像 ChatGPT 这样的人工智能系统可能很快就会耗尽让它们变得更智能的资源——人们在网上书写和分享的数十万亿个单词。
研究小组 Epoch AI 周四发布的一项新研究预测,大约在本世纪初,也就是 2026 年至 2032 年之间,科技公司将耗尽人工智能语言模型的公开训练数据。
该研究的作者之一塔马伊·贝西罗格鲁将其比作耗尽有限自然资源的“淘金热”,他表示,一旦耗尽人类写作资源,人工智能领域可能难以维持目前的进步速度。
短期内, ChatGPT 制造商 OpenAI 和谷歌等科技公司正在竞相获取并有时付费获取高质量数据源来训练他们的 AI 大型语言模型——例如,通过签署协议来利用来自 Reddit 论坛和新闻媒体的稳定句子流。
从长远来看,不会有足够的新博客、新闻文章和社交媒体评论来维持人工智能发展的当前轨迹,这将给企业带来压力,迫使它们利用现在被视为私人的敏感数据(如电子邮件或短信),或者依赖聊天机器人自己产生的可靠性较低的“合成数据”。
“这里存在一个严重的瓶颈,”Besiroglu 说。“如果你开始遇到数据量方面的限制,那么你就无法再有效地扩展你的模型了。而扩展模型可能是扩展其能力和提高其输出质量的最重要方式。”
研究人员两年前(即 ChatGPT 首次亮相前不久)在一篇工作论文中首次做出了预测,该论文预测高质量文本数据的截止时间将在 2026 年左右。自那时以来,情况发生了很大变化,包括新技术的出现,这些新技术使 AI 研究人员能够更好地利用他们已有的数据,有时甚至会多次对同一来源的数据进行“过度训练”。
但这也存在局限性。经过进一步研究,Epoch 预计未来两到八年内公共文本数据将会耗尽。
该团队的最新研究已通过同行评审,并将在今年夏天于奥地利维也纳举行的国际机器学习会议上发表。Epoch 是一家非营利性机构,由旧金山的 Rethink Priorities 主办,由有效利他主义的支持者资助——这是一项慈善运动,已投入大量资金来减轻人工智能的最坏风险。
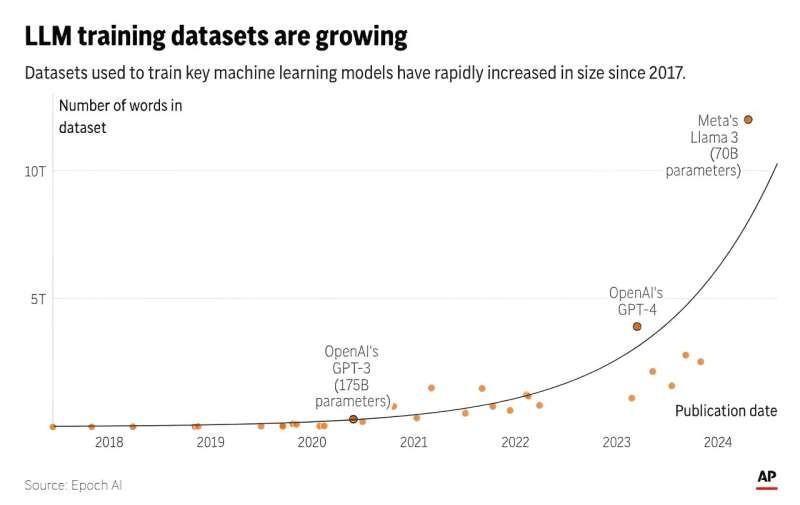
贝西罗格鲁表示,人工智能研究人员十多年前就意识到,积极扩展两个关键因素——计算能力和海量的互联网数据——可以显著提高人工智能系统的性能。
本站全部资讯来源于实验室原创、合作机构投稿及网友汇集投稿,仅代表个人观点,不作为任何依据,转载联系作者并注明出处:https://www.lvsky.net/497.html
评论