多模态视频字幕系统利用视频帧和语音来生成视频的自然语言描述(字幕)。此类系统是实现长期目标的垫脚石,即构建多模态对话系统,该系统可轻松与用户沟通,同时通过多模态输入流感知环境。
与视频理解任务(例如视频分类和检索)不同,这些任务的关键挑战在于处理和理解多模态输入视频,而多模态视频字幕任务还包括生成基础字幕的额外挑战。此任务最广泛采用的方法是使用手动注释的数据联合训练编码器-解码器网络。但是,由于缺乏大规模手动注释数据,为视频注释基础字幕的任务劳动密集型,并且在许多情况下不切实际。先前的研究,例如VideoBERT和CoMVT, 利用自动语音识别(ASR) 在未标记的视频上对其模型进行预训练。但是,此类模型通常无法生成自然语言句子,因为它们缺少解码器,因此只有视频编码器被转移到下游任务。
在CVPR 2022上发表的 “多模态视频字幕的端到端生成预训练”中,我们介绍了一种用于多模态视频字幕的新型预训练框架。这个框架,我们称之为多模态视频生成预训练或 MV-GPT,通过利用未来的话语作为目标文本并制定一种新颖的双向生成任务,从未标记的视频中联合训练多模态视频编码器和句子解码器。我们证明 MV-GPT 有效地转移到多模态视频字幕,在各种基准上取得了最先进的结果。此外,多模态视频编码器在多种视频理解任务中具有竞争力,例如VideoQA、文本视频检索和动作识别。
未来话语作为附加文本信号
通常,多模态视频字幕的每个训练视频片段都与两段不同的文本相关联:(1)与片段对齐的语音记录,作为多模态输入流的一部分,以及(2)目标字幕,通常是手动注释的。编码器学习将来自记录的信息与视觉内容融合,并使用目标字幕训练解码器进行生成。但是,对于未标记的视频,每个视频片段仅附带来自 ASR 的记录,而没有手动注释的目标字幕。此外,我们不能对编码器输入和解码器目标使用相同的文本(ASR 记录),因为这样目标的生成就会变得简单。
MV-GPT 通过将未来的话语作为附加文本信号并实现编码器和解码器的联合预训练来规避这一挑战。但是,训练模型来生成通常不以输入内容为基础的未来话语并不理想。因此,我们应用了一种新颖的双向生成损失来加强与输入的连接。
双向发电损失
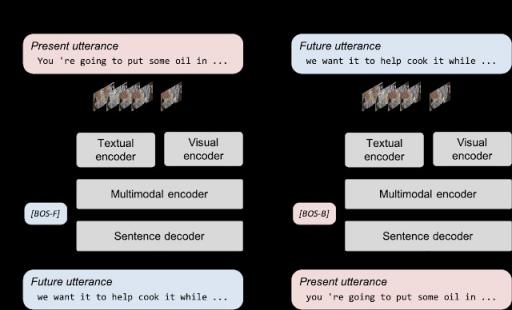
通过制定包括前向和后向生成的双向生成损失,可以缓解无基础文本生成的问题。前向生成根据视觉帧及其对应的转录生成未来的话语,并允许模型学习将视觉内容与其对应的转录融合。后向生成利用视觉帧和未来的话语来训练模型,以生成包含更多视频片段基础文本的转录。MV-GPT 中的双向生成损失允许编码器和解码器接受训练以处理视觉基础文本。
MV-GPT 中的双向生成。模型使用两个生成损失进行训练。在正向生成中,模型根据帧和当前话语(红色框)生成未来话语(蓝色框),而在反向生成中,当前话语由未来话语生成。两个特殊的句首标记([BOS-F] 和 [BOS-B])为解码器启动正向和反向生成。
多模式视频字幕的结果
我们在YouCook2 上使用相同的模型架构,使用标准评估指标(Bleu-4、Cider、Meteor和Rouge-L)将 MV-GPT 与现有的预训练损失进行比较。虽然所有预训练技术都能提高字幕性能,但联合预训练解码器对于提高模型性能至关重要。我们证明 MV-GPT 的表现比之前最先进的联合预训练方法高出 3.5% 以上,并且在所有四个指标上都有相对提升。
训练前损失 预训练部分 蓝-4 苹果酒 流星 胭脂-L
无需预先训练 不适用 13.25 1.03 17.56 35.48
心肌梗塞 编码器 14.46 1.24 18.46 37.17
统一VL 编码器+解码器 19.95 1.98 25.27 46.81
MV-GPT(我们的) 编码器+解码器 21.26 2.14 26.36 48.58
MV-GPT 在 YouCook2 上针对不同预训练损失的四个指标(Bleu-4、Cider、Meteor 和 Rouge-L)的表现。“预训练部分”表示模型的哪些部分是经过预训练的——仅编码器或编码器和解码器。我们重新实现了现有方法的损失函数,但使用我们的模型和训练策略进行公平比较。
我们将 MV-GPT 预训练的模型迁移到四个不同的字幕基准:YouCook2、MSR-VTT、ViTT和ActivityNet-Captions。我们的模型在所有四个基准上都取得了显著的领先优势,达到了最佳性能。例如,在 Meteor 指标上,MV-GPT 在所有四个基准上都显示出超过 12% 的相对改进。
YouCook2 MSR-VTT 维生素 D ActivityNet-标题
最佳基线 22.35 29.90 11.00 10.90
MV-GPT(我们的) 27.09 38.66 26.75 12.31
四个基准上最佳基线方法和 MV-GPT 的 Meteor 度量分数。
非生成性视频理解任务的结果
尽管 MV-GPT 旨在训练多模态视频字幕生成模型,但我们也发现,我们的预训练技术可以学习强大的多模态视频编码器,该编码器可应用于多种视频理解任务,包括 VideoQA、文本视频检索和动作分类。与最佳可比基线模型相比,从 MV-GPT 迁移的模型在五个视频理解基准的主要指标上表现出色——即 VideoQA 和动作分类基准的 Top-1准确率,以及检索基准的 1 召回率。
概括
我们引入了 MV-GPT,这是一种用于多模态视频字幕的新型生成预训练框架。我们的双向生成目标通过使用未标记视频中不同时间采样的话语来联合预训练多模态编码器和字幕解码器。我们的预训练模型在多个视频字幕基准和其他视频理解任务(即 VideoQA、视频检索和动作分类)上取得了最佳效果。
致谢
这项研究由 Paul Hongsuck Seo、Arsha Nagrani、Anurag Arnab 和 Cordelia Schmid 进行。
评论