在过去 20 个月中,COVID-19 疫情对日常生活产生了深远影响,给企业规划供需带来了物流挑战,也给政府和组织在及时应对公共卫生问题方面提供支持带来了困难。虽然已经有经过充分研究的流行病学模型可以帮助预测 COVID-19 病例和死亡人数,以应对这些挑战,但这次疫情产生了前所未有的大量实时公开数据,这使得使用更先进的机器学习技术来改善结果成为可能。
在被npj Digital Medicine接受的 “对 AI 增强流行病学预测美国和日本 COVID-19 的前瞻性评估”中,我们继续了之前的工作 [ 1、2、3、4 ],并提出了一个框架,旨在仅使用公开数据模拟某些政策变化对 COVID-19 死亡和病例的影响,例如美国州、美国县和日本都道府县级别的学校关闭或紧急状态。我们对公开预测进行了为期 2 个月的前瞻性评估,在此期间,我们的美国模型与COVID19 预测中心上的所有其他 33 个模型持平或优于其他模型。我们还发布了对美国和日本受保护子群体的表现的公平性分析。与 Google 为应对 COVID-19 而采取的其他举措 [ 1、2、3 ] 一样,我们每天都会通过网络 [美国、日本] 和BigQuery免费向公众发布基于这项工作的预测。
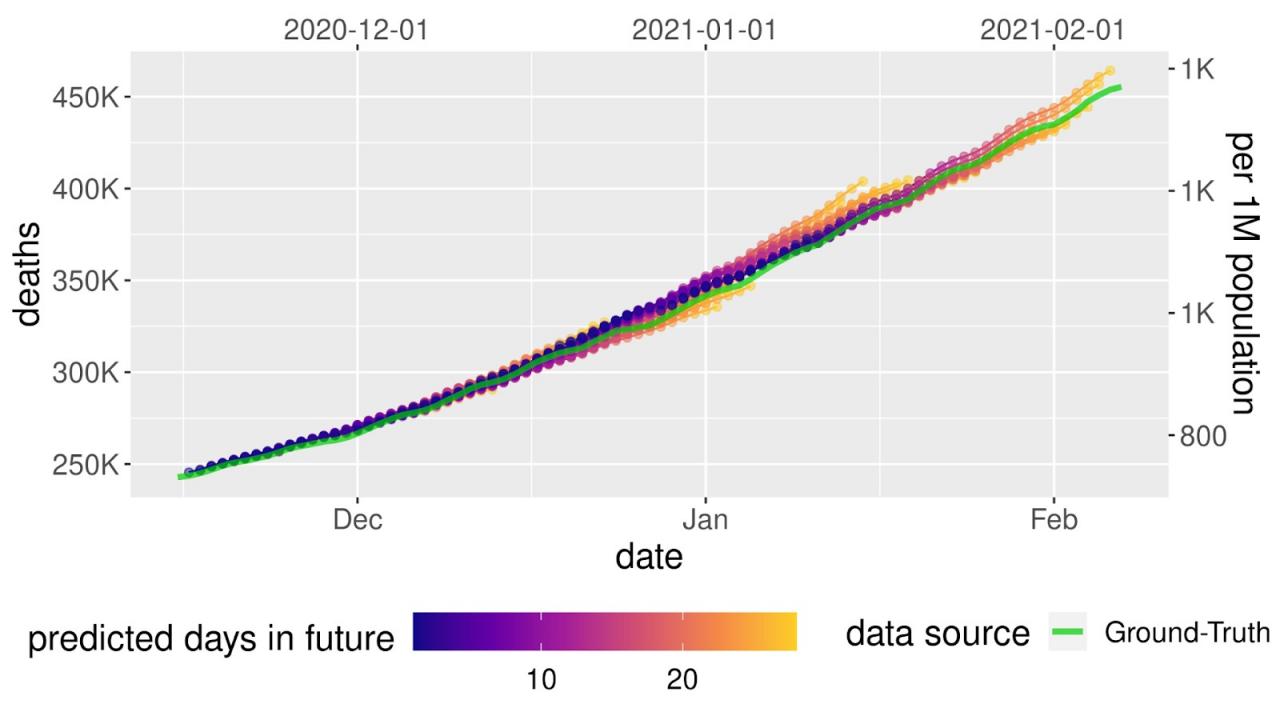
美国和日本模型的前瞻性预测。每日预测旁边显示了实际累计死亡人数(绿线)。每日预测包含 4 周预测窗口期内每天死亡人数的预测增长(显示为彩色圆点,其中阴影变为黄色表示在预测期内距离预测日期还有几天,最多 4 周)。图中显示了美国(左)和日本(右)的死亡人数预测。
模型
流行病学家 研究传染病模型已有数十年。隔室模型最为常见,因为它们简单、可解释,并且能够有效适应不同的疾病阶段。在隔室模型中,个体根据其疾病状态(例如易感、暴露或康复)被分成互斥的组或隔室,并对这些隔室之间的变化率进行建模以适应过去的数据。人群被分配到代表疾病状态的隔室中,随着疾病状态的变化,人们在各个状态之间流动。
在本研究中,我们提出了一些对易感-暴露-感染-移除(SEIR) 型隔室模型的扩展。例如,易感人群暴露会导致易感隔室减少,暴露隔室增加,其速率取决于疾病传播特征。COVID-19 相关结果(例如确诊病例、住院和死亡)的观察数据用于训练隔室模型。
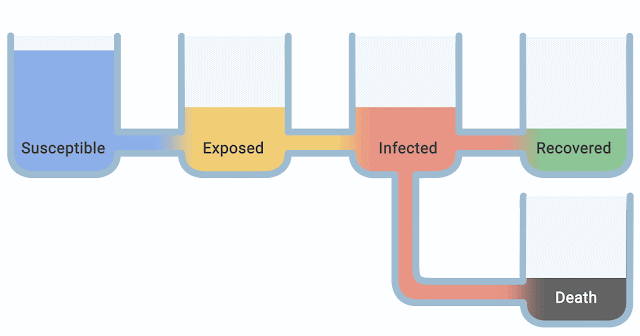
流行病学中“隔室”模型的视觉解释。人们在隔室之间“流动”。现实世界中的事件,如政策变化和更多的 ICU 床位,会改变隔室之间的流动率。
我们的框架提出了许多新颖的技术创新:
学习到的转换率:我们不是使用静态转换率来映射所有位置和时间的隔间转换,而是使用机器学习的转换率来映射它们。这使我们能够利用大量具有信息信号的可用数据,例如 Google 的 COVID-19社区流动报告、医疗保健供应、人口统计和计量经济学特征。
