您是否曾经查询过推荐系统,发现几分钟后或在不同设备上进行相同的搜索会产生截然不同的结果?这种情况并不少见,如果用户正在寻找特定的东西,这可能会令人沮丧。作为此类系统的设计者,测量的指标从设计和测试到部署发生变化的情况也并不少见,这让人对实验测试阶段的实用性产生质疑。随着世界的变化和新模型的部署,可以预料到某种程度的不可重复性。然而,当请求命中同一模型的重复项或模型正在刷新时,这种情况也会经常发生。
缺乏可重复性,即研究人员无法使用给定模型重现已发表的结果,这已被视为机器学习 (ML) 领域的一大挑战。不可重复性是一个相关但更难以捉摸的问题,即给定模型的多个实例在相同的训练条件下对相同的数据进行训练,但会产生不同的结果。直到最近,不可重复性才被认定为一个难题,但由于其复杂性,理解这一问题的理论研究极其罕见。
实际上,深度网络模型是在高度并行化和分布式的环境中训练的。训练中的不确定性(包括随机初始化、并行性、分布式训练、数据混洗、量化误差、硬件类型等)加上具有多个局部最优的目标,导致了不可重复性的问题。其中一些因素(如初始化)是可以控制的,但控制其他因素则是不切实际的。在训练早期,优化轨迹可能会通过按照所见顺序跟踪训练示例而出现分歧,从而导致非常不同的模型。最近发表的几种基于集成、自集成和提炼的高级组合的解决方案 [ 1、2、3 ]可以缓解这一问题,但通常以牺牲准确性和增加复杂性、维护和改进成本为代价。
在“现实世界中的大规模推荐系统可重复性和平滑激活”中,我们考虑了该问题的一种不同的实用解决方案,该解决方案不会产生其他解决方案的成本,同时仍能提高可重复性并提高模型准确度。我们发现,整流线性单元(ReLU) 加剧了不可重复性问题,ReLU 是用于在神经网络中转换值的非常流行的非线性函数(即激活函数)。另一方面,我们证明平滑激活函数与 ReLU 不同,其导数在整个域内连续,能够大幅降低不可重复性水平。然后,我们提出了平滑 reLU (SmeLU) 激活函数,它与其他平滑激活函数具有可比的可重复性和准确度优势,但要简单得多。
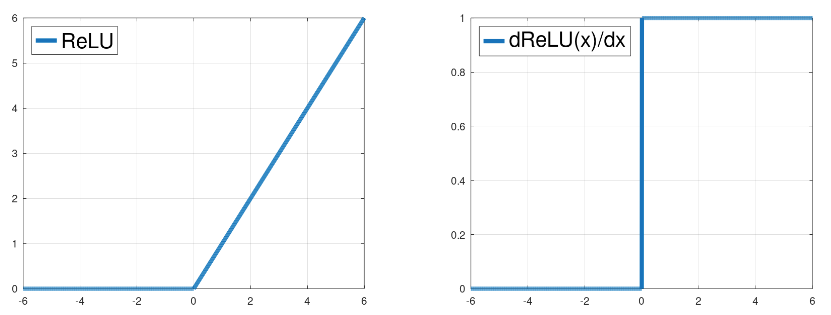
ReLU 函数(左)作为输入信号的函数,其梯度(右)作为输入的函数。
平稳激活
ML 模型试图通过最小化损失来学习最适合训练数据的模型参数,损失可以想象为有山峰和山谷的景观,其中最低点可获得最佳解决方案。对于深度模型,景观可能由许多这样的山峰和山谷组成。模型使用的激活函数控制着这个景观的形状以及模型如何导航它。
ReLU 不是一个平滑函数,它强加了一个目标,其景观被划分为具有多个局部最小值的多个区域,每个区域提供不同的模型预测。在这种景观下,应用更新的顺序是确定优化轨迹的主要因素,从而导致不可重复性。由于其非连续梯度,ReLU 网络表达的函数将包含梯度的突然跳跃,这可能发生在深度网络的不同层内部,影响不同内部单元的更新,并且可能是导致不可重复性的重要因素。
假设一系列模型更新尝试将某个单元的激活从正值向下推。ReLU 函数的梯度对于正单元值为 1,因此每次更新都会使单元变得越来越小(上图中向左)。当该单元的激活从正值变为负值时,梯度会突然从幅度 1 变为幅度 0。训练尝试继续向左移动单元,但由于梯度为 0,单元无法继续向该方向移动。因此,模型必须求助于更新其他可以移动的单元。
我们发现具有平滑激活的网络(例如GELU、Swish和Softplus)的可重复性更高。它们可能表现出相似的客观景观,但区域较少,从而使模型发散的机会较少。与 ReLU 的突然跳跃不同,对于激活减少的单元,梯度逐渐减小到 0,这为其他单元提供了适应变化行为的机会。通过相同的初始化、适度的训练示例改组和隐藏层输出的规范化,平滑激活能够增加收敛到相同最小值的机会。然而,非常激进的数据改组会失去这一优势。
平滑激活函数在输出级别之间转换的速率,即其“平滑度”,是可以调整的。足够的平滑度可以提高准确性和可重复性。然而,太平滑会接近线性模型,同时模型准确性会相应降低,从而失去使用深度网络的优势。
不同平滑参数值β 的平滑激活(顶部)及其梯度(底部)作为输入值的函数。β决定了 0 和1梯度之间的过渡区域的宽度。对于 Swish 和 Softplus,β越大,区域越窄;对于 SmeLU, β越大,区域越宽。
平滑 reLU (SmeLU)
