通常,机器学习 (ML) 模型开发人员会使用通用主干模型开始设计,该模型经过大规模训练,其功能可迁移到各种下游任务。在自然语言处理中,许多流行的主干模型(包括BERT、T5、GPT-3,有时也称为“基础模型”)都是在网络规模数据上进行预训练的,并通过零样本、少样本或迁移学习展示了通用的多任务处理能力。与训练过于专业的单个模型相比,为大量下游任务预训练主干模型可以摊销训练成本,从而让人们能够克服构建大规模模型时的资源限制。
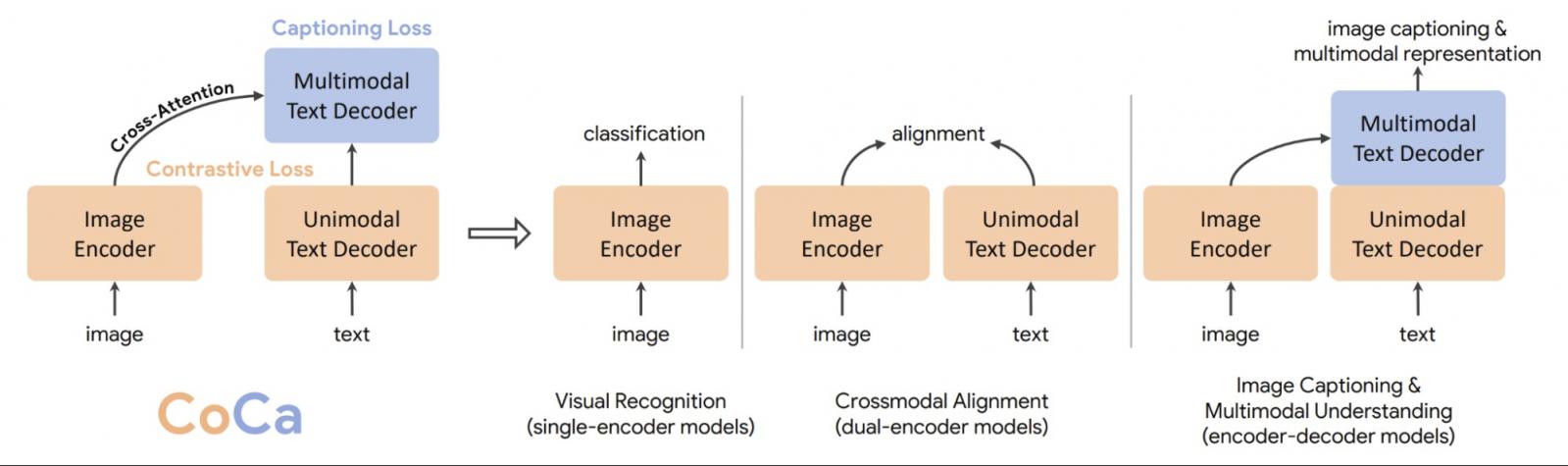
在计算机视觉领域,开创性的 工作 已经证明了针对图像分类进行预训练的单编码器模型能够有效捕获对其他下游任务有效的通用视觉表征。最近,人们探索了使用网络规模的噪声图像-文本对进行训练的对比双编码器(CLIP、ALIGN、Florence)和生成编码器-解码器(SimVLM)方法。双编码器模型表现出卓越的零样本图像分类能力,但对于联合视觉-语言理解效果较差。另一方面,编码器-解码器方法擅长图像字幕和视觉问答,但无法执行检索式任务。
在“ CoCa:对比字幕是图像文本基础模型”中,我们提出了一个统一的视觉主干模型,称为对比字幕(CoCa)。我们的模型是一种新颖的编码器-解码器方法,可同时生成对齐的单模态图像和文本嵌入以及联合多模态表示,使其足够灵活,可直接应用于所有类型的下游任务。具体来说,CoCa 在一系列视觉和视觉语言任务中取得了最先进的成果,涵盖视觉识别、跨模态对齐和多模态理解。此外,它学习高度通用的表示,因此它的表现可以与使用零样本学习或冻结编码器的完全微调模型一样好甚至更好。
对比字幕(CoCa)与单编码器、双编码器和编码器-解码器模型的概述。
方法
我们提出了 CoCa,这是一个统一的训练框架,它将对比损失和字幕损失结合在由图像注释和嘈杂的图像-文本对组成的单个训练数据流上,有效地融合了单编码器、双编码器和编码器-解码器范式。
为此,我们提出了一种新颖的编码器-解码器架构,其中编码器是视觉转换器(ViT),文本解码器转换器解耦为两部分,即单模态文本解码器和多模态文本解码器。我们跳过单模态解码器层中的交叉注意力,对纯文本表示进行编码,以实现对比损失,并将具有交叉注意力的多模态解码器层级联到图像编码器输出,以学习多模态图像文本表示,以实现字幕损失。这种设计最大限度地提高了模型在适应广泛任务方面的灵活性和通用性,同时,它可以通过一次前向和后向传播有效地训练两个训练目标,从而将计算开销降至最低。因此,可以从头开始端到端训练该模型,训练成本与简单的编码器-解码器模型相当。
CoCa 用于对比损失和字幕损失的前向传播图示。
基准测试结果
CoCa 模型可直接针对许多任务进行微调,且只需进行少量调整。通过这种方式,我们的模型在流行的视觉和多模态基准上取得了一系列最佳结果,包括 (1) 视觉识别:ImageNet、Kinetics- 400 / 600 / 700和MiT;(2) 跨模态对齐:MS-COCO、Flickr30K和MSR-VTT;(3) 多模态理解:VQA、SNLI-VE、NLVR2和NoCaps。
将 CoCa 与其他图像文本主干模型(没有针对特定任务的定制)以及多种最先进的任务专门模型进行比较。
值得注意的是,CoCa 以适用于所有任务的单一模型实现了这些结果,同时通常比之前表现最佳的专用模型更轻量。例如,CoCa 在使用不到之前最先进模型一半的参数的情况下获得了 91.0% 的 ImageNet top-1 准确率。此外,CoCa 还获得了强大的高质量图像字幕生成能力。
