近年来,自然语言处理模型显著 提高了学习通用表示的能力,从而显著提高了各种自然语言生成和自然语言理解任务的性能。这在很大程度上是通过在大量未标记的文本语料库上预先训练语言模型来实现的。
这种预训练公式不对输入信号模态做出假设,输入信号模态可以是语言、视觉或音频等。最近的几篇论文利用这种公式将图像预量化为离散整数代码(表示为自然数),并对其进行自回归建模 (即,一次一个标记地预测序列),从而显著改善图像生成结果。在这些方法中,卷积神经网络(CNN)被训练将图像编码为离散标记,每个标记对应图像的一小部分。然后训练第二阶段的 CNN 或Transformer来模拟编码后潜变量的分布。第二阶段也可以用于在训练后自回归生成图像。但是,虽然这类模型在图像生成方面取得了强劲的表现,但很少有研究评估学习到的表示对下游判别任务(如图像分类)的影响。
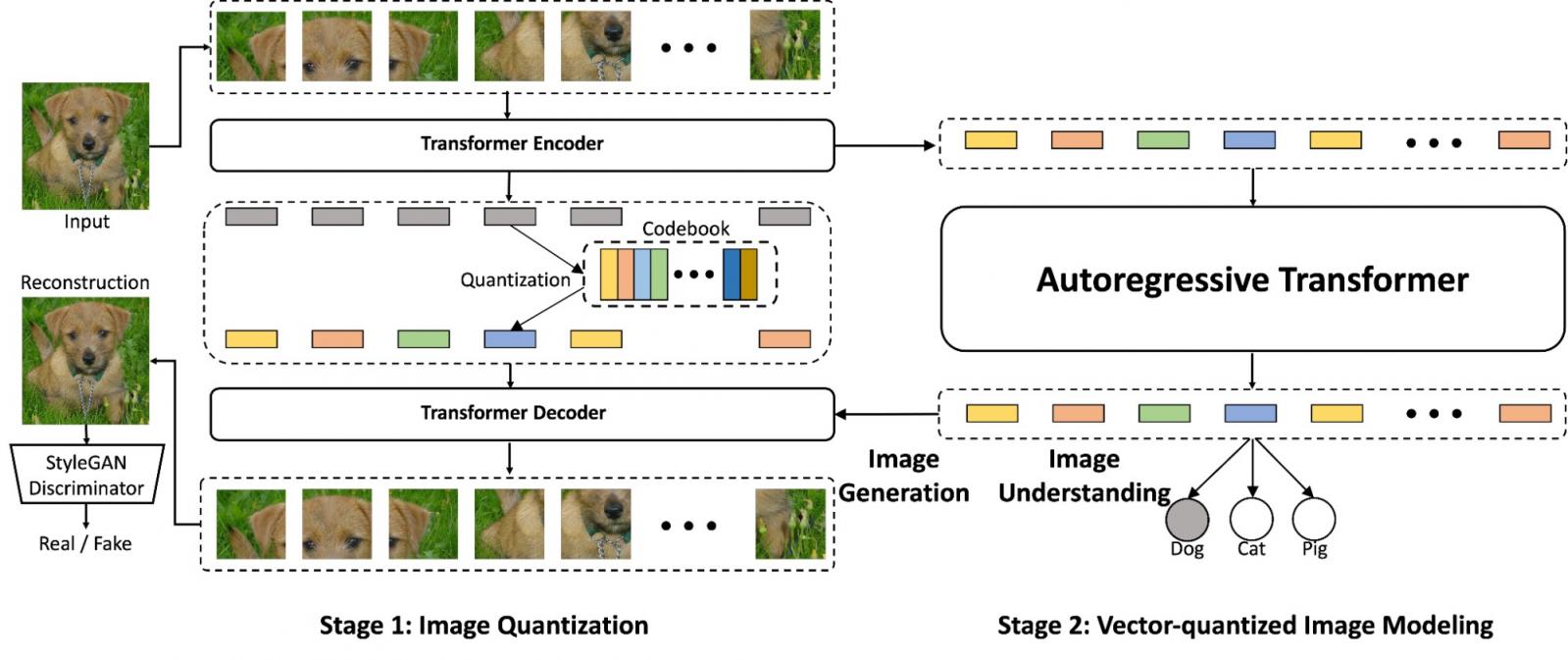
在“使用改进的 VQGAN 进行矢量量化图像建模”中,我们提出了一个两阶段模型,该模型重新构想了传统的图像量化技术,以提高图像生成和图像理解任务的性能。在第一阶段,图像量化模型(称为VQGAN)将图像编码为低维离散潜码。然后训练 Transformer 模型来对图像的量化潜码进行建模。这种方法我们称之为矢量量化图像建模 (VIM),可用于图像生成和无监督图像表示学习。我们描述了对图像量化器的多项改进,并表明训练更强大的图像量化器是改进图像生成和图像理解的关键组成部分。
使用 ViT-VQGAN 进行矢量量化图像建模
最近,一种常用的将图像量化为整数标记的模型是矢量量化变分自动编码器( VQVAE ),这是一种基于 CNN 的自动编码器,其潜在空间是一个离散可学习变量矩阵,经过端到端训练。VQGAN是此模型的改进版本,它引入了对抗性损失以促进高质量重建。VQGAN 使用非局部注意力块形式的类似 Transformer 的元素,这使其能够使用更少的层来捕获远距离交互。
在我们的工作中,我们建议将这种方法更进一步,用 ViT 替换 CNN 编码器和解码器。此外,我们引入了从编码器输出到低维潜在变量空间的线性投影,以查找整数标记。具体来说,我们将编码器输出从 768 维向量减少到每个代码 32 维或 8 维向量,我们发现这鼓励解码器更好地利用标记输出,从而提高模型容量和效率。
所提出的 ViT-VQGAN(左)和 VIM(右)的概览,它们协同工作时既能生成图像,又能理解图像。在第一阶段,ViT-VQGAN 将图像转换为离散整数,然后自回归 Transformer(第 2 阶段)学习对其进行建模。最后,将第 1 阶段解码器应用于这些标记,以便从头开始生成高质量图像。
借助我们训练过的 ViT-VQGAN,图像被编码为由整数表示的离散标记,每个标记包含输入图像的一个 8x8 块。使用这些标记,我们训练一个仅用于解码器的 Transformer,以自回归方式预测图像标记序列。这个两阶段模型 VIM 能够通过简单地从 Transformer 模型的输出 softmax 分布中逐个标记地进行采样来执行无条件图像生成。
VIM 还能够执行类条件生成,例如合成给定类(例如狗或猫)的特定图像。我们通过在训练和采样期间在图像标记前添加类 ID 标记,将无条件生成扩展为类条件生成。
在 ImageNet 上训练的类别条件图像生成中的一组未经整理的狗样本。条件类别:爱尔兰梗、诺福克梗、诺里奇梗、约克夏梗、刚毛猎狐梗、湖畔梗。
