机器学习 (ML) 在信息技术领域已变得十分突出,这导致一些人对相关计算成本上升表示担忧,主要是碳足迹,即温室气体总排放量。虽然这些断言理所当然地引发了有关机器学习中碳排放的讨论,但它们也强调了需要准确的数据来评估真实的碳足迹,这有助于确定减轻机器学习中碳排放的策略。
在《机器学习训练的碳足迹将稳定,然后减少》一文中,我们重点关注了自然语言处理 (NLP) 模型训练的运营碳排放(即运行 ML 硬件的能源成本,包括数据中心管理费用),并研究了可以减少碳足迹的最佳实践。我们展示了四种关键实践,这些实践可以大幅减少 ML 工作负载的碳足迹(和能源足迹),我们已采用这些实践帮助将 ML 占 Google 总能源消耗的 15% 以下。
4M:减少能源和碳足迹的最佳实践
我们确定了四种可显著减少能源和碳排放的最佳实践 - 我们称之为“4M” - 所有这些实践目前都在 Google 中使用,并且可供使用 Google Cloud 服务的任何人使用。
模型。选择高效的 ML 模型架构(例如稀疏模型)可以提高 ML 质量,同时将计算量减少 3 到 10 倍。
机器。与通用处理器相比 ,使用针对 ML 训练优化的处理器和系统可以将性能和能源效率提高 2 到 5 倍。
机械化。在云端而非本地进行计算可减少能源使用量,从而减少排放量 1.4 至 2 倍。基于云的数据中心是全新的、定制设计的仓库,配备了 50,000 台服务器的节能设备,从而实现了非常好的电源使用效率(PUE)。本地数据中心通常较旧且规模较小,因此无法分摊新的节能冷却和配电系统的成本。
地图优化。此外,云可以让客户选择能源最清洁的位置,从而进一步将总碳足迹减少 5 至 10 倍。虽然有人可能会担心地图优化可能会导致最环保的位置迅速达到最大容量,但用户对高效数据中心的需求将推动绿色数据中心设计和部署的持续进步。
这四种做法结合起来可以减少 100 倍的能源消耗和 1000 倍的排放量。
请注意,Google 将其 100% 的运营能源消耗与可再生能源相匹配。传统的碳补偿通常可追溯至碳排放后的一年,可在同一大陆的任何地方购买。Google 已承诺实现所有能源消耗的脱碳,以便到2030 年,它将在消耗能源的同一电网上全天候使用 100% 无碳能源运行。一些 Google 数据中心已经使用 90% 的无碳能源运行;2019 年的总体平均无碳能源为 61%,2020 年为 67%。
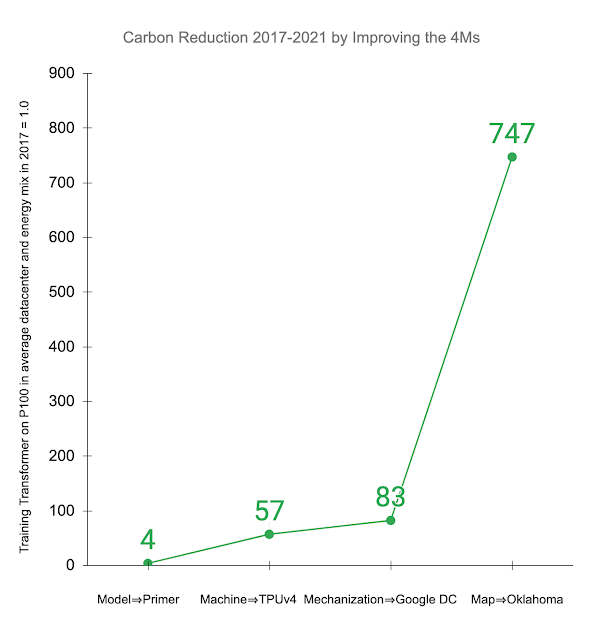
下面,我们将说明在实践中改进 4M 的影响。其他研究考察了在普通数据中心和与全球平均水平一致的能源结构中,在Nvidia P100 GPU上训练Transformer 模型的情况。最近推出的Primer 模型将实现相同准确度所需的计算量减少了 4 倍。使用新一代 ML 硬件(如TPUv4) ,与P100 相比,性能提升了 14 倍,总体提升了 57 倍。高效的云数据中心比普通数据中心的性能提升了 1.4 倍,总能耗降低了 83 倍。此外,使用低碳能源的数据中心可以将碳足迹再减少 9 倍,四年内碳足迹总减少 747 倍。
与其他研究一样,将 4M 最佳实践应用于 2017 年在普通数据中心使用 P100 GPU 训练的 Transformer 模型,可以减少二氧化碳当量总排放量 (CO 2 e) 。显示的值是依次解决每个 4M 的累积改进:将模型更新为 Primer;将 ML 加速器升级为 TPUv4;使用 PUE 优于平均水平的 Google 数据中心;并在使用非常清洁能源的 Google 俄克拉荷马州数据中心进行训练。
机器学习的总体能耗
谷歌的总能源使用量每年都在增加,考虑到其服务使用量的增加,这并不奇怪。机器学习工作负载增长迅速,每次训练的计算量也在增长,但关注 4M(优化模型、机器学习专用硬件、高效数据中心)在很大程度上抵消了这种增加的负载。我们的数据显示,在过去三年中,机器学习训练和推理仅占谷歌总能源使用量的 10%-15%,每年 ⅗ 用于推理,⅖ 用于训练。
先前的排放量估计
