如今,机器学习 (ML) 模型的使用范围比以往任何时候都要广泛,影响力也越来越大。然而,当它们用于现实世界时,它们往往会表现出意想不到的行为。例如,计算机视觉模型可能对不相关的特征表现出令人惊讶的敏感性,而自然语言处理模型可能会不可预测地依赖于文本未直接表明的人口统计相关性。这些失败的一些原因是众所周知的:例如,使用精心策划的数据训练 ML 模型,或者训练模型来解决与应用领域结构不匹配的预测问题。然而,即使解决了这些已知问题,模型行为在部署中仍然可能不一致,甚至在训练运行之间也会有所不同。
在即将发表于《机器学习研究杂志》的 《规格不足给现代机器学习的可信度带来挑战》一文中,我们表明,规格不足是现代机器学习系统中尤为普遍的一种关键故障模式。规格不足背后的理念是,虽然机器学习模型是在保留数据上进行验证的,但这种验证通常不足以确保模型在新的环境中使用时具有明确定义的行为。我们表明,规格不足出现在各种实际机器学习系统中,并提出了一些缓解策略。
规格不足
机器学习系统之所以成功,很大程度上是因为它们结合了对保留数据进行模型验证,以确保高性能。然而,对于固定的数据集和模型架构,经过训练的模型通常可以通过多种不同的方式实现高验证性能。但根据标准做法,编码不同解决方案的模型通常被视为等效的,因为它们的保留预测性能大致相同。
重要的是,当以超出标准预测性能的标准(例如公平性或对无关输入扰动的鲁棒性)来衡量这些模型时,它们之间的区别就会变得清晰。例如,在标准验证中表现同样出色的模型中,有些模型在社会群体之间的表现差异可能大于其他模型,或者更依赖无关信息。反过来,当模型用于现实场景时,这些差异可能会转化为行为上的真实差异。
规格不足是指实践者在构建 ML 模型时经常考虑的要求与 ML 管道(即模型的设计和实现)实际执行的要求之间的差距。规格不足的一个重要后果是,即使管道原则上可以返回满足所有这些要求的模型,也无法保证该模型在实践中会满足除对保留数据进行准确预测之外的任何要求。事实上,返回的模型可能具有依赖于 ML 管道实现中做出的任意或不透明选择的属性,例如由随机初始化种子、数据排序、硬件等引起的属性。因此,不包含显性缺陷的 ML 管道仍可能返回在实际设置中表现异常的模型。
识别实际应用中的规格不足
在这项研究中,我们研究了实际应用中使用的各种 ML 模型中规格不足的具体影响。我们的实证策略是使用几乎相同的 ML 管道构建模型集,我们只对这些模型应用了一些对标准验证性能没有实际影响的小改动。在这里,我们专注于用于初始化训练和确定数据顺序的随机种子。如果这些变化会显著影响模型的重要属性,则表明管道没有完全指定这种实际行为。在我们进行这项实验的每个领域,我们都发现这些小改动会导致实际使用中重要的轴发生重大变化。
计算机视觉中的规格不足
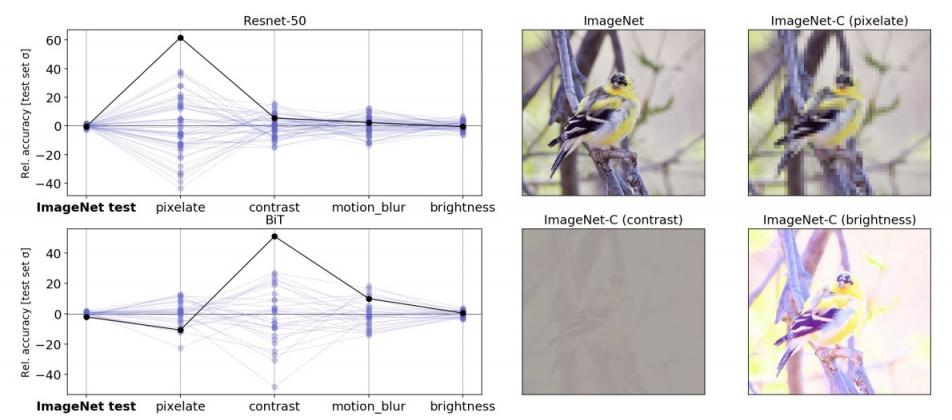
