近年来,随着深度学习与自然语言处理 (NLP) 的融合,机器翻译(MT) 技术取得了重大进展。WMT等研究基准的表现飙升,翻译服务质量得到改善并扩展到包括新语言。尽管如此,尽管现有的翻译服务涵盖了全球大多数人使用的语言,但总共只涵盖了约 100 种语言,仅占全球活跃语言的 1% 多一点。此外,目前所代表的语言绝大多数是欧洲语言,很大程度上忽略了语言多样性高的地区,如非洲和美洲。
构建适用于长尾语言的翻译模型面临两个关键瓶颈。第一个瓶颈来自数据稀缺;许多语言的数字化数据有限,而且由于语言识别(LangID) 模型的质量问题,很难在网络上找到。第二个挑战来自建模限制。机器翻译模型通常使用大量平行(翻译)文本进行训练,但如果没有这样的数据,模型就必须学习从有限数量的单语文本中进行翻译,这是一个新的研究领域。要使翻译模型达到足够的质量,必须解决这两个挑战。
在“为下一个一千种语言构建机器翻译系统”中,我们描述了如何为一千多种没有可用翻译数据集的语言构建高质量的单语数据集,并展示了如何仅使用单语数据来训练机器翻译模型。作为这项工作的一部分,我们正在扩展Google 翻译以涵盖 24 种资源不足的语言。对于这些语言,我们通过开发和使用专门的神经语言识别模型结合新颖的过滤方法来创建单语数据集。我们引入的技术通过自监督任务补充了大规模多语言模型,以实现零资源翻译。最后,我们重点介绍了母语人士如何帮助我们实现这一成就。
了解数据
自动收集资源匮乏语言的可用文本数据比想象中要困难得多。像 LangID 这样的任务对资源丰富的语言很有效,但对资源匮乏的语言却不起作用,而且从网络上爬取的许多公开数据集通常包含的噪音多于它们试图支持的语言的可用数据。在我们早期尝试通过训练标准Compact Language Detector v3 (CLD3) LangID 模型来识别网络上资源匮乏的语言时,我们也发现数据集太嘈杂而无法使用。
作为替代方案,我们针对 1000 多种语言训练了基于Transformer 的半监督 LangID 模型。该模型使用 MAsked Sequence-to-Sequence (MASS) 任务补充 LangID 任务,以便更好地泛化嘈杂的网络数据。MASS 只是通过随机从输入中删除标记序列来扰乱输入,并训练模型来预测这些序列。我们将基于 Transformer 的模型应用于已使用 CLD3 模型过滤并训练识别相似语言集群的数据集。
然后,我们将开源的 词频-逆互联网频率(TF-IIF) 过滤应用于生成的数据集,以查找和丢弃实际上属于相关高资源语言的句子,并开发了各种特定于语言的过滤器来消除特定的病态。这项工作的结果是获得了一个包含 1000 多种语言的单语文本的数据集,其中 400 种语言有超过 100,000 个句子。我们对其中 68 种语言的样本进行了人工评估,发现大多数 (>70%) 反映了高质量的语言内容。
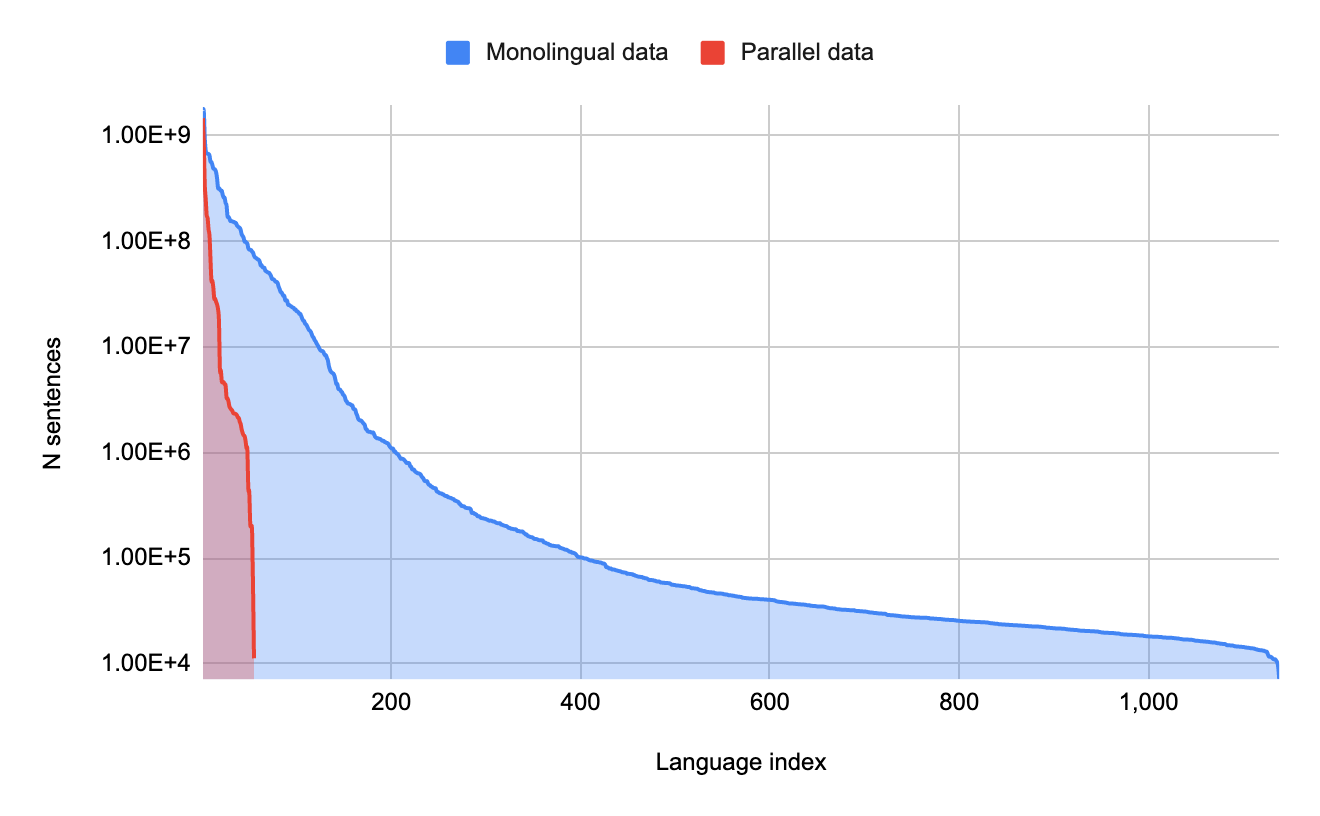
每种语言的单语数据量与每种语言的并行(翻译)数据量。少数语言拥有大量并行数据,但大量语言仅拥有单语数据。
见见模特
在我们拥有超过 1000 种语言的单语文本数据集后,我们开发了一种简单而实用的零资源翻译方法,即翻译没有语言内平行文本和没有特定语言翻译示例的语言。我们不会将模型限制在只有单语文本的人工场景中,而是将所有可用的平行文本数据与数百万个资源丰富的语言示例结合起来,使模型能够学习翻译任务。同时,我们使用 MASS 任务训练模型直接从单语文本中学习资源匮乏的语言的表示。为了解决这个任务,模型被迫开发一种复杂的语言表示,从而对句子中单词与其他单词的关系形成复杂的理解。