为了测试 VIM 的图像理解能力,我们还对线性投影层进行了微调,以执行 ImageNet 分类,这是衡量图像理解能力的标准基准。与ImageGPT类似,我们在特定块处获取层输出,对标记特征序列取平均值(冻结),并插入一个 softmax 层(可学习),将平均特征投影到类 logits。这使我们能够捕获中间特征,这些特征可为表示学习提供更多有用的信息。
实验结果
我们训练所有 ViT-VQGAN 模型,训练批次大小为 256,分布在 128 个CloudTPUv4核心上。所有模型均使用 256x256 的输入图像分辨率进行训练。在预先学习的 ViT-VQGAN 图像量化器的基础上,我们训练 Transformer 模型进行无条件和类条件图像合成,并与之前的工作进行比较。
我们在广泛使用的ImageNet基准 上测量了我们提出的类条件图像合成和无监督表示学习方法的性能。在下表中,我们展示了通过Fréchet 初始距离(FID)测量的类条件图像合成性能。与之前的工作相比,VIM 将 FID 提高到 3.07(越低越好),相对 VQGAN 模型(FID 7.35)提高了 58.6%。VIM 还提高了图像理解能力,如初始分数 (IS) 所示,从 188.6 提高到 227.4,相对于 VQGAN 提高了 20.6%。
模型 录取
率 火焰离子化 是
验证数据 1.0 1.62 235.0
直流变压器 1.0 36.5 不适用
BigGAN 1.0 7.53 168.6
BigGAN-deep 1.0 6.84 203.6
信息处理与分析专业委员会 1.0 12.3 不适用
ADM-G,1.0 指南。 1.0 4.59 186.7
维吾尔族自治县 1.0 ~31 ~45
向量生成对抗网络 1.0 17.04 70.6
向量生成对抗网络 0.5 10.26 125.5
向量生成对抗网络 0.25 7.35 188.6
ViT-VQGAN(我们的) 1.0 4.17 175.1
ViT-VQGAN(我们的) 0.5 3.04 227.4
不同模型在类条件图像合成和图像理解方面的 Fréchet 初始距离 (FID) 比较,以及初始分数 (IS) 比较,两者均在分辨率为 256x256 的 ImageNet 上进行。接受率显示了经过ResNet-101分类模型过滤的结果,类似于 VQGAN 中的过程。
在训练生成模型后,我们通过微调线性层来执行 ImageNet 分类(衡量图像理解能力的标准基准),从而测试学习到的图像表征。我们的模型在图像理解任务上的表现优于之前的生成模型,通过线性探测(即训练单个线性分类层,同时保持模型的其余部分不变)将分类准确率从 60.3% ( iGPT-L ) 提高到 73.2%。这些结果展示了 VIM 强大的生成结果以及图像表征学习能力。
结论
我们提出了矢量量化图像建模 (VIM),它预训练 Transformer 以自回归方式预测图像标记,其中离散图像标记由改进的 ViT-VQGAN 图像量化器生成。凭借我们提出的图像量化改进,我们在图像生成和理解方面都取得了优异的成果。我们希望我们的成果能够启发未来的工作,以实现更统一的图像生成和理解方法。
致谢
我们要感谢 Xin Li、Han Zhang、Ruoming Pang、James Qin、Alexander Ku、Yuanzhong Xu、Jason Baldridge 和 Yonghui Wu 准备 VIM 论文。我们感谢 Wei Han、Yuan Cao、Jiquan Ngiam、Vijay Vasudevan、Zhifeng Chen 和 Claire Cui 提供的有益讨论和反馈,以及 Google 研究和 Brain 团队的其他成员在整个项目过程中提供的支持。
评论