
Meta 已确认将暂停使用欧盟和英国用户数据训练其 AI 系统的计划
此举遭到了爱尔兰数据保护委员会 (DPC) 的反对,该委员会是 Meta 在欧盟的主要监管机构,代表欧盟各地的多个数据保护机构行事。英国信息专员办公室 (ICO)也要求Meta 暂停其计划,直到它能够解决其提出的担忧为止。
DPC 在周五的一份声明中表示:“DPC 对 Meta 暂停使用欧盟/欧洲经济区成年人在 Facebook 和 Instagram 上分享的公开内容训练其大型语言模型的决定表示欢迎。” “这一决定是在 DPC 和 Meta 密切接触后做出的。DPC 将与其他欧盟数据保护机构合作,继续就这一问题与 Meta 进行接触。”
虽然 Meta 已经 在美国等市场 利用用户生成内容来训练其人工智能,但欧洲严格的GDPR 法规 为 Meta 和其他公司寻求改进其人工智能系统(包括使用用户生成的训练材料的大型语言模型)带来了障碍。
然而,Meta 上个月开始通知用户 其隐私政策即将发生变化 ,该公司表示,新政策将赋予其使用 Facebook 和 Instagram 上的公开内容来训练其人工智能的权利,包括评论内容、与公司的互动、状态更新、照片及其相关标题。该公司 辩称,它需要这样做 来反映“欧洲人民的语言、地理和文化背景多样性”。
这些变化原定于 6 月 26 日(即 12 天后)生效。但该计划促使 非营利隐私维权组织 NOYB (“不关你的事”)向欧盟成员国提起 11 起投诉,称 Meta 违反了 GDPR 的各个方面。其中之一涉及选择加入还是选择退出的问题, 对于确实 进行个人数据处理的地方,应该先征求用户的许可,而不是要求他们采取行动拒绝。
而 Meta 则依靠 GDPR 的一项名为“合法利益”的条款来辩称其行为符合法规。这并不是 Meta 第一次使用这一法律依据进行辩护, 此前它曾这样做过, 为处理欧洲用户的数据以投放定向广告辩护——尽管欧洲法院 (CJEU) 裁定,在这种情况下不能以合法利益作为辩护理由,这对 Meta 的最新数据探索来说并不是一个好兆头。
监管机构至少会暂时搁置 Meta 的计划变更,尤其是考虑到该公司让用户“选择不”使用其数据变得如此困难。该公司表示,它已向用户发送了超过 20 亿条通知,告知他们即将进行的变更,但与其他贴在用户信息流顶部的重要公共消息(例如外出 投票提示)不同,这些通知与用户的标准通知一起出现:朋友生日、照片标签提醒、群组公告等。因此,如果有人不定期查看通知,就很容易错过这些通知。
而那些看到通知的人不会自动知道有反对或选择退出的方式,因为它只是邀请用户点击以了解 Meta 将如何使用他们的信息。没有任何迹象表明这里有选择。
元:AI通知图片来源: Meta
此外,从技术上讲,用户无法“选择不”使用他们的数据。相反,他们必须填写一份异议表,提出他们不希望数据被处理的理由——是否接受这一请求完全由 Meta 自行决定,尽管该公司表示会满足每个请求。
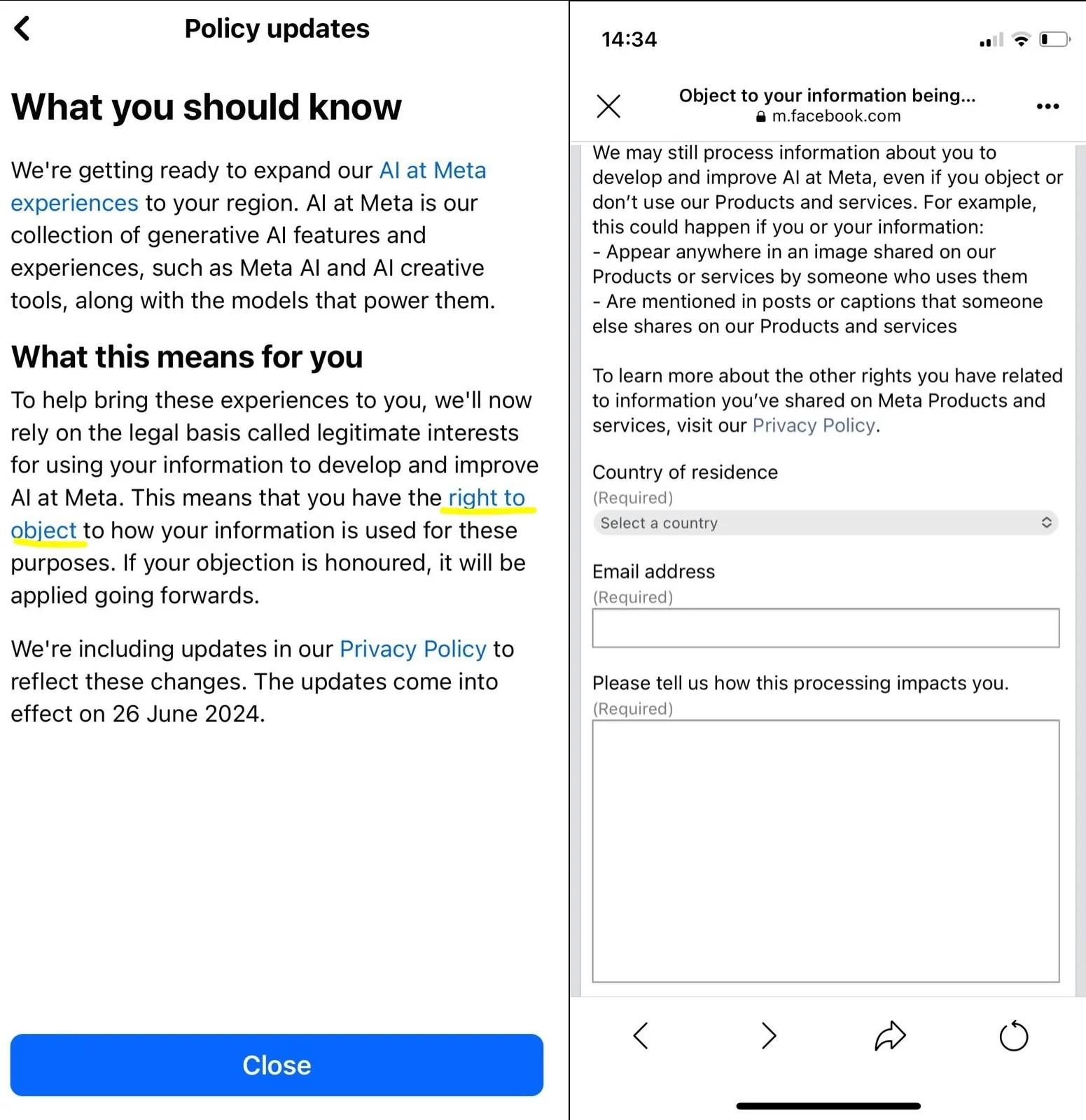 Facebook“反对”表格图片来源: Meta / 截图
Facebook“反对”表格图片来源: Meta / 截图
尽管异议表格与通知本身相链接,但任何主动在其帐户设置中寻找异议表格的人都会遇到困难。