举个例子,考虑欠规格及其与计算机视觉稳健性的关系。计算机视觉的一个核心挑战是深度模型在分布变化下往往会变得脆弱,而人类并不觉得这很困难。例如,众所周知,在 ImageNet 基准上表现良好的图像分类模型在ImageNet -C等基准上表现不佳,这些基准将常见的图像损坏(如像素化或运动模糊)应用于标准 ImageNet 测试集。
在我们的实验中,我们表明标准管道没有充分指定模型对这些损坏的敏感性。按照上面讨论的策略,我们使用相同的管道和相同的数据生成了 50 个ResNet-50图像分类模型。这些模型之间的唯一区别是训练中使用的随机种子。在标准 ImageNet 验证集上进行评估时,这些模型实现了几乎相同的性能。但是,当在 ImageNet-C 基准中的不同测试集上(即在损坏的数据上)评估模型时,某些测试的性能差异比标准验证高出几个数量级。这种模式适用于在更大的数据集上进行预训练的更大规模模型(例如,在 3 亿张图像JFT-300M数据集上进行预训练的BiT-L模型)。对于这些模型,在训练的微调阶段改变随机种子会产生类似的变化模式。
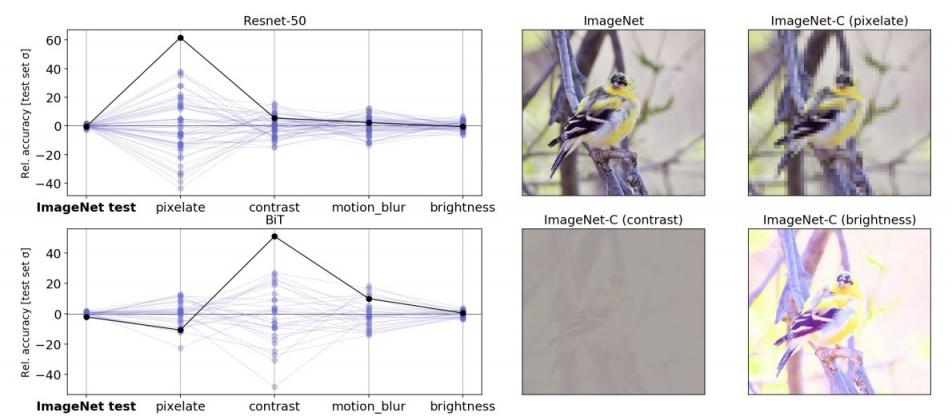
左图:平行轴图显示了在严重损坏的 ImageNet-C 数据上,相同的、随机初始化的 ResNet-50 模型之间的准确度变化。线表示使用未损坏的测试数据以及损坏的数据(像素化、对比度、运动模糊和亮度)在分类任务中集成中每个模型的性能。给定值是准确度与集成平均值的偏差,按“干净”ImageNet 测试集上的准确度标准偏差缩放。实心黑线突出显示任意选择的模型的性能,以显示一项测试中的表现可能无法很好地表明其他测试中的表现。右图:来自标准 ImageNet 测试集的示例图像,其中包含来自 ImageNet-C 基准的损坏版本。
我们还表明,在为医学成像构建的专用计算机视觉模型中,欠规范可能具有实际意义,而深度学习模型已显示出巨大的前景。我们考虑了两个旨在作为医学应用前身的研究流程:一个眼科流程,用于构建从视网膜眼底图像中检测糖尿病视网膜病变和可参考的糖尿病黄斑水肿的模型;一个皮肤科流程,用于构建从皮肤照片中识别常见皮肤病的模型。在我们的实验中,我们考虑了仅在随机保留数据上进行验证的流程。
然后,我们在实际重要的维度上对这些流程生成的模型进行了压力测试。对于眼科流程,我们测试了使用不同随机种子训练的模型在应用于训练期间未遇到的新相机类型拍摄的图像时的表现。对于皮肤科流程,压力测试类似,但针对的是估计皮肤类型不同的患者(即非皮肤科医生对肤色和对阳光的反应的评估)。在这两种情况下,我们发现标准验证不足以完全指定训练模型在这些轴上的性能。在眼科应用中,训练中使用的随机种子在新相机类型上引起的性能变化比标准验证预期的要大,而在皮肤科应用中,随机种子在皮肤类型子组中引起的性能变化相似,即使模型的整体性能在种子之间是稳定的。
