许多机器学习 (ML) 模型通常专注于一次学习一项任务。例如,语言模型根据过去单词的上下文预测下一个单词的概率,而对象检测模型则识别图像中存在的对象。但是,有时同时从许多相关任务中学习可能会带来更好的建模性能。多任务学习领域解决了这个问题,多任务学习是 ML 的一个子领域,其中在同一模型中同时训练多个目标。
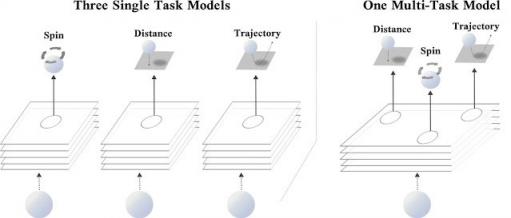
考虑一个现实世界的例子:乒乓球比赛。打乒乓球时,判断乒乓球的距离、旋转和即将出现的轨迹,以调整身体并调整挥杆姿势,通常很有好处。虽然这些任务都是独一无二的——预测乒乓球的旋转与预测其位置有着根本的不同——但提高对球的位置和旋转的推理能力可能会帮助你更好地预测其轨迹,反之亦然。以此类推,在深度学习领域,训练一个模型来预测三个相关任务(即乒乓球的位置、旋转和轨迹)可能会比只预测单个目标的模型性能更好。
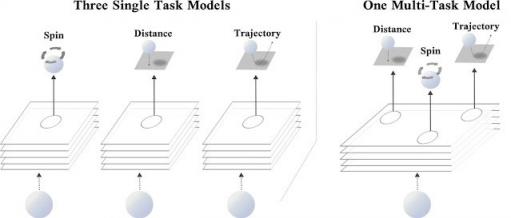
左图:三个单任务网络,每个网络使用相同的输入分别预测乒乓球的旋转、距离或轨迹。右图:一个多任务网络,可同时预测旋转、距离和轨迹。
在NeurIPS 2021的焦点演讲 “有效识别多任务学习中的任务分组”中,我们描述了一种称为任务亲和性分组 (TAG) 的方法,该方法确定应在多任务神经网络中一起训练哪些任务。我们的方法尝试将一组任务划分为更小的子集,以最大化所有任务的性能。为了实现这一目标,它在单个多任务模型中一起训练所有任务,并测量一个任务对模型参数的梯度更新对网络中其他任务的损失的影响程度。我们将这个量表示为任务间亲和性。我们的实验结果表明,选择最大化任务间亲和性的任务组与整体模型性能密切相关。
哪些任务应该一起训练?
理想情况下,多任务学习模型会将其在训练过程中学到的信息应用于一项任务,以减少训练网络时包含的其他任务的损失。这种信息传递导致单个模型不仅可以做出多项预测,而且与为每个任务训练不同的模型相比,这些预测的准确性也可能更高。另一方面,在许多任务上训练单个模型可能会导致模型容量竞争并严重降低性能。后一种情况通常发生在任务不相关的情况下。回到我们的乒乓球类比,想象一下试图预测乒乓球的位置、旋转和轨迹,同时复述斐波那契数列。这不是一个有趣的前景,而且很可能不利于你作为乒乓球运动员的进步。
选择模型应在其上进行训练的任务子集的一种直接方法是对一组任务的所有可能的多任务网络组合进行详尽搜索。但是,与此搜索相关的成本可能过高,尤其是在任务数量很多的情况下,因为可能的组合数量相对于集合中的任务数量呈指数增长。由于应用模型的任务集在其整个生命周期内可能会发生变化,这进一步复杂化了这一点。随着任务被添加到所有任务的集合中或从中删除,需要重复这种昂贵的分析来确定新的分组。此外,随着模型的规模和复杂性不断增加,即使是仅评估可能的多任务网络子集的近似任务分组算法也可能变得成本过高且评估起来非常耗时。
建立任务亲和力分组
在研究这一挑战时,我们从元学习 中汲取了灵感,元学习是机器学习的一个领域,它训练的神经网络可以快速适应新的、以前从未见过的任务。MAML 是一种经典的元学习算法,它对一组任务的模型参数应用梯度更新,然后更新其原始参数集,以最小化根据更新后的参数值计算的该集合中一组任务的损失。使用这种方法,MAML 训练模型学习的表示不会最小化其当前一组权重的损失,而是最小化经过一步或多步训练后的权重的损失。因此,MAML 训练模型的参数使其能够快速适应以前从未见过的任务,因为它针对未来而不是现在进行优化。
TAG 采用类似的机制来深入了解多任务神经网络的训练动态。具体来说,它仅针对单个任务更新模型的参数,查看此更改将如何影响多任务神经网络中的其他任务,然后撤消此更新。然后对其他每个任务重复此过程,以收集有关网络中的每个任务如何与任何其他任务交互的信息。然后,训练继续正常进行,根据网络中的每个任务更新模型的共享参数。
收集这些统计数据并观察它们在整个训练过程中的动态,可以发现某些任务始终表现出有益的关系,而有些任务则相互对立。网络选择算法可以利用这些数据将任务分组在一起,以最大限度地提高任务间的亲和力,这取决于从业者选择在推理过程中可以使用多少个多任务网络。

TAG 概述。首先,在同一个网络中对任务进行一起训练,同时计算任务间的亲和力。其次,网络选择算法找到最大化任务间亲和力的任务分组。第三,训练和部署得到的多任务网络。
结果
我们的实验结果表明,TAG 能够选出非常强大的任务分组。在CelebA和Taskonomy数据集上,TAG 与之前最先进的技术不相上下,同时运行速度分别快了 32 倍和 11.5 倍。在 Taskonomy 数据集上,这种加速意味着查找任务分组所需的 Tesla V100 GPU 小时数减少了 2,008 小时。
结论
TAG 是一种有效的方法,可以确定哪些任务应该在一次训练中一起训练。该方法研究任务如何通过训练进行交互,特别是在训练一个任务时更新模型参数会对网络中其他任务的损失值产生影响。我们发现,选择任务组来最大化这个分数与模型性能密切相关。
致谢
我们要感谢 Ehsan Amid、Zhe Zhao、Tianhe Yu、Rohan Anil 和 Chelsea Finn 对这项工作做出的根本性贡献。我们还要感谢 Tom Small 设计动画,以及整个 Google Research 营造协作和振奋人心的研究环境。
评论