机器人强化学习 (RL) 技术的进步使机器人代理能够在具有挑战性的环境中执行越来越复杂的任务。最近的结果表明,机器人可以学会折叠衣服、灵巧地玩魔方、按颜色分类物体、在复杂环境中导航以及在崎岖不平的地形上行走。但是,与机器人在现实世界中可能面临的许多任务相比,这些“短期”任务相对容易训练,因为它们几乎不需要长期规划,并且可以立即提供失败反馈。不幸的是,将这些短期技能扩展到现实世界任务的抽象、长期技能上是困难的。例如,如何训练一个能够捡起物体来重新布置房间的机器人?
分层强化学习(HRL) 是解决此问题的一种流行方法,已在各种长期强化学习任务中取得了一些成功。HRL 旨在通过对一系列低级技能进行推理来解决此类问题,从而为动作提供抽象。但是,高级规划问题可以通过抽象状态和动作进一步简化。例如,考虑桌面重新排列任务,其中机器人的任务是与桌子上的物体进行交互。利用强化学习、模仿学习和无监督技能发现方面的最新进展,可以获得一组原始操作技能,例如打开或关闭抽屉、拾取或放置物体等。但是,即使是将积木放入抽屉的简单任务,将这些技能串联在一起也并非易事。这可能归因于 (i) 长期规划和推理的挑战,以及 (ii) 在解析场景的语义和可供性(即何时何地可以使用技能)的同时处理高维观察。
在ICLR 2022上发表的 “价值函数空间:以技能为中心的长期推理状态抽象”中,我们解决了学习适合长期问题的状态和动作抽象的任务。我们假设 HRL 中高级策略的最小但完整的表示必须取决于其可用技能的能力。我们提出了一种使用技能价值函数获得这种表示的简单机制,并表明这种方法可以提高基于模型和无模型 RL 的长期性能,并实现更好的零样本泛化。
我们的方法 VFS 可以组合低级原语(左)来学习复杂的长期行为(右)。
构建价值函数空间
推动这项工作的关键见解是,动作和状态的抽象表示可以通过其价值函数从训练过的策略中轻松获得。强化学习中的“价值”概念与可供性有着内在联系,因为技能状态的价值反映了成功执行技能后获得奖励的概率。对于任何技能,其价值函数都捕获两个关键属性:1)场景的先决条件和可供性,即可以在何时何地使用技能,以及 2)结果,这表明技能在使用时是否成功执行。
给定一个决策过程,该过程具有一组有限的k 项技能,这些技能使用稀疏结果奖励及其相应的价值函数进行训练,我们通过堆叠这些技能价值函数来构建一个嵌入空间。这为我们提供了一个抽象表示,将状态映射到k维表示,我们将其称为价值函数空间,简称 VFS。此表示捕获了有关代理可以与环境进行的详尽交互集的功能信息,因此是下游任务的合适状态抽象。
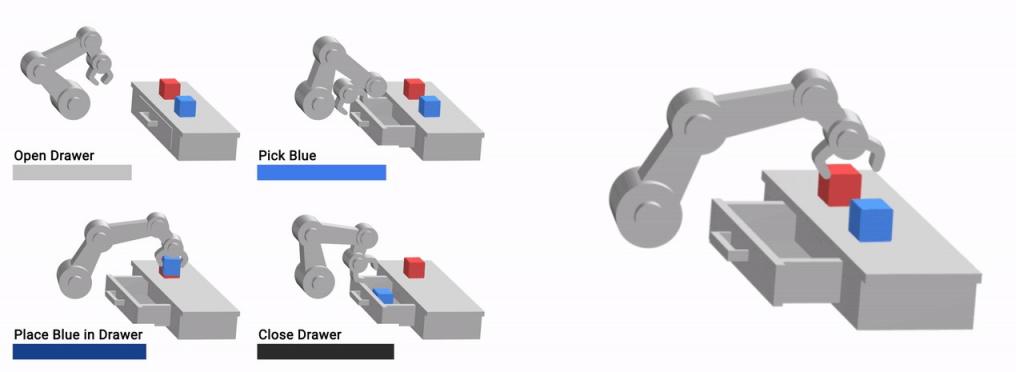
考虑前面讨论过的桌面重新排列设置的一个玩具示例,其任务是将蓝色物体放入抽屉中。此环境中有八个基本动作。右侧的条形图显示了每个技能在任何给定时间的值,底部的图表显示了这些值在任务过程中的演变。
