物体检测是一项由来已久的计算机视觉任务,旨在识别和定位图像中所有感兴趣的物体。在尝试识别或定位所有物体实例的同时还要避免重复时,复杂性就会增加。现有的方法(如Faster R-CNN和DETR)都经过精心设计,并且在架构和损失函数的选择上高度定制。现有系统的这种专业化带来了两大障碍:(1)它增加了调整和训练系统不同部分(例如区域提议网络、带有GIOU损失的图匹配等)的复杂性;(2),它会降低模型的泛化能力,需要重新设计模型才能应用于其他任务。
在ICLR 2022上发表的 “ Pix2Seq:用于对象检测的语言建模框架”中,我们提出了一种简单而通用的方法,从完全不同的角度解决对象检测问题。与现有的特定于任务的方法不同,我们将对象检测视为以观察到的像素输入为条件的语言建模任务。我们证明,与现有的高度专业化和优化良好的检测算法相比,Pix2Seq 在大规模对象检测COCO数据集上取得了具有竞争力的结果,并且通过在更大的对象检测数据集上对模型进行预训练可以进一步提高其性能。为了鼓励在这方面的进一步研究,我们也很高兴向更广泛的研究社区发布 Pix2Seq 的代码和预训练模型以及交互式演示。
Pix2Seq 概述
我们的方法基于这样的直觉:如果神经网络知道图像中物体的位置和内容,那么我们就可以简单地教它如何读出它们。通过学习“描述”物体,模型可以学习将描述建立在像素观察的基础上,从而得到有用的物体表征。给定一张图像,Pix2Seq 模型会输出一系列物体描述,其中每个物体都使用五个离散标记来描述:边界框角的坐标 [y min , x min , y max , x max ] 和一个类标签。
用于对象检测的 Pix2Seq 框架。神经网络感知图像,并为每个对象生成一系列标记,这些标记对应于边界框和类标签。
使用 Pix2Seq,我们提出了一种量化和序列化方案,将边界框和类标签转换为离散标记序列(类似于标题),并利用编码器-解码器架构来感知像素输入并生成对象描述序列。训练目标函数只是以像素输入和前面的标记为条件的标记的最大似然值。
根据对象描述构建序列
在常用的对象检测数据集中,图像具有可变数量的对象,这些对象表示为边界框和类标签的集合。在 Pix2Seq 中,由边界框和类标签定义的单个对象表示为 [y min, x min, y max, x max, class]。但是,典型的语言模型旨在处理离散标记(或整数),无法理解连续数字。因此,我们不是将图像坐标表示为连续数字,而是将坐标标准化为 0 到 1 之间,并将其量化为几百或几千个离散箱中的一个。然后将坐标转换为离散标记,对象描述也是如此,类似于图像标题,然后可以由语言模型进行解释。量化过程是通过将标准化坐标(例如,y min)乘以箱数减一,然后将其四舍五入为最接近的整数来实现的(详细过程可在我们的论文中找到)。
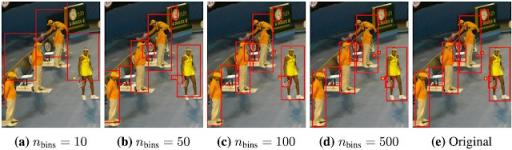
对 480 × 640 图像上具有不同数量 bin 的边界框坐标进行量化。使用较少数量的 bin/token,例如 500 个 bin(约 1 个像素/bin),即使对于小物体也能实现高精度。
量化后,每个训练图像提供的对象注释被排序为离散标记序列(如下所示)。由于对象的顺序对于检测任务本身并不重要,因此我们在训练期间每次显示图像时都会随机化对象的顺序。我们还会在末尾附加一个序列结束 (EOS) 标记,因为不同的图像通常具有不同数量的对象,因此序列长度也不同。
左侧图像中检测到的物体的边界框和类别标签在右侧显示的序列中表示。我们的工作中使用了随机物体排序策略,但也可以使用其他排序方法。
模型架构、目标函数和推理
我们将根据对象描述构建的序列视为“方言”,并通过带有图像编码器和自回归语言编码器的强大而通用的语言模型解决问题。与语言建模类似,Pix2Seq 经过训练,可以在给定图像和前面的标记的情况下,以最大似然损失预测标记。在推理时,我们从模型似然中对标记进行采样。当生成 EOS 标记时,采样序列结束。生成序列后,我们将其拆分为 5 个标记的块,以提取和反量化对象描述(即获取预测的边界框和类标签)。值得注意的是,架构和损失函数都是与任务无关的,因为它们不假设有关对象检测的先验知识(例如边界框)。我们在论文中描述了如何将特定于任务的先验知识与序列增强技术结合起来。
结果
尽管 Pix2Seq 很简单,但它在基准数据集上取得了令人印象深刻的经验性能。具体来说,我们在广泛使用的COCO 数据集上将我们的方法与成熟的基线 Faster R-CNN 和 DETR 进行了比较,并证明它实现了具有竞争力的平均精度(AP) 结果。
与现有需要在模型设计过程中进行专门化的系统相比,Pix2Seq 实现了具有竞争力的 AP 结果,同时显著简化了模型设计。性能最佳的 Pix2Seq 模型实现了 45 的 AP 分数。
由于我们的方法将最小的归纳偏差或物体检测任务的先验知识融入到模型设计中,我们进一步探索使用大规模物体检测 COCO 数据集对模型进行预训练会如何影响其性能。我们的结果表明,这种训练策略(以及使用更大的模型)可以进一步提高性能。
经过预训练和微调的 Pix2Seq 模型的平均精度。未经预训练时,表现最佳的 Pix2Seq 模型的 AP 分数为 45。当模型经过预训练后,我们看到 AP 分数提高了 11%,达到 50。
Pix2Seq 可以在密集且复杂的场景中检测物体,例如下面显示的场景。
由经过训练的 Pix2Seq 模型标记的复杂且人口密集的场景示例。请在此处尝试。
结论和未来工作
使用 Pix2Seq,我们将对象检测视为以像素输入为条件的语言建模任务,其模型架构和损失函数是通用的,并非专门为检测任务而设计。因此,人们可以轻松地将此框架扩展到不同的领域或应用程序,其中系统的输出可以用相对简洁的离散标记序列表示(例如,关键点检测、图像字幕、视觉问答),或者将其合并到支持通用智能的感知系统中,它为广泛的视觉和语言任务提供了语言界面。我们还希望 Pix2Seq代码、预训练模型和交互式演示的发布将激发该方向的进一步研究。
致谢
这篇文章反映了我们与合著者 Saurabh Saxena、Lala Li、Geoffrey Hinton 的共同努力。我们还要感谢 Tom Small 对 Pix2Seq 插图的可视化。
评论