
在 OpenAI 于 2022 年 11 月推出 ChatGPT 后的那几个月里,IT 行业的大部分注意力都集中在运行在强大的 GPU 集群上的庞大而昂贵的云基础设施上,以训练支撑聊天机器人和其他生成式 AI 工作负载的大型语言模型。这些架构可以完成工作,但超出了许多企业的承受范围,因为它们没有钱支付这些架构的费用,也没有人来管理它们。
最近,IT 供应商开始开发产品和服务,使运行 AI 工作负载成为更可行的方案,包括在其本地数据中心、本地工作站和其他设备以及云端。系统本身的成本以及将数据传回云端进行处理的成本已成为一个障碍,而随着企业希望通过检索增强生成 (RAG) 等技术将更多公司信息纳入用于训练 AI 系统的数据集,数据安全和主权已成为关键问题。
上个月举行的 2024 年戴尔科技世界大会的核心信息是,在本地完成更多 AI 工作,并将处理工作转移到数据生成的地方(包括一系列设备的边缘)。戴尔首席运营官兼副董事长 Jeff Clarke 指出,83% 的数据都在本地,而这些数据中有一半是由边缘设备生成的。
网络和服务巨头思科系统也在转向满足主流企业的 AI 工作负载需求。思科系统数据中心和提供商连接网络高级副总裁兼总经理 Kevin Wollenweber 表示,随着生成式 AI 作为一种企业工具不断成熟,这将成为重要的细分市场。
Wollenweber 告诉The Next Platform : “AI 的有趣之处在于它并不是一个单一的应用程序。我们训练模型的方式不同。这些 GPU 是大量集群,它们全部连接在一起,并在一个环境中运行以执行特定任务。你会听到 Nvidia 联合创始人兼首席执行官 Jensen Huang 谈论 AI 工厂和系统,它们是为了在大规模 LLM 中进行这些大规模训练而建立的,因此这将由少数非常大的客户来完成。如果你看看 AI 领域的支出,你会发现大部分资金已经投入其中。”
他补充说:“中间会有一个子部分或部分,用于微调这些模型,并可能使用 RAG 或其他技术来引入更多实时数据集。不是在一个时间段内训练这些东西然后继续前进,而是真正引入更多实时数据。然后你将使用这些模型和推理。所有这些都需要与网络截然不同的东西,以及与你将利用来构建它们的计算类型截然不同的东西。”
在本周于拉斯维加斯举行的 Cisco Live 展会上,该公司推出了 Cisco Nexus HyperFabric AI 集群产品,该产品结合了其 AI 网络、Nvidia 的加速计算和 AI 软件(例如其 AI Enterprise 软件平台)以及 VAST Data 的存储,将为希望运行更多 AI 工作负载并扩展其 AI 运营的企业提供更多自动化。这是思科与 Nvidia 共同开发的第一个工程包,重点是将各种硬件组件(包括存储和 GPU 设备)从服务器连接到 Nvidia 的“Bluefield”数据处理单元 (DPU) 的自动连接。
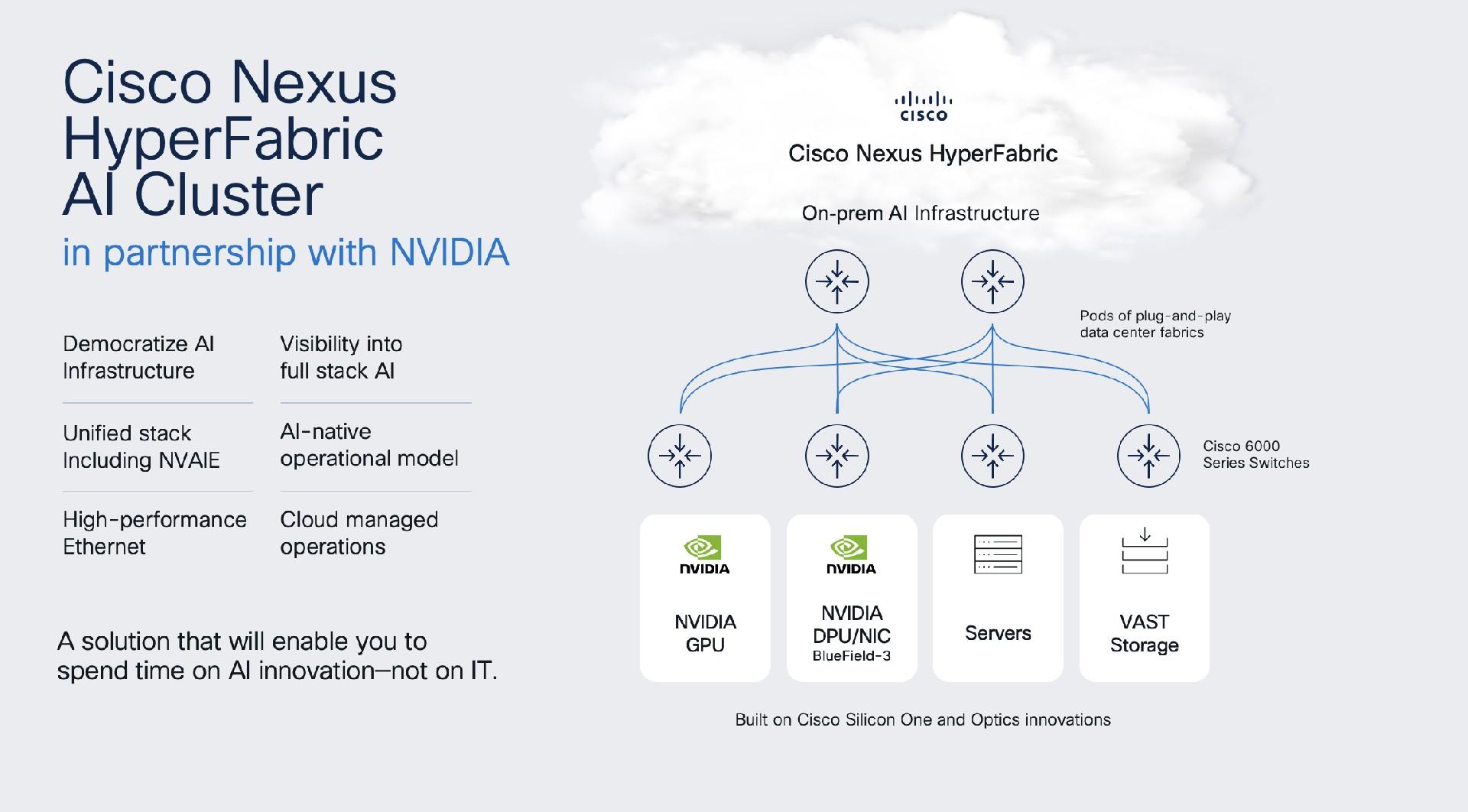
Nvidia 在高端企业市场表现不俗,这体现在其作为AI 工作负载加速器首选供应商的主导地位,以及其“Hopper”H100 GPU 的高需求——更不用说它的盈利能力了,第一季度营收达到 260 亿美元,同比增长 262%,Wollenweber 说道。
“但如果你看看他们作为一家公司是如何建立的,他们很多面向企业的市场营销以及一些微调和推理部署,他们并没有直接接触企业的长尾和庞大的企业客户群,”他说。“我们真正看到的是一个机会,利用他们目前拥有的一流人工智能技术,将它们与我们几十年来在简化和构建网络、管理网络和运营网络方面所做的工作结合起来,并构建一个解决方案,使客户能够推出本地小型、中型或大型基于 GPU 的计算集——无论他们实际需要什么——并以简单的方式完成,更多地专注于运行应用程序,真正从他们部署的设备中获得价值。”