Google 使用神经架构搜索(NAS) 来寻找更好的 ML 模型。NAS 通常针对每个问题域/搜索空间组合执行一次,然后可以将生成的模型重新用于数千个应用程序 - 例如,NAS 找到的 Evolved Transformer 模型是开源的,供所有人使用。由于 NAS 找到的优化模型通常效率更高,因此 NAS 的一次性成本通常会被后续使用带来的减排所抵消。
马萨诸塞大学 (UMass) 的 一项研究估算了 Evolved Transformer NAS 的碳排放量。
由于无法轻松访问 Google 硬件或数据中心,该研究从可用的 P100 GPU 而不是 TPUv2 进行推断,并假设美国数据中心的平均效率,而不是高效的超大规模数据中心。这些假设使估算值比 Google 数据中心执行的实际 NAS 计算所用的能量高出 5 倍。
为了准确估算 NAS 的排放量,了解其工作原理的微妙之处非常重要。NAS 系统使用小得多的代理任务来搜索最有效的模型以节省时间,然后将找到的模型扩展到全尺寸。麻省大学的研究假设搜索重复了数千次全尺寸模型训练,导致排放量估计值又高出 18.7 倍。
NAS 的超调量为 88 倍:Google 数据中心的节能硬件超调量为 5 倍,使用代理的计算超调量为 18.7 倍。一次性搜索的实际二氧化碳排放量为 3,223 千克,而实际排放量为 284,019 千克,比公布的估计值低 88 倍 。
不幸的是,一些后续论文误解了 NAS 的估计值作为其发现的模型的训练成本,但这个特定 NAS 的排放量比训练模型大约高出 1300 倍。这些论文估计,训练 Evolved Transformer 模型需要200 万个 GPU 小时,花费数百万美元,其碳排放量相当于汽车一生排放量的五倍。实际上,在 UMass 研究人员研究的任务上训练 Evolved Transformer 模型并遵循 4M 最佳实践需要 120 个 TPUv2 小时,成本为 40 美元,并且仅排放 2.4 公斤(0.00004 辆汽车的寿命),减少了 120,000 倍。这个差距几乎和一个人高估制造一辆汽车的二氧化碳当量100倍,然后用这个数字作为驾驶汽车的二氧化碳当量一样大。
前景
气候变化很重要,因此我们必须准确计算,以确保我们专注于解决最大的挑战。在信息技术领域,我们认为这些成本更有可能是制造所有类型和尺寸的计算设备的生命周期成本(即包括制造所有相关组件(从芯片到数据中心建筑物)所产生的嵌入式碳排放估算值)1,而不是机器学习训练的运营成本。
如果每个人都能提高 4M 水平,那么好消息就会更多。虽然这些数字目前可能因公司而异,但整个行业都可以遵循以下简单的措施:
数据中心提供商应公布数据中心效率和每个位置的能源供应清洁度,以便客户了解并减少他们的能源消耗和碳足迹。
ML 从业者应该使用最环保的数据中心中的最佳处理器来训练模型,而这些数据中心如今通常在云端。
机器学习研究人员应继续开发更高效的机器学习模型,例如,利用稀疏性或通过集成检索来缩小模型。他们还应公布能源消耗和碳足迹,以促进模型质量以外的竞争,并确保对其工作的准确核算,而这很难在事后准确完成。
如果 4M 得到广泛认可,我们预计将出现一个良性循环,使曲线弯曲,从而使机器学习训练的全球碳足迹实际上正在缩小,而不是增加。
致谢
我要感谢我的合著者,他们坚持对这个对我们大多数人来说都是新话题进行漫长而曲折的研究:Jeff Dean、Joseph Gonzalez、Urs Hölzle、Quoc Le、Chen Liang、Lluis-Miquel Munguia、Daniel Rothchild、David So 和 Maud Texier。在早期研究中,我们也得到了其他人的大力帮助,最终促成了这篇论文的这一版本。Emma Strubell 为之前的论文提出了几条建议,包括建议研究最近的大型 NLP 模型。Christopher Berner、Ilya Sutskever、OpenAI 和 Microsoft 分享了有关 GPT-3 的信息。Dmitry Lepikhin 和 Zongwei Zhou 做了大量工作来衡量 Google 数据中心的 GPU 和 TPU 的性能和功率。Hallie Cramer、Anna Escuer、Elke Michlmayr、Kelli Wright 和 Nick Zakrasek 帮助提供了 Google 的能源和二氧化碳排放数据和政策。
评论