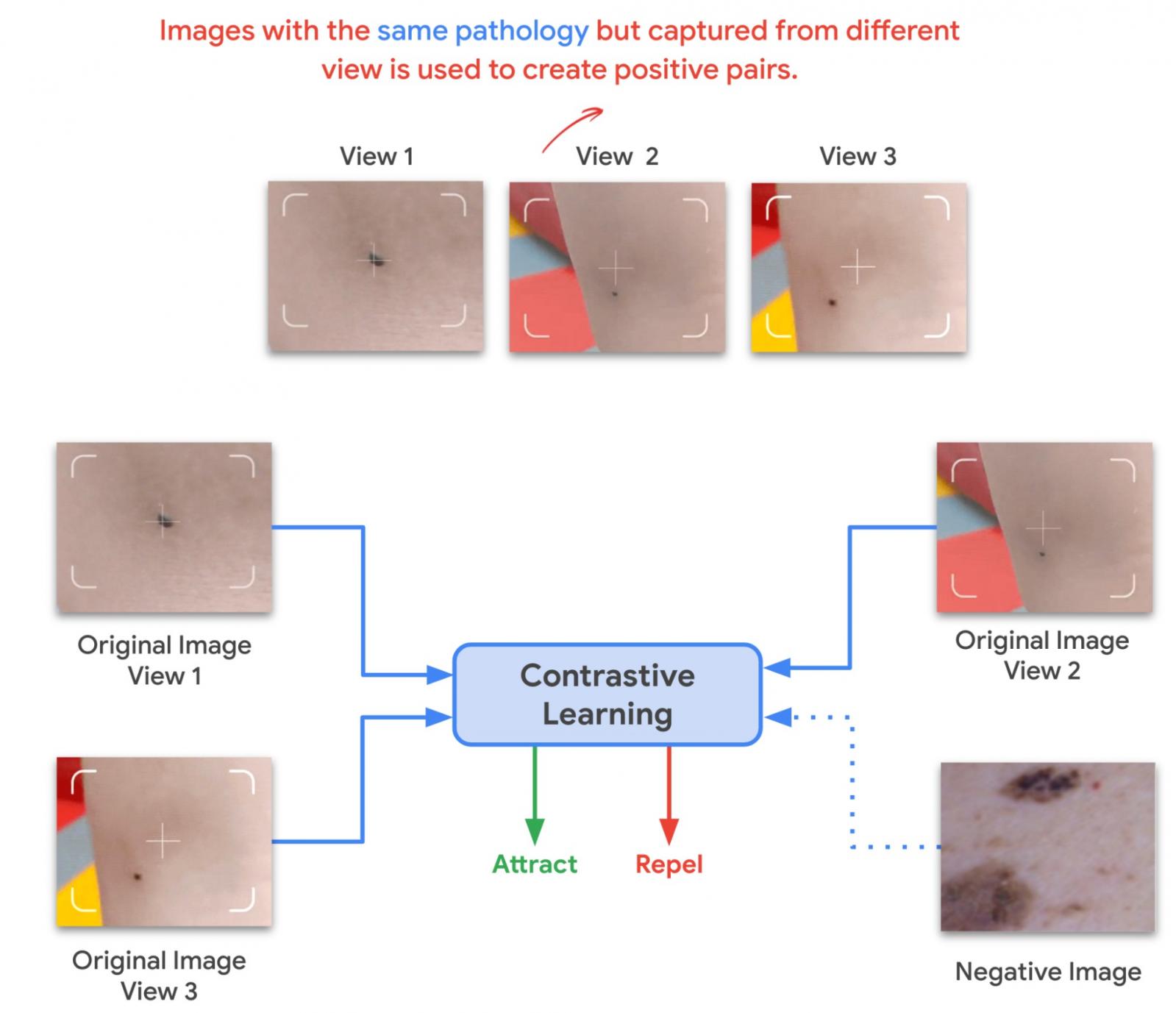
MICLe 推广对比学习,利用医学图像数据集(患者元数据)的特殊特征来创建真实的增强,从而进一步提高图像分类器的性能。
结合这些自监督学习策略,我们表明,即使在竞争激烈的生产环境中,我们也可以在皮肤病分类的 top-1 准确率上实现 6.7% 的大幅提升,在胸部 X 光片分类的平均 AUC上实现 1.1% 的改善,优于在 ImageNet(训练医学图像分析模型的主流协议)上预先训练的强监督基线。此外,我们表明,自监督模型对分布偏移具有鲁棒性,并且仅使用少量标记的医学图像即可有效学习。
监督和自监督预训练的比较
尽管方法简单,但我们观察到,在不同的预训练数据集和基础网络架构选择下,使用 MICLe 进行预训练比使用 SimCLR 进行预训练的原始方法能持续提高皮肤病学分类的性能。与使用 SimCLR 相比,使用 MICLe 进行预训练可将皮肤病学分类的 top-1 准确率提高 (1.18 ± 0.09)%。结果证明了利用额外的元数据或领域知识为对比预训练构建更具语义意义的增强所带来的好处。此外,我们的结果表明,更宽更深的模型可带来更大的性能提升,其中 ResNet-152(2 倍宽度)模型通常优于 ResNet-50(1 倍宽度)模型或更小的模型。
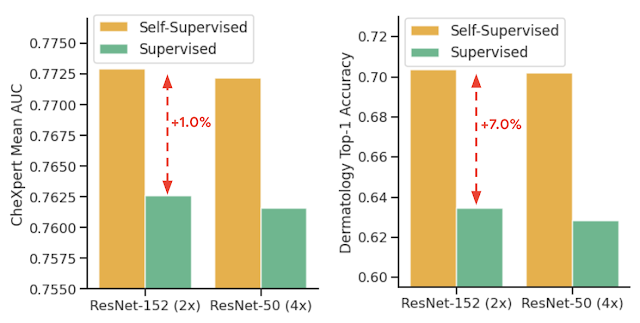
比较监督和自监督预训练,然后使用两种架构对皮肤病学和胸部 X 光分类进行监督微调。自监督学习利用未标记的特定领域医学图像,其表现明显优于监督 ImageNet 预训练。
使用自监督模型提高泛化能力
对于每项任务,我们分别使用域内未标记和标记数据进行预训练和微调。我们还使用在不同临床环境中获得的另一个数据集作为移位数据集,以进一步评估我们的方法对域外数据的稳健性。对于胸部 X 光检查任务,我们注意到使用 ImageNet 或CheXpert数据进行自监督预训练可以提高泛化能力,但将它们叠加在一起可以进一步提高泛化能力。正如预期的那样,我们还注意到,当仅使用 ImageNet 进行自监督预训练时,与仅使用域内数据进行预训练相比,该模型的表现更差。