这些结果重申,仅靠标准的保留测试不足以确保模型在医疗应用中的行为可接受,这强调了需要扩展用于医疗领域的 ML 系统的测试协议。在医学文献中,此类验证被称为“外部验证”,历来是STARD和TRIPOD等报告指南的一部分。这些在STARD-AI和TRIPOD-AI等更新中得到了强调。最后,作为受监管的医疗器械开发流程的一部分(例如,参见美国和欧盟法规),还有其他形式的安全和性能相关考虑因素,例如强制遵守风险管理、人为因素工程、临床验证和认可机构审查的标准,旨在确保可接受的医疗应用性能。
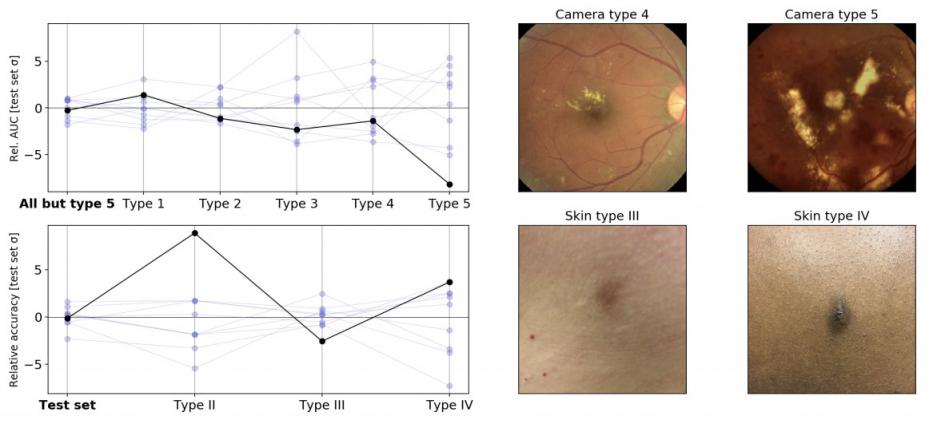
压力测试中医学成像模型的相对变异性,使用与上图相同的惯例。左上角:使用不同随机种子训练的糖尿病视网膜病变分类模型在对不同类型的相机图像进行评估时 AUC 的变化。在此实验中,训练期间未遇到相机类型 5。左下角:使用不同随机种子训练的皮肤状况分类模型在对不同的估计皮肤类型进行评估时准确度的变化(由皮肤科医生培训的外行人员根据回顾性照片进行近似,可能存在标记错误)。右图:来自原始测试集(左)和压力测试集(右)的示例图像。
其他应用中的规格不足
上面讨论的案例只是我们探索的模型的一小部分,我们研究的其他案例包括:
自然语言处理:我们表明,在各种 NLP 任务中,欠缺规范会影响模型从BERT处理的句子中得出的结果。例如,根据随机种子,管道可以生成一个模型,该模型在进行预测时 或多或少地依赖于涉及性别的相关性(例如,性别和职业之间的相关性)。
急性肾损伤 (AKI) 预测:我们表明,在基于电子健康记录的 AKI 预测模型中,规格不足会影响对操作信号与生理信号的依赖。
多基因风险评分 (PRS):我们发现,规格不足会影响 (PRS) 模型在不同患者群体中推广的能力,该模型根据患者基因组数据预测临床结果。
在每种情况下,我们都表明,这些重要属性在标准训练流程中定义不明确,这使得它们对看似无害的选择很敏感。
结论
解决规格不足是一个具有挑战性的问题。它需要对超出标准预测性能的模型进行全面规格说明和测试。要做好这项工作,需要充分了解模型的使用环境,了解训练数据的收集方式,并且通常在可用数据不足时结合领域专业知识。机器学习系统设计的这些方面在当今的机器学习研究中往往被低估。这项工作的一个主要目标是展示该领域的投资不足如何具体体现,并鼓励开发更全面地规格说明和测试机器学习管道的流程。
这一领域的一些重要第一步是为任何旨在实际使用的机器学习管道指定压力测试协议。一旦这些标准被编纂成可衡量的指标,许多不同的算法策略可能有助于改进它们,包括数据增强、预训练和因果结构的整合。然而,应该注意的是,理想的压力测试和改进过程通常需要迭代:机器学习系统的要求以及它们所处的世界都在不断变化。
致谢
我们要感谢所有合著者,Nenad Tomasev 博士(DeepMind)、Finale Doshi-Velez 教授(哈佛 SEAS)、英国生物银行,以及我们的合作伙伴 EyePACS、Aravind 眼科医院和 Sankara Nethralaya。
评论