可解释性:我们的框架为决策者提供了可解释性,通过其隔室结构提供有关疾病传播趋势的见解,并提出哪些因素对于推动隔室转变可能最重要。
扩展隔间:我们增加了住院、ICU、呼吸机和疫苗隔间,并展示了尽管数据稀疏但仍能实现高效的训练。
跨地点共享信息:与适应单个位置相反,我们对一个国家(例如,超过 3000 个美国县)的所有位置都有一个单一模型,具有不同的动态和特征,并且我们展示了跨地点传输信息的好处。
Seq2seq 建模:我们使用序列到序列模型和新颖的部分教师强制方法,最大限度地减少未来错误的放大增长。
预测准确度
我们每天都会训练模型来预测未来 28 天的 COVID-19 相关结果(主要是死亡和病例)。我们报告全国范围得分和地点级别得分的 平均绝对百分比误差(MAPE),以及 COVID-19 相关结果的累积值和每周增量值。
我们将我们的框架与COVID19 预测中心 针对美国的替代方案进行了比较。在 MAPE 中,我们的模型优于除一个模型之外的所有其他 33 个模型——集合预测也包括我们模型的预测,其中差异在统计上并不显着。
我们还利用预测不确定性来估计预测是否准确。如果我们拒绝模型认为不确定的预测,我们就可以提高我们发布的预测的准确性。这是可能的,因为我们的模型具有经过良好校准的不确定性。
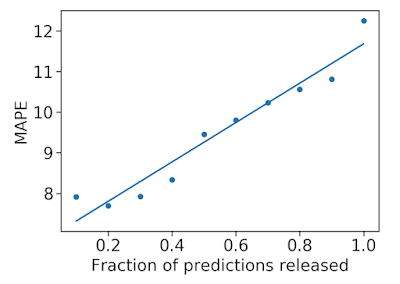
随着我们消除不确定的预测,平均百分比误差 (MAPE,越低越好) 会降低,从而提高准确性。
模拟疫情管理政策和策略的假设工具
除了根据过去的数据了解最可能的情况外,决策者还对不同的决策如何影响未来结果感兴趣,例如了解学校停课、流动限制和不同疫苗接种策略的影响。我们的框架允许进行反事实分析,方法是将选定变量的预测值替换为反事实值。我们的模拟结果强调了过早放松非药物干预措施 (NPI) 的风险,直到疾病的快速传播得到减缓。同样,日本的模拟表明,在疫苗接种率高的情况下维持紧急状态可大大降低感染率。
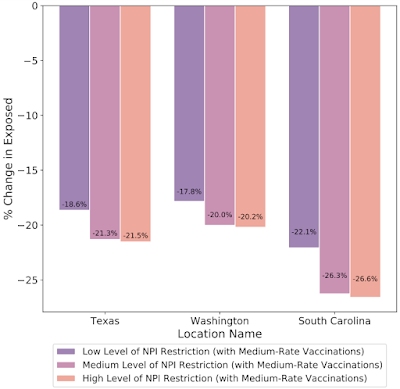
假设在预测日期 2021 年 3 月 1 日,德克萨斯州、华盛顿州和南卡罗来纳州采取不同的非药物干预措施 (NPI),对预计暴露人数的百分比变化进行假设模拟。NPI 限制的加强与暴露人数的百分比减少幅度更大有关。
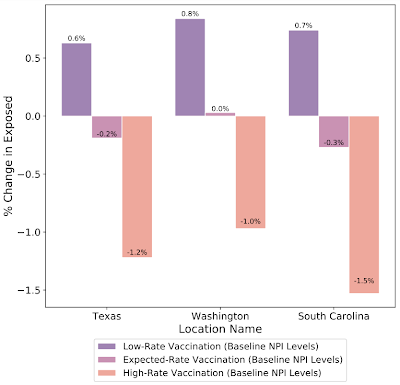
假设德克萨斯州、华盛顿州和南卡罗来纳州的疫苗接种率不同,预测日期为 2021 年 3 月 1 日,对预测暴露人数百分比变化进行假设模拟。在这些情况下,提高疫苗接种率对于减少暴露人数也起着关键作用。
公平性分析
为了确保我们的模型不会造成或强化不公平的偏见决策,根据我们的AI 原则,我们分别对美国和日本的预测进行了公平性分析,量化模型在受保护的子群体中的准确性是否更差。这些类别包括美国的年龄、性别、收入和种族,以及日本的年龄、性别、收入和原籍国。在所有情况下,一旦我们控制了每个子组中发生的 COVID-19 死亡和病例数量,我们就没有发现这些群体之间存在一致的错误模式。