为了测试分布偏移下的性能,对于每项任务,我们都保留了在不同临床环境下收集的额外标记数据集进行测试。我们发现,使用自监督预训练(使用 ImageNet 和 CheXpert 数据)在分布偏移数据集 ( ChestX-ray14 ) 上的性能提升比在 CheXpert 数据集上的原始提升更为明显。这是一个很有价值的发现,因为分布偏移下的泛化对临床应用至关重要。在皮肤病学任务中,我们观察到在皮肤癌诊所收集的单独偏移数据集的类似趋势,该数据集的恶性疾病患病率更高。这表明自监督表示对分布偏移的稳健性在各个任务中是一致的。
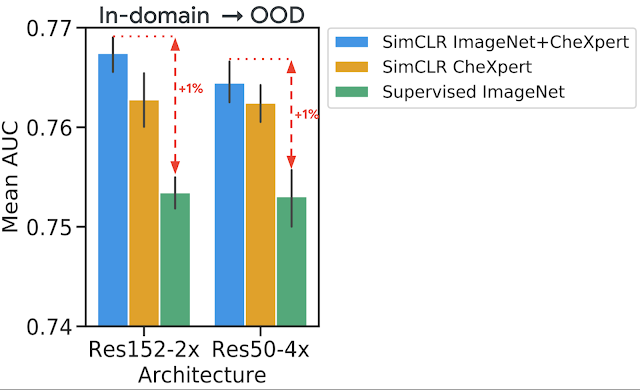
胸部 X 光片解读任务中分布偏移数据集上的模型评估。我们使用在域内数据上训练的模型对额外的偏移数据集进行预测,而无需进一步微调(零样本迁移学习)。我们观察到,自监督预训练可以产生更好的表征,这些表征对分布偏移更具鲁棒性。
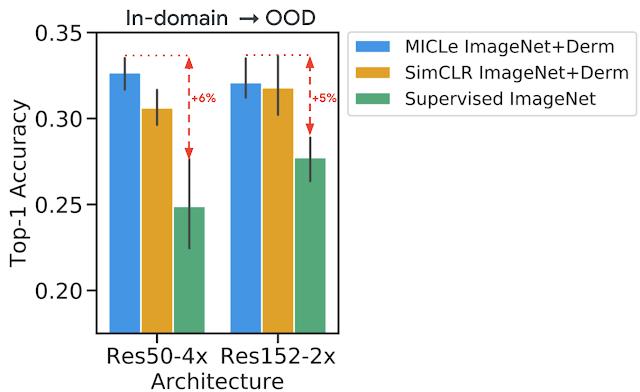
对皮肤病学任务中分布偏移数据集上的模型进行评估。我们的结果通常表明,自监督预训练模型可以更好地推广到分布偏移,其中 MICLe 预训练可带来最大的收益。
提高标签效率
我们通过在不同标记训练数据部分上对模型进行微调,进一步研究了用于医学图像分类的自监督模型的标记效率。我们对 Derm 和 CheXpert 训练数据集使用从 10% 到 90% 的标签分数,并检查使用皮肤病学任务的不同可用标签分数时性能如何变化。首先,我们观察到使用自监督模型进行预训练可以弥补医学图像分类的低标签效率,并且在采样的标签分数中,自监督模型的表现始终优于监督基线。这些结果还表明,当使用较少的标记示例进行微调时,MICLe 会按比例获得更高的收益。事实上,MICLe 仅使用 ResNet-50 的 20% 训练数据(4 倍)和 ResNet152 的 30% 训练数据(2 倍)就能匹配基线。