图像分类缩放性能比较微调的 ImageNet top-1 准确率与模型大小。
CoCa 使用 NoCaps 图像作为输入生成的文本字幕。
零样本表现
除了通过微调实现优异的性能外,CoCa 在零样本学习任务(包括图像分类和跨模态检索)上的表现也超越了之前最先进的模型。CoCa 在 ImageNet 上获得了 86.3% 的零样本准确率,同时在具有挑战性的变体基准测试(例如ImageNet-A、ImageNet-R、ImageNet-V2和ImageNet-Sketch )上也强劲超越了之前的模型。如下图所示,与之前的方法相比,CoCa 在模型尺寸较小的情况下获得了更好的零样本准确率。
图像分类缩放性能比较零样本 ImageNet top-1 准确率与模型大小。
冻结编码器表示
一个特别令人兴奋的观察是,CoCa 仅使用冻结视觉编码器 就取得了与最佳微调模型相当的结果,其中模型训练后提取的特征用于训练分类器,而不是微调模型的计算密集型工作。在 ImageNet 上,带有学习分类头的冻结 CoCa 编码器获得 90.6% 的 top-1 准确率,这比现有主干模型的完全微调性能(90.1 %)要好。我们还发现这种设置在视频识别方面效果极佳。我们将采样的视频帧单独输入 CoCa 冻结图像编码器,并通过注意力池融合输出特征,然后再应用学习到的分类器。这种使用 CoCa 冻结图像编码器的简单方法在 Kinetics-400 数据集上实现了 88.0% 的视频动作识别 top-1 准确率,并表明 CoCa 通过结合训练目标学习到了一种高度通用的视觉表征。
Frozen CoCa 视觉编码器与(多个)表现最佳的微调模型的比较。
结论
我们提出了对比字幕生成器 (CoCa),一种用于图像文本骨干模型的新型预训练范例。这种简单的方法广泛应用于多种类型的视觉和视觉语言下游任务,并且几乎不需要甚至不需要针对特定任务进行调整,即可获得最佳性能。
致谢
我们要感谢参与该项目各个方面的合作者 Vijay Vasudevan、Legg Yeung、Mojtaba Seyedhosseini 和 Yonghui Wu。我们还要感谢 Yi-Ting Chen、Kaifeng Chen、Ye Xia、Zhen Li、Chao Jia、Yinfei Yang、Zhengdong Zhang、Wei Han、Yuan Cao、Tao Zhu、Futang Peng、Soham Ghosh、Zihang Dai、Xin Li、Anelia Angelova、Jason Baldridge、Izhak Shafran、Shengyang Dai、Abhijit Ogale、Zhifeng Chen、Claire Cui、Paul Natsev 和 Tom Duerig 的有益讨论、Andrew Dai 对对比模型的帮助、Christopher Fifty 和 Bowen Zhang 对视频模型的帮助、Yuanzhong Xu 对模型扩展的帮助、Lucas Beyer 对数据准备的帮助、Andy Zeng 对 MSR-VTT 评估的帮助、Hieu Pham 和 Simon Kornblith 对零样本评估的帮助、Erica Moreira 和 Victor Gomes 对资源协调的帮助、Liangliang Cao 的校对、Tom Small 创建本博文中使用的动画,以及 Google Brain 团队的其他成员在整个项目过程中提供的支持。
评论