借助大规模多语言模型 中迁移学习的优势,我们利用所有可用数据训练单个巨型翻译模型,涵盖 1000 多种语言。该模型利用所有 1138 种语言的单语文本和 112 种资源丰富的语言子集的并行文本进行训练。
在训练时,模型看到的任何输入都有一个特殊标记,指示输出应采用哪种语言,这与多语言翻译的标准表述完全一样。我们的另一项创新是,对单语 MASS 任务和翻译任务使用相同的特殊标记。因此,标记Translation_to_french可能指示源文件是英文,需要翻译成法语(翻译任务),也可能意味着源文件是乱码的法语,需要翻译成流利的法语(MASS 任务)。通过对两个任务使用相同的标签,Translate_to_french标签的含义是“生成语义上接近输入的法语流利输出”,无论输入是乱码的同一种语言还是完全不同的另一种语言。从模型的角度来看,两者没有太大区别。
令人惊讶的是,这个简单的过程产生了高质量的零样本翻译。结果模型的BLEU和ChrF分数分别在 10-40 和 20-60 范围内,表明翻译质量为中到高质量。我们观察到,即使对于像克丘亚语和卡拉阿利苏特语这样高度屈折的语言,翻译也是有意义的,尽管这些语言在语言学上与模型中的所有其他语言都不同。但是,我们仅在具有人工翻译评估集的一小部分语言上计算了这些指标。为了了解其余语言的翻译质量,我们开发了一个基于往返翻译的评估指标,这使我们看到数百种语言的翻译质量都达到了很高的水平。
为了进一步提高质量,我们使用该模型生成大量合成并行数据,根据往返翻译(将一个句子翻译成另一种语言并再次翻译回来)过滤数据,并通过反向翻译和自我训练继续在这些过滤后的合成数据上训练模型。最后,我们在 30 种语言的较小子集上对模型进行微调,并将其提炼为足够小的模型以供使用。
使用我们开发的指标 (RTTLangIDChrF),我们模型支持的 638 种语言的翻译准确度得分,包括资源较多的监督语言和资源较少的零资源语言。
母语人士的贡献
与这些语言的母语人士定期交流对我们的研究至关重要。我们与谷歌和其他机构的 100 多名讲这些语言的人合作。一些志愿者帮助开发了专门的过滤器,以删除自动方法忽略的语言外内容,例如混入梵语的印地语。其他人帮助在这些语言使用的不同文字之间进行音译,例如在米特伊马耶克语和孟加拉语之间进行音译,因为当时没有足够的工具来翻译这些文字;还有一些人帮助完成一系列与评估相关的任务。母语人士在政治敏感性问题上的建议也发挥了关键作用,例如该语言的适当名称以及适当的书写系统。只有母语人士才能回答这个终极问题:鉴于目前的翻译质量,谷歌翻译支持这种语言对社区是否有价值?
结束语
这项进步是朝着支持资源匮乏语言的更多语言技术迈出的令人兴奋的第一步。最重要的是,我们要强调的是,这些模型产生的翻译质量仍然远远落后于 Google 翻译支持的资源丰富的语言。这些模型无疑是理解资源匮乏语言内容的有用工具,但它们会犯错误并表现出自己的偏见。与任何 ML 驱动的工具一样,人们应该仔细考虑输出。
本次更新中添加到 Google 翻译的新语言完整列表:
致谢
