视频识别是计算机视觉的一项核心任务,应用范围从视频内容分析到动作识别。然而,视频识别的训练模型通常需要手动注释未修剪的视频,这会非常耗时。为了减少收集带注释视频的工作量,由于大量易于获取的视频数据,从弱标签视频(即自动生成注释而无需人工干预)中学习视觉知识引起了越来越多的研究兴趣。例如,未修剪的视频通常是通过使用关键字查询视频识别模型想要分类的类别来获得的。然后为获得的每个未修剪的视频分配一个关键字(我们称之为弱标签)。
尽管带有弱标签的大规模视频更容易收集,但使用未经验证的弱标签进行训练对开发稳健模型提出了另一个挑战。最近的研究表明,除了标签噪声(例如,未修剪视频上的错误动作标签)之外,由于缺乏准确的时间动作定位,还存在时间噪声——即,未修剪的视频可能包含其他非目标内容,或者可能只在视频的一小部分中显示目标动作。
降低大规模弱监督预训练的噪声影响至关重要,但在实践中尤其具有挑战性。最近的研究表明,查询短视频(例如,约 1 分钟长)以获得更准确的目标动作时间定位或应用教师模型进行过滤可以产生更好的结果。然而,这样的数据预处理方法阻碍了模型充分利用可用的视频数据,尤其是内容更丰富的长视频。
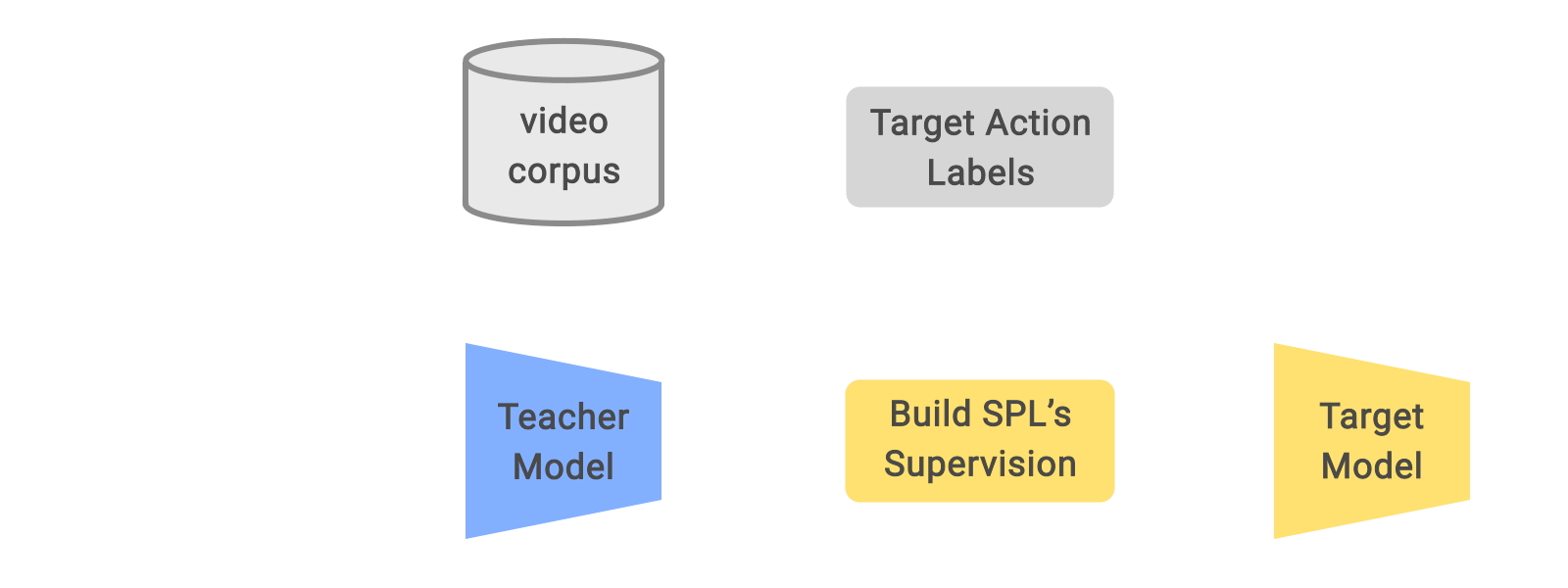
在“通过探索子概念从弱标记网络视频中学习”中,我们提出了一种解决这些问题的方法,即使用一个简单的学习框架对未修剪的视频进行有效的预训练。这种方法不是简单地过滤潜在的时间噪声,而是通过创建一组新的有意义的“中间地带”伪标签来扩展原始的弱标签空间,将这种“嘈杂”数据转换为有用的监督,我们将这一新概念称为子伪标签(SPL)。该模型在这个更“细粒度”的空间上进行预训练,然后在目标数据集上进行微调。我们的实验表明,学习到的表示比以前的方法要好得多。此外,SPL 已被证明可有效提高Google Cloud Video AI的动作识别模型质量,这使内容制作者能够轻松搜索其大量视频资产库以快速获取感兴趣的内容。
采样的训练片段可能表示与整个未修剪视频的查询标签(烘焙饼干)不同的视觉动作(搅拌鸡蛋)。SPL 通过推断两个相关动作类别来创建一组新的“中间地带”伪类(即子概念),从而将潜在的标签噪声转换为有用的监督信号。提供丰富的监督以实现有效的模型预训练。
子伪标签 (SPL)
SPL 是一种简单的技术,它推进了师生训练框架,该框架被认为可有效进行自我训练并改善半监督学习。在师生框架中,教师模型在高质量标记数据上进行训练,然后为未标记数据分配伪标签。学生模型在高质量标记数据和具有教师预测标签的未标记数据上进行训练。虽然以前的方法已经提出了许多提高伪标签质量的方法,但 SPL 采用了一种新颖的方法,结合了弱标签(即用于获取数据的查询文本)和教师预测标签的知识,从而总体上产生了更好的伪标签。该方法专注于时间噪声具有挑战性的视频识别,但可以轻松扩展到其他领域,如图像分类。
通过 SPL 从弱标记视频中学习的整体预训练框架。根据教师预测的标签和用于查询相应未修剪视频的弱标签,使用 SPL 重新标记每个修剪后的视频片段。
SPL 方法的动机是,在未修剪的视频中,“嘈杂”的视频片段与目标动作(即弱标签类别)具有语义关系,但也可能包含其他动作的基本视觉成分,例如教师模型预测类别。我们的方法使用从弱标签推断出的 SPL 以及提炼出的标签来捕获丰富的监督信号,鼓励在预训练期间学习更好的表示,可用于下游微调任务。