在 Facebook 的网站上,他们必须先点击 右上角的 个人资料照片;点击设置和隐私;点击 隐私中心;向下滚动并点击 Meta 上的生成式 AI 部分;再次向下滚动经过一堆链接,到达标题为 更多资源的部分。此部分下的第一个链接名为“ Meta 如何使用信息创建生成式 AI 模型”,他们需要读完大约 1,100 个字才能找到指向公司“反对权”表格的独立链接。Facebook 移动应用程序中的情况也类似。

链接至“反对权”表格图片来源: Meta / 截图
本周早些时候,当被问及为何该流程要求用户提出异议而不是选择加入时,Meta 的政策传播经理 马特·波拉德 (Matt Pollard) 向 TechCrunch 指出了其 现有的博客文章,其中写道:“我们认为这一法律基础 [“合法利益”] 是在尊重人们权利的同时,以必要的规模处理训练 AI 模型所需的公共数据的最合适的平衡。”
换句话说,让用户选择加入可能不会产生足够的“规模”,因为人们愿意提供自己的数据。因此,最好的解决方法是在用户的其他通知中发布一条单独的通知;对于那些寻求“选择退出”的用户,隐藏反对表格,让他们点击六次;然后让他们解释他们的反对理由,而不是直接让他们选择退出。
Meta 隐私政策全球参与总监 Stefano Fratta 在周五更新的博客文章中表示,对 DPC 收到的请求感到“失望”。
“这对欧洲创新、人工智能开发竞争来说是一个倒退,也进一步推迟了人工智能为欧洲人民带来的好处,”Fratta 写道。“我们仍然非常有信心,我们的方法符合欧洲法律法规。人工智能培训并不是我们独有的服务,而且我们比许多行业同行更加透明。”
人工智能军备竞赛
这并不是什么新鲜事,Meta 参与的 人工智能军备竞赛 让人们聚焦 于 大型科技公司所掌握的有关我们所有人的海量数据。
今年早些时候, Reddit 透露,该公司已签订合同,将 在未来几年内通过向 ChatGPT 制造商 OpenAI和谷歌等公司授权数据来赚取超过 2 亿美元的收入。而后者已经 因依赖受版权保护的新闻内容来训练其生成式 AI 模型而面临巨额罚款。
但这些努力也凸显出公司会竭尽全力确保他们能够在现有立法的限制内利用这些数据;“选择加入”很少被列入议程,而选择退出的过程往往不必要地艰巨。就在上个月, 有人在现有的 Slack 隐私政策中发现了一些可疑的措辞 ,暗示该公司将能够利用用户数据来训练其人工智能系统,而用户只能通过向公司发送电子邮件来选择退出。
去年,谷歌 终于为在线出版商提供了一种方式 ,让他们可以选择不训练其网站模型,方法是将一段代码注入他们的网站。而 OpenAI 则正在 构建一个专用工具 ,让内容创建者可以选择不训练其生成式 AI 智能;这项功能应该会在 2025 年之前准备就绪。
虽然 Meta 在欧洲尝试训练其 AI 研究用户的公开内容的计划目前暂时搁置,但在与 DPC 和 ICO 协商后,该计划很可能会以另一种形式再次出现——希望能够采用不同的用户许可流程。
ICO 监管风险执行董事 Stephen Almond 在周五的一份声明中表示:“为了最大限度地利用生成式人工智能及其带来的机遇,让公众相信他们的隐私权从一开始就会受到尊重至关重要。” “我们将继续监控包括 Meta 在内的生成式人工智能的主要开发商,审查他们实施的保障措施,并确保英国用户的信息权利受到保护。”
本站全部资讯来源于实验室原创、合作机构投稿及网友汇集投稿,仅代表个人观点,不作为任何依据,转载联系作者并注明出处:https://www.lvsky.net/603.html
评论