我们要感谢 Julia Kreutzer、Orhan Firat、Daan van Esch、Aditya Siddhant、Mengmeng Niu、Pallavi Baljekar、Xavier Garcia、Wolfgang Macherey、Theresa Breiner、Vera Axelrod、Jason Riesa、Yuan Cao、Mia Xu Chen、Klaus Macherey、Maxim Krikun、Pidong Wang、Alexander Gutkin、Apurva Shah、Yanping Huang、Zhifeng Chen、Yonghui Wu 和 Macduff Hughes 对该项目的研究、工程和领导所做的贡献。
我们还要向以下母语人士和受影响社区的成员表示最深切的感谢,他们以各种方式帮助了我们:Yasser Salah Eddine Bouchareb(阿尔及利亚阿拉伯语);Mfoniso Ukwak(Anaang 语);Bhaskar Borthakur、Kishor Barman、Rasika Saikia、Suraj Bharech(阿萨姆语);Ruben Hilare Quispe(艾马拉语);Devina Suyanto(巴厘语);Allahserix Auguste Tapo、Bakary Diarrassouba、Maimouna Siby(班巴拉语);Mohammad Jahangir(俾路支语);Subhajit Naskar(孟加拉语); Animesh Pathak、Ankur Bapna、Anup Mohan、Chaitanya Joshi、Chandan Dubey、Kapil Kumar、Manish Katiyar、Mayank Srivastava、Neeharika、Saumya Pathak、Tanya Sinha、Vikas Singh(博杰普尔); Bowen Liang、Ellie Chio、Eric Dong、Frank Tang、Jeff Pitman、John Wong、Kenneth Chang、Manish Goregaokar、Mingfei Lau、Ryan Li、Yiwen Luo(粤语); Monang Setyawan(加勒比爪哇语);克雷格·科尼利厄斯(切诺基);安东·普罗科皮耶夫(楚瓦什);拉贾·多格拉 (Rajat Dogra)、席德·多格拉 (Dogri);穆罕默德·卡马加特(Dyula); Chris Assigbe、Dan Ameme、Emeafa Doe、Irene Nyavor、Thierry Gnanih、Yvonne Dumor(埃维); Abdoulaye Barry、Adama Diallo、Fauzia van der Leeuw、Ibrahima Barry (Fulfulde);伊莎贝尔·帕帕迪米特里乌(希腊语);亚历克斯·鲁德尼克(瓜拉尼); Mohammad Khdeir(海湾阿拉伯语);保罗·雷莫拉塔(希利盖农);安库尔·巴普纳(印地语); Mfoniso Ukwak(伊比比奥); Nze Lawson(伊博语); DJ Abuy,迈阿密卡班赛(伊洛卡诺); Archana Koul、Shashwat Razdan、Sujeet Akula(克什米尔); Jatin Kulkarni、Salil Rajadhyaksha、Sanjeet Hegde Desai、Sharayu Shenoy、Shashank Shanbhag、Shashi