动作识别已成为研究界关注的重点领域,因为许多应用都可以从改进的建模中受益,例如视频检索、视频字幕、视频问答等。基于Transformer的方法最近在多个基准测试中展示了最先进的性能。虽然与ConvNets相比, Transformer 模型需要数据来学习更好的视觉先验,但动作识别数据集的规模相对较小。大型 Transformer 模型通常首先在图像数据集上进行训练,然后在目标动作识别数据集上进行微调。
虽然当前的预训练和微调动作识别范式很简单,并且表现出了强大的实证结果,但它对于构建通用动作识别模型来说可能过于严格。与涵盖大量对象识别类别的ImageNet等数据集相比, Kinetics和Something-Something-v2 (SSv2) 等动作识别数据集涉及的主题有限。例如,Kinetics 包括以对象为中心的动作,如“跳崖”和“攀冰”,而 SSv2 包含与对象无关的活动,如“假装将某物放在其他东西上”。因此,我们观察到将在一个数据集上经过微调的动作识别模型应用于另一个不同的数据集时性能 不佳。
数据集中对象和视频背景的差异进一步加剧了通用动作识别分类模型的学习难度。尽管视频数据集的规模可能在不断扩大,但先前的研究表明,要实现强劲的性能,必须进行大量的数据增强和正则化。后一项发现可能表明该模型在目标数据集上很快就会过拟合,从而阻碍了其推广到其他动作识别任务的能力。
在“使用视频和图像联合训练 Transformer 可提高动作识别效果”一文中,我们提出了一种名为CoVeR 的训练策略,该策略利用图像和视频数据联合学习一个通用动作识别模型。我们的方法由两个主要发现支持。首先,不同的视频数据集涵盖了多样化的活动,在单个模型中对它们进行联合训练可以得到一个在广泛活动中表现出色的模型。其次,视频是学习运动信息的完美来源,而图像则非常适合利用结构外观。利用图像示例的多样化分布可能有助于在视频模型中构建鲁棒的空间表示。具体而言,CoVeR 首先在图像数据集上对模型进行预训练,并在微调过程中,同时在多个视频和图像数据集上训练单个模型,以构建通用视频理解模型的鲁棒时空表示。
架构与训练策略
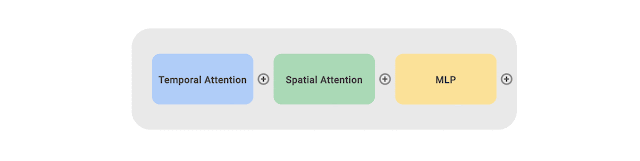
我们将 CoVeR 方法应用于最近提出的时空视频转换器TimeSFormer,它包含 24 层转换器块。每个块包含一个时间注意、一个空间注意和一个多层感知器(MLP) 层。为了从多个视频和图像数据集中学习,我们采用多任务学习范式,并为动作识别模型配备多个分类头。我们在大规模JFT数据集上预训练所有非时间参数。在微调过程中,从多个视频和图像数据集中采样一批视频和图像。采样率与数据集的大小成正比。批次中的每个样本都由 TimeSFormer 处理,然后分发到相应的分类器以获得预测。
与标准训练策略相比,CoVeR 有两个优势。首先,由于模型直接在多个数据集上训练,因此学习到的视频表示更具通用性,可以直接在这些数据集上进行评估,而无需进行额外的微调。其次,基于 Transformer 的模型可能很容易过度拟合较小的视频分布,从而降低学习到的表示的泛化能力。在多个数据集上进行训练可以降低过度拟合的风险,从而缓解这一挑战。
CoVeR 采用在多个数据集上进行训练的多任务学习策略,每个数据集都有自己的分类器。
基准测试结果
我们评估了 CoVeR 方法在Kinetics-400 (K400)、Kinetics-600 (K600)、Kinetics-700 (K700)、SomethingSomething-V2 (SSv2) 和Moments-in-Time (MiT) 数据集上的训练效果。与其他方法(如TimeSFormer、Video SwinTransformer、TokenLearner、ViViT、MoViNet、VATT、VidTr和OmniSource)相比,CoVeR 在多个数据集上建立了新的领先地位(如下所示)。与之前为单个数据集训练专用模型的方法不同,CoVeR 训练的模型可以直接应用于多个数据集,而无需进一步微调。
模型 预训练 微调 K400 精度
增值税 音频集+视频 K400 82.1
全源 IG-动力学-65M K400 83.6
薇薇特 JFT-300M K400 85.4
视频 SwinTrans ImageNet21K+外部 K400 86.8
覆盖 JFT-3B 解决方案 87.2
Kinetics-400 (K400) 数据集上的准确度比较。
模型 预训练 微调 SSv2 精度
时间先驱 ImageNet21k SSv2 62.4
韓國 ImageNet21k SSv2 63.0
薇薇特 ImageNet21k SSv2 65.9
视频 SwinTrans ImageNet21K+外部 SSv2 69.6
覆盖 JFT-3B 解决方案 70.9
在 SomethingSomething-V2 (SSv2) 数据集上进行准确度比较。
模型 预训练 微调 MiT 准确度
薇薇特 ImageNet21k 麻省理工学院 38.5
韓國 ImageNet21k SSv2 41.1
覆盖 JFT-3B 解决方案 46.1
时间点 (MiT) 数据集上的准确度比较。
迁移学习
我们利用迁移学习进一步验证视频动作识别性能,并与多个数据集上的协同训练进行比较,结果总结如下。具体来说,我们在源数据集上进行训练,然后在目标数据集上进行微调和评估。
我们首先将 K400 视为目标数据集。在 SSv2 和 MiT 上联合训练的 CoVeR 将 K400→K400(模型在 K400 上训练,然后在 K400 上微调)的 top-1 准确率提高了 1.3%,SSv2→K400 提高了 1.7%,MiT→K400 提高了 0.4%。同样,我们观察到,通过迁移到 SSv2,CoVeR 分别比 SSv2→SSv2、K400→SSv2 和 MiT→SSv2 提高了 2%、1.8% 和 1.1%。K400 和 SSv2 上 1.2% 和 2% 的性能提升表明,在多个数据集上联合训练的 CoVeR 可以比标准训练范式学习更好的视觉表征,这对下游任务很有用。
迁移学习 CoVeR 学到的表示与标准训练范式的比较。A→B 表示模型在数据集 A 上进行训练,然后在数据集 B 上进行微调。
结论
在本研究中,我们提出了 CoVeR,这是一种训练范式,它在单个模型中联合学习动作识别和对象识别任务,目的是构建通用动作识别框架。我们的分析表明,将许多视频数据集集成到一个多任务学习范式中可能会大有裨益。我们强调了在微调过程中继续学习图像数据以保持稳健的空间表征的重要性。我们的实证结果表明,CoVeR 可以学习一个通用视频理解模型,该模型在许多动作识别数据集上实现了令人印象深刻的性能,而无需在每个下游应用程序上进行额外的微调阶段。
致谢
我们要感谢 Christopher Fifty、Wei Han、Andrew M. Dai、Ruoming Pang 和 Fei Sha 准备了 CoVeR 论文,感谢 Yue Zhao、Hexiang Hu、Zirui Wang、Zitian Chen、Qingqing Huang、Claire Cui 和 Yonghui Wu 提供了有益的讨论和反馈,以及 Brain Team 其他成员在整个项目过程中提供的支持。
评论