像 GELU 和 Swish 这样的激活需要复杂的硬件实现来支持指数和对数函数。此外,GELU 必须以数值方式计算或近似计算。这些属性可能使部署容易出错、成本高昂或速度缓慢。GELU 和 Swish 不是单调的(它们从略微下降开始,然后切换到增加),这可能会干扰可解释性(或可识别性),它们也没有句号或干净的斜率 1 区域,这些属性可以简化实现并可能有助于可重复性。
Smooth reLU (SmeLU) 激活函数设计为一个简单的函数,用于解决其他平滑激活函数的问题。它通过二次中间区域将左侧的斜率为 0 的线与右侧的斜率为 1 的线连接起来,从而在连接点处限制连续梯度(作为Huber损失函数的非对称版本)。
SmeLU 可以看作是 ReLU 与盒子的卷积。它提供了一种廉价而简单的平滑解决方案,在可重复性-准确性权衡方面可与计算成本更高且更复杂的平滑激活相媲美。下图说明了当我们逐渐从非平滑 ReLU 过渡到更平滑的 SmeLU 时,损失(目标)表面的过渡。宽度为 0 的过渡是基本的 ReLU 函数,对于该函数,损失目标具有许多局部最小值。随着过渡区域变宽(SmeLU),损失表面变得更平滑。如果过渡太宽,即太平滑,使用深度网络的好处就会减弱,我们就会接近线性模型解决方案——目标表面变平,可能会失去网络表达大量信息的能力。
随着激活函数的过渡区域变宽,从 ReLU 变为越来越平滑的 SmeLU(左),两个样本损失函数(中间和右边)的损失表面(作为 2D 输入的函数)也随之变宽。随着 SmeLU 函数平滑度的增加,损失表面也变得越来越平滑。
表现
SmeLU 使多个系统受益,特别是推荐系统,通过降低推荐交换率等方式提高了其可重复性。虽然使用 SmeLU 可以提高准确率,但它也取代了其他昂贵的方法来解决不可重复性问题,例如集成,这些方法以准确性为代价来减轻不可重复性。此外,在稀疏推荐系统中替换集成可以减少对生成每个集成组件的推理所需的模型参数进行多次查找的需求。这大大提高了训练和推理效率。
为了说明平滑激活的好处,我们将相对预测差异 (PD) 绘制为不同激活的某些损失变化的函数。我们将相对 PD 定义为两个模型的预测绝对差异与其预期预测之间的比率,该比率在所有评估示例中取平均值。我们观察到,在大型系统中,仅考虑两个模型就足以获得非常一致的结果,而且成本低廉。
下图显示了 PD 准确度损失平面上的曲线。为了提高可重复性,曲线越低越好,而为了提高准确度,曲线越靠左越好。与 ReLU 相比,平滑激活可以使 PD 减少大约 50%,同时仍可能提高准确度。SmeLU 的准确度与其他平滑激活相当,但可重复性更高(PD 更低),同时准确度仍优于 ReLU。
相对 PD 作为评估排名损失的百分比变化的函数,它衡量对于不同的激活,项目在推荐系统中的排名的准确程度(值越高,准确度越差)。
结论和未来工作
我们展示了现实世界实际系统中的不可重复性问题,以及它如何影响用户以及系统和模型设计者。虽然在试图解决研究结果缺乏可重复性时,人们很少关注这一特定问题,但不可重复性可能是一个关键问题。我们证明了使用平滑激活的简单解决方案可以大大减少问题,而不会降低模型准确性等其他关键指标。我们展示了一种新的平滑激活函数 SmeLU,它具有数学简单和易于实现的额外优势,而且成本低廉且不易出错。
理解可重复性,尤其是在目标不是凸的深度网络中,是一个悬而未决的问题。最近有人提出了针对较简单的凸情况的初步理论框架,但必须进行更多研究才能更好地理解这个问题,这将适用于依赖深度网络的实际系统。
致谢
我们要感谢 Sergey Ioffe 在 SmeLU 早期讨论中所做的贡献;感谢 Lorenzo Coviello 和 Angel Yu 在 SmeLU 早期采用过程中所提供的帮助;感谢 Shiv Venkataraman 对这项工作的赞助;感谢 Claire Cui 从一开始的讨论和支持;感谢 Jeremiah Willcock、Tom Jablin 和 Cliff Young 在实施过程中提供的大量支持;感谢 Yuyan Wang、Mahesh Sathiamoorthy、Myles Sussman、Li Wei、Kevin Regan、Steven Okamoto、Qiqi Yan、Todd Phillips、Ed Chi、Sunita Verna 以及其他许多人的多次讨论以及在许多不同系统中的集成;感谢 Matt Streeter 和 Yonghui Wu 对本文和本文的反馈;感谢 Tom Small 对本文插图提供的帮助。
评论