Shenoy(Konkani);瑞安·迈克尔、泰伦斯·泰勒(Krio); Bokan Jaff、Medya Ghazizadeh、Roshna Omer Abdulrahman、Saman Vaisipour、Sarchia Khursheed(库尔德语(索拉尼语));Suphian Tweel(利比亚阿拉伯语);杜杜·基萨巴卡(林加拉语); Colleen Mallahan、John Quinn(卢干达);辛西娅·姆博利(Luyia); Abhishek Kumar、Neeraj Mishra、Priyaranjan Jha、Saket Kumar、Snehal Bhilare(迈蒂利);王丽莎(普通话); Cibu Johny(马拉雅拉姆语); Viresh Ratnakar(马拉地语); Abhi Sanoujam、Gautam Thockchom、Pritam Pebam、Sam Chaomai、Shangkar Mayanglambam、Thangjam Hindustani Devi(Meiteilon(曼尼普里)); Hala Ajil(美索不达米亚阿拉伯语); Hamdanil Rasyid(米南加保); Elizabeth John、Remi Ralte、S Lallienkawl Gangte、Vaiphei Thatsing、Vanlalzami Vanlalzami(Mizo);乔治·乌伊斯 (MSA); Ahmed Kachkach、Hanaa El Azizi(摩洛哥阿拉伯语);乌吉瓦尔·拉杰班达里 (Newari); Ebuka Ufere、Gabriel Fynecontry、Onome Ofoman、Titi Akinsanmi(尼日利亚洋泾浜语); Marwa Khost Jarkas(北黎凡特阿拉伯语); Abduselam Shaltu、Ace Patterson、Adel Kassem、Mo Ali、Yonas Hambissa(奥罗莫); Helvia Taina、Marisol Necochea(盖丘亚语); AbdelKarim Mardini(赛迪阿拉伯语); Ishank Saxena、Manasa Harish、Manish Godara、Mayank Agrawal、Nitin Kashyap、Ranjani Padmanabhan、Ruchi Lohani、Shilpa Jindal、Shreevatsa Rajagopalan、Vaibhav Agarwal、Vinod Krishnan(梵文);纳比尔·沙希德 (Saraiki); Ayanda Mnyakeni(塞索托,塞佩迪);兰迪斯·贝克(塞舌尔克里奥尔语); Taps Matangira(绍纳); Ashraf Elsharif(苏丹阿拉伯语);萨希莱·德拉米尼(斯瓦蒂);哈基姆·西达迈德(塔马泽特);梅尔文·约翰逊(泰米尔语); Sneha Kudugunta(泰卢固语); Alexander Tekle、Bserat Ghebremicael、Nami Russom、Naud Ghebre(Tigrinya); Abigail Annkah、Diana Akron、Maame Ofori、Monica Opoku-Geren、Seth Duodu-baah、Yvonne Dumor(契维语);奥斯曼·卢姆(沃洛夫);和丹尼尔·维尔特海姆(意第绪语)。
评论