来自 FAIR at Meta、INRIA、巴黎萨克雷大学和谷歌的计算机科学家和人工智能研究人员团队开发出了一种可能的方法,用于自动化人工智能数据集的自监督预训练的数据管理。
该团队撰写了一篇论文,描述了他们的开发过程、他们开发的技术以及迄今为止测试的效果。该论文发布在arXiv预印本服务器上。
开发人员和用户在过去一年中都了解到,用于训练 AI 系统的数据质量与结果的准确性密切相关。目前,使用手动整理数据的系统可获得最佳结果,而未经整理的数据系统则获得最差结果。
不幸的是,手动整理数据需要花费大量的时间和精力。因此,计算机科学家一直在寻找使该过程自动化的方法。在这项新研究中,研究团队开发了一种可以实现自动化的技术,并且其自动化程度与手动整理相当。
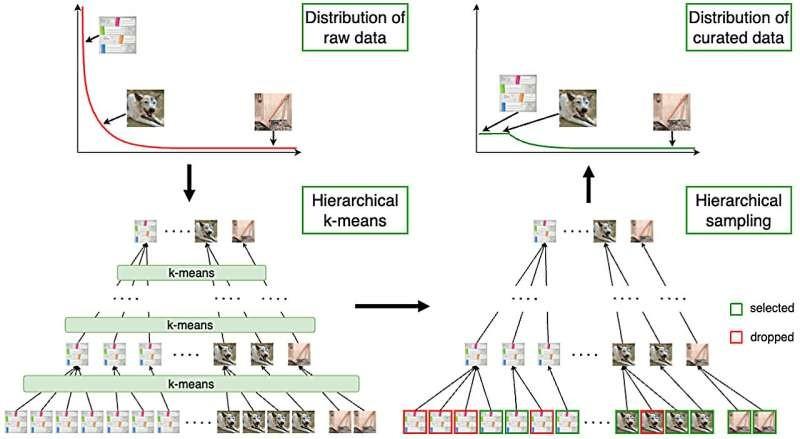
新技术从大型数据集开始,然后执行三步过程,从而生成更加多样化和更加平衡的数据。
第一步是使用特征提取模型来计算嵌入数据点的高质量位置。在他们的方法中,嵌入的内容是代表不同类型数据特征的数字,例如文本、音频或图像。
第二步涉及使用连续 k 均值聚类,其中数据点根据它们与其他数据点的相似性分配到一个组。
第三步是使用多步分层 K 均值聚类来确保数据聚类平衡。这是通过自下而上的方式构建数据聚类树来实现的。
研究团队使用在各种数据集上训练过的视觉模型测试了他们的技术。他们发现,使用他们的技术的模型比使用未经整理的数据的模型表现更好,并且与使用手动整理的数据训练的模型一样好,有时甚至更好。
还需要进行更多的测试来确定他们的技术在现实世界数据和不同类型的人工智能系统上运行得如何。
本站全部资讯来源于实验室原创、合作机构投稿及网友汇集投稿,仅代表个人观点,不作为任何依据,转载联系作者并注明出处:https://www.lvsky.net/501.html
评论