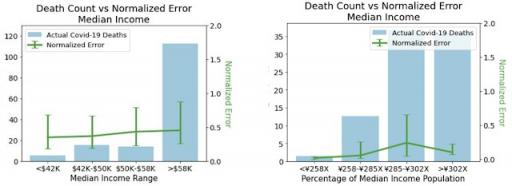
按中位数收入标准化的误差。两者之间的比较表明,一旦误差按案例标准化,误差模式就不会持续存在。左:按美国中位数收入标准化的误差。右:按日本中位数收入标准化的误差。
真实用例
除了通过定量分析来衡量我们模型的性能之外,我们还在美国和日本进行了结构化调查,以了解组织如何使用我们的模型预测。总共有七家组织对该模型的适用性做出了以下回应。
组织类型:学术界 (3)、政府 (2)、私营企业 (2)
主要用户职位:分析师/科学家 (3)、医疗保健专业人员 (1)、统计学家 (2)、管理人员 (1)
地点: 美国 (4), 日本 (3)
使用的预测:确诊病例 (7)、死亡 (4)、住院 (4)、ICU (3)、呼吸机 (2)、感染 (2)
模型用例:资源分配(2)、业务规划(2)、情景规划(1)、对 COVID 传播的一般了解(1)、确认现有预测(1)
使用频率:每日(1)、每周(1)、每月(1)
该模型是否有帮助?:是 (7)
举几个例子,在美国,哈佛大学全球健康研究所和布朗大学公共卫生学院利用预测结果帮助制定 COVID-19 检测目标,媒体利用这些目标帮助公众了解情况。美国国防部利用预测结果帮助确定资源分配方向,并帮助考虑具体事件。在日本,该模型用于制定商业决策。一家在 20 多个县设有门店的大型跨县公司利用预测结果更好地规划销售预测,并调整营业时间。
局限性和后续步骤
我们的方法有一些局限性。首先,它受到可用数据的限制,只要有可靠的高质量公共数据,我们才能发布每日预测。例如,公共交通的使用情况可能非常有用,但这些信息并不公开。其次,由于隔室模型的模型容量有限,它们无法模拟非常复杂的 Covid-19 疾病传播动态。第三,美国和日本的病例数和死亡人数分布非常不同。例如,日本的大多数 COVID-19 病例和死亡人数集中在其 47 个县中的几个县,其他县的病例数和死亡人数较低。这意味着,我们的每个县的模型都经过训练,可以在所有日本县中表现良好,但它们往往必须在避免过度拟合噪声和从这些相对没有 COVID-19 的县获得监督之间取得微妙的平衡。
我们已经更新了模型,以考虑疾病动态的巨大变化,例如疫苗接种数量的增加。我们还在扩大与市政府、医院和私人组织的新合作。我们希望我们的公开发布能够继续帮助公众和政策制定者应对持续大流行带来的挑战,我们希望我们的方法能够对流行病学家和公共卫生官员在当前和未来的健康危机中有所帮助。
致谢
这篇论文是 Google 内部各个团队和全球合作者辛勤工作的成果。我们特别要感谢来自庆应义塾大学医学院、圣卢克国际大学公共卫生研究生院和东京大学医学院的论文合著者。
评论