思科推出了 6000 系列交换机,用于 400 Gb/秒和 800 Gb/秒以太网结构的脊叶式配置,以及 QSFP-DD 收发器模块,以提高密度。它还将包括 Nvidia 的 AI Enterprise 平台和 NIM 云原生微服务,这是该平台的一个容器式组件,包含运行 AI 工作负载的所有要素,包括 LLM、推理引擎和数据,运行在 Kubernetes Helm 图表中。还包括数据中心级 GPU,从 H200 NVL 开始,以及 Bluefield-3 SuperNIC。还有一个基于 Nvidia 的 MGX 服务器架构构建的参考设计。
VAST 正在贡献其数据平台,其中包括存储和数据库功能以及为 AI 构建的数据引擎。
思科产品管理和战略副总裁 Murali Gandluru 告诉The Next Platform ,以太网是一个关键组件。大多数企业都是围绕以太网而非 InfiniBand 构建基础设施的,多年来,以太网一直是思科产品组合的重要组成部分。Gandluru 表示,思科 Nexus HyperFabric AI 集群将允许组织使用多年来一直存在于其数据中心的技术作为其 AI 基础设施的一部分。
企业需要几个月的时间才能使用该产品。据供应商称,部分用户将在本季度晚些时候获得早期试用权,随后将全面推出。
思科指出,其最近的《全球网络趋势报告》证实了该战略。报告中指出,60% 的 IT 专业人员计划在未来两年内在其基础设施中部署基于 AI 的预测性网络自动化,以改善 NetOps 环境。此外,75% 的 IT 专业人员希望使用能够通过单一控制台提供对各种网络域(例如数据中心、公共云、分支机构和 WAN)可见性的工具。
对于刚刚开始 AI 工作或准备从测试转向更全面部署的企业来说,这些类型的套装产品是必需的。谷歌、微软和 Meta Platforms 等公司正在使用自己的 GPU 集成技术来构建网络和其他基础设施部分,以训练大量 LLM,Wollenweber 称之为“分部分”方法。并非所有企业都具备这样的能力。
Wollenweber 说:“你可以将其视为一个系统,它使他们能够部署大型结构、小型、中型或大量 GPU,但以更简单的方式完成。”“这不仅仅是将 GPU 放到基于互联网的结构上。我们实际上与 Nvidia 建立了工程合作伙伴关系。我们不只是转售他们的 GPU 并将它们连接到我们一直在构建的以太网结构中。该系统实际上有在 NIC 内部运行的代理,可以在运行这些 AI 工作负载时帮助我们管理和调度并从结构中获取效率。”
大型人工智能公司仍然占据着新闻头条的大部分份额。回想一下 1 月份,Meta Platforms 宣称计划在年底前斥资数十亿美元购买35 万块 Nvidia 的 H100 芯片,作为研究通用人工智能 (AGI) 的基础设施。通用人工智能是指人工智能能够像人类一样思考和推理,但速度要快得多。
但随着越来越多的企业开始从测试转向部署,业界可以期待更多像思科 Nexus HyperFabric AI 集群这样的打包架构,以实现基础设施的自动化和简化,从而使生成性 AI 更加触手可及。
本站全部资讯来源于实验室原创、合作机构投稿及网友汇集投稿,仅代表个人观点,不作为任何依据,转载联系作者并注明出处:https://www.lvsky.net/593.html
评论