一开始,“放置在柜台上”技能对应的值较高,因为物体已经在柜台上了;同样,“关闭抽屉”对应的值也较高。在整个轨迹中,当机器人拿起蓝色立方体时,对应的技能值达到峰值。同样,当抽屉打开时,将物体放入抽屉对应的值会增加,而当蓝色立方体放入抽屉时,对应的值会达到峰值。影响每个转换并预测其结果(成功或失败)所需的所有功能信息都由 VFS 表示捕获,原则上,它允许高级代理推理所有技能并将它们链接在一起——从而有效地表示观察结果。
此外,由于 VFS 学习的是场景的以技能为中心的表示,因此它对外生的变化因素(例如背景干扰因素和场景中与任务无关的组件的出现)具有很强的鲁棒性。下面显示的所有配置在功能上都是等效的- 一个打开的抽屉,里面有蓝色立方体,台面上有一个红色立方体,还有一个空的夹子 - 尽管存在明显的差异,但可以以相同的方式进行交互。
学习到的 VFS 表示可以忽略与任务无关的因素,例如手臂姿势、干扰物体(绿色立方体)和背景外观(棕色桌子)。
使用 VFS 进行机器人操作
这种方法使 VFS 能够规划复杂的机器人操作任务。以一个简单的基于模型的强化学习(MBRL) 算法为例,该算法使用价值函数空间中过渡动力学的简单一步预测模型,并随机抽取候选技能序列以选择和执行最佳技能序列,方式类似于模型预测控制。给定一组形式为“将物体 A移到物体 B附近”的原始推动技能和一个高级重新排列任务,我们发现 VFS 可以使用 MBRL 可靠地找到解决高级任务的技能序列。
VFS 使用机械臂执行桌面重新排列任务。VFS 可以推理一系列低级基元以实现所需的目标配置。
为了更好地理解 VFS 捕获的环境属性,我们从机器人操作任务中的大量独立轨迹中抽取 VFS 编码的观测值,并使用t-SNE 技术将它们投影到二维轴上,这对于可视化高维数据中的聚类非常有用。这些 t-SNE 嵌入揭示了 VFS 识别和建模的有趣模式。仔细观察其中一些聚类,我们发现 VFS 可以成功捕获有关场景中的内容(对象)和可供性的信息(例如,海绵被机器人的夹子夹住时可以被操纵),同时忽略诸如桌子上物体的相对位置和机械臂的姿势等干扰因素。虽然这些因素对于解决任务无疑很重要,但机器人可用的低级原语将它们抽象出来,因此在功能上与高级控制器无关。
可视化 VFS 嵌入的 2D t-SNE 投影,显示环境等效配置的紧急聚类,同时忽略与任务无关的因素,如手臂姿势。
结论以及与未来工作的联系
价值函数空间是建立在底层技能价值函数上的表示,可实现对技能的长期推理和规划。VFS 是一种紧凑的表示,可捕捉场景的可供性和与任务相关的信息,同时稳健地忽略干扰因素。实证实验表明,这种表示可改善基于模型和无模型方法的规划,并实现零样本泛化。展望未来,这种表示有望随着多任务强化学习领域的发展而继续改进。VFS 的可解释性进一步使其能够集成到安全规划和基础语言模型等领域。
致谢
我们感谢我们的合著者 Sergey Levine、Ted Xiao、Alex Toshev、Peng Xu 和 Yao Lu 对本文的贡献以及对这篇博文的反馈。我们还要感谢 Tom Small 创建了这篇博文中使用的信息可视化。
评论