确定每个视频片段的 SPL 类别非常简单。我们首先使用从目标数据集训练的教师模型对每个视频片段进行推理,以获得教师预测类别。每个片段还由未修剪的源视频的类别(即查询文本)标记。使用二维混淆矩阵来总结教师模型推理与原始弱注释之间的对齐。基于此混淆矩阵,我们在教师模型预测和弱标签之间进行标签外推,以获得原始 SPL 标签空间。
左图:混淆矩阵,是原始 SPL 标签空间的基础。中图:生成的 SPL 标签空间(本例中为 16 个类别)。右图: SPL-B,另一个 SPL 版本,通过将每行的同意和不同意条目整理为独立的 SPL 类别来缩小标签空间,在本例中仅产生 8 个类别。
SPL 的有效性
我们评估了 SPL 与应用于在Kinetics-200 (K200)上微调的3D ResNet50模型的不同预训练方法的有效性。一种预训练方法只是使用ImageNet初始化模型。其他预训练方法使用从 147k 个视频的内部数据集中采样的 670k 个视频片段,这些视频片段是按照与 Kinetics-200 类似的标准流程收集的,涵盖了广泛的操作。弱标签训练和教师预测训练分别使用视频上的弱标签或教师预测标签。一致性过滤仅使用弱标签和教师预测标签匹配的训练数据。我们发现 SPL 优于这些方法中的每一种。虽然用于说明 SPL 方法的数据集是为这项工作构建的,但原则上我们描述的方法适用于任何具有弱标签的数据集。
预训练方法 前 1 名 前5名
ImageNet 已初始化 80.6 94.7
弱标签训练 82.8 95.6
教师预测训练 81.9 95.0
协议过滤训练 82.9 95.4
频率响应 84.3 95.7
我们还证明,从给定数量的未剪辑视频中抽取更多视频片段有助于提高模型性能。在有足够数量的视频片段可用的情况下,SPL 通过提供丰富的监督,始终优于弱标签预训练。
随着从 147K 视频中采样的片段越来越多,标签噪声逐渐增加。SPL 越来越有效地利用弱标记片段来实现更好的预训练。
我们通过在训练模型上应用Grad-CAM, 使用注意力可视化将从 SPL 中学习到的视觉概念可视化。观察 SPL 可以学习的一些有意义的“中间立场”概念是很有趣的。
SPL 课程注意力可视化示例。SPL 可以学习一些有意义的“中间立场”概念,例如混合鸡蛋和面粉(左)以及使用绳降设备(右)。
结论
我们证明 SPL 可以为预训练提供丰富的监督。SPL 不会增加训练的复杂性,可以被视为一种现成的技术,与基于教师-学生的训练框架相结合。我们认为,通过将弱标签与从教师模型中提炼出的知识联系起来,这是一个发现有意义的视觉概念的有前途的方向。SPL 还展示了对图像识别领域的良好泛化能力,我们期待未来的扩展能够应用于标签中有噪音的任务。我们已成功将 SPL 应用于 Google Cloud Video AI,它提高了动作识别模型的准确性,帮助用户更好地理解、搜索和利用他们的视频内容库获利。
致谢
我们衷心感谢其他合著者的贡献,包括李昆鹏、熊学汉、李晨宇、陆志超、付云、Tomas Pfister。我们还感谢 Debidatta Dwibedi、David A Ross、孙晨、Jonathan C. Stroud 和华伟对本文的宝贵意见和帮助,以及 Tom Small 的图表创作。
评论