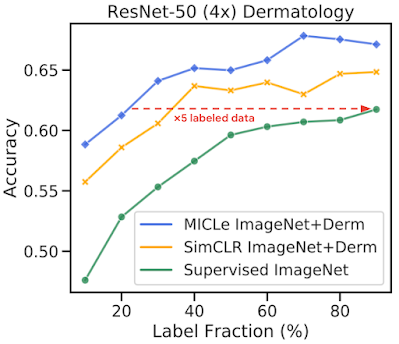
在不同的未标记预训练数据集和不同大小的标签分数下,MICLe、SimCLR 和监督模型的皮肤病分类达到 Top-1 准确率。MICLe 仅使用 ResNet-50(4 倍)的 20% 训练数据即可匹配基线。
结论
在自然图像数据集上进行监督预训练通常用于改进医学图像分类。我们研究了一种基于对未标记的自然和医学图像进行自我监督预训练的替代策略,发现它可以显著改善监督预训练,这是训练医学图像分析模型的标准范例。这种方法可以产生更准确、标签效率更高、对分布变化具有鲁棒性的模型。此外,我们提出的多实例对比学习方法 (MICLe) 允许使用额外的元数据来创建逼真的增强,从而进一步提高图像分类器的性能。
自监督预训练比监督预训练更具可扩展性,因为不需要类标签注释。我们希望本文有助于推广自监督方法在医学图像分析中的应用,从而产生适合在现实世界中大规模临床部署的标签高效且稳健的模型。
致谢
这项工作凝聚了 Google Health 和 Google Brain 研究人员、软件工程师、临床医生和跨职能贡献者组成的多学科团队的通力合作。我们感谢我们的合著者:Basil Mustafa、Fiona Ryan、Zach Beaver、Jan Freyberg、Jon Deaton、Aaron Loh、Alan Karthikesalingam、Simon Kornblith、Ting Chen、Vivek Natarajan 和 Mohammad Norouzi。我们还要感谢 Google Health 的 Yuan Liu 提供的宝贵反馈,以及我们的合作伙伴允许访问研究中使用的数据集。
评论