稀疏模型是未来深度学习最有前途的方法之一。稀疏模型不是让模型的每个部分处理每个输入(“密集”建模),而是采用条件计算,学习将各个输入路由到可能庞大的网络中的不同“专家”。这有很多好处。首先,模型大小可以在保持计算成本不变的情况下增加——这是一种有效且环保的扩展模型的方式,而这往往是实现高性能的关键。稀疏性还可以自然地将神经网络划分为多个部分。同时(多任务)或顺序(持续学习)学习许多不同任务的密集模型经常会受到负面干扰,因为任务种类太多意味着最好每个任务只训练一个模型,或者发生灾难性遗忘,即随着新任务的增加,模型在早期任务上的表现会变得更糟。稀疏模型有助于避免这两种现象——通过不将整个模型应用于所有输入,模型中的“专家”可以专注于不同的任务或数据类型,同时仍然利用模型的共享部分。
Google Research 长期以来一直在进行稀疏性研究。Pathways总结了构建一个大型模型来勤奋处理数千个任务和众多数据模态的研究愿景。到目前为止,语言(Switch、Task-MoE 、 GLaM )和计算机视觉(Vision MoE )的稀疏单峰模型已经取得了长足的进步。今天,我们通过研究使用与模态无关的路由同时处理图像和文本的大型稀疏模型,向 Pathways 愿景迈出了重要的一步。一种相关的方法是多模态对比学习,它需要对图像和文本都有扎实的理解,以便将图片与正确的文本描述对齐。迄今为止,解决此任务的最强大的模型依赖于每种模态的独立网络(“双塔”方法)。
在“使用 LIMoE 进行多模态对比学习:语言图像专家混合”中,我们展示了第一个使用稀疏专家混合的大规模多模态架构。它同时处理图像和文本,但使用自然专业化的稀疏激活专家。在零样本图像分类中,LIMoE 的表现优于同类密集多模态模型和双塔方法。最大的 LIMoE 实现了 84.1% 的零样本ImageNet准确率,可与更昂贵的最先进模型相媲美。稀疏性使 LIMoE 能够优雅地扩展并学会处理非常不同的输入,解决了成为万事通通才和精通一门专家之间的矛盾。
LIMoE 架构包含许多“专家”,路由器决定哪些标记(图像或句子的部分)归哪个专家所有。经过专家层(灰色)和共享密集层(棕色)处理后,最终输出层会为图像或文本计算单个向量表示。
稀疏混合专家模型
Transformer将数据表示为向量序列(或token)。虽然最初是为文本开发的,但它们可以应用于大多数可以表示为 token 序列的内容,例如图像、视频和音频。最近的大规模 MoE 模型为 Transformer 架构添加了专家层(例如,自然语言处理中的gShard和ST-MoE,以及用于视觉任务的Vision MoE)。
标准 Transformer 由许多“块”组成,每个块包含各种不同的层。这些层之一是前馈网络 (FFN)。对于 LIMoE 和上面引用的作品,这个单个 FFN 被包含许多并行 FFN 的专家层取代,每个 FFN 都是一个专家。给定要处理的令牌序列,简单的路由器会学习预测哪些专家应该处理哪些令牌。每个令牌仅激活少数专家,这意味着虽然拥有如此多的专家可以显著增加模型容量,但实际计算成本可以通过稀疏使用它们来控制。如果只激活一名专家,则模型的成本大致相当于标准 Transformer 模型。
LIMoE 正是这样做的,每个示例激活一个专家,从而匹配密集基线的计算成本。不同之处在于 LIMoE 路由器可能会看到图像或文本数据的标记。
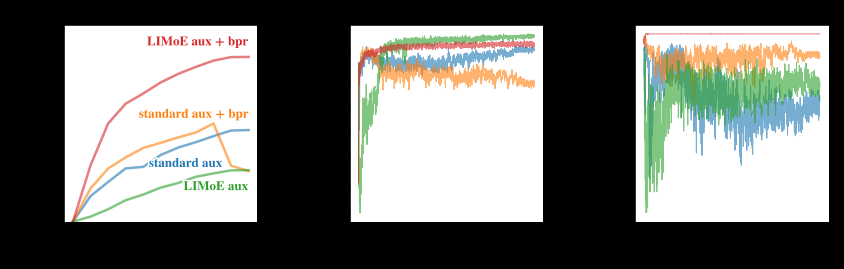
当 MoE 模型尝试将所有 token 发送给同一位专家时,就会出现一种独特的故障模式。通常,这可以通过辅助损失来解决,辅助损失是鼓励平衡使用专家的额外训练目标。我们发现,处理多种模态与稀疏性相互作用会导致现有辅助损失无法解决的新故障模式。为了克服这个问题,我们开发了新的辅助损失(更多详细信息请参阅论文)并在训练期间使用了路由优先级(BPR),这两项创新产生了稳定且高性能的多模态模型。
新的辅助损失(LIMoE aux)和路由优先级(BPR)稳定并改善了整体性能(左),并提高了路由行为的成功率(中和右)。低成功率意味着路由器不会使用所有可用的专家,并且由于达到单个专家的容量而丢弃许多令牌,这通常表明稀疏模型学习效果不佳。为 LIMoE 引入的组合可确保图像和文本的高路由成功率,从而显著提高性能。
使用 LIMoE 进行对比学习
在多模态对比学习中,模型在成对的图像文本数据(例如照片及其标题)上进行训练。通常,图像模型提取图像的表示,而不同的文本模型提取文本的表示。对比学习目标鼓励图像和文本表示对于相同的图像文本对接近,而对于不同对的内容远离。这种具有对齐表示的模型可以在没有额外训练数据的情况下适应新任务(“零样本”),例如,如果图像的表示比单词“猫”更接近单词“狗”的表示,则图像将被归类为狗。这个想法扩展到数千个类别,称为零样本图像分类。
CLIP和ALIGN(均为双塔模型)扩展了此过程,在流行的ImageNet数据集上实现了 76.2% 和 76.4% 的零样本分类准确率。我们研究了同时计算图像和文本表示的单塔模型。我们发现这会降低密集模型的性能,可能是由于负面干扰或容量不足。但是,计算匹配的 LIMoE 不仅比单塔密集模型有所改进,而且表现优于双塔密集模型。我们按照与 CLIP 类似的训练方案训练了一系列模型。我们的密集 L/16 模型实现了 73.5% 的零样本准确率,而 LIMoE-L/16 达到 78.6%,甚至超过了 CLIP 更昂贵的双塔 L/14 模型(76.2%)。如下所示,与成本相当的密集模型相比,LIMoE 对稀疏性的使用提供了显着的性能提升。
对于给定的计算成本(x 轴),LIMoE 模型(圆圈,实线)明显优于其密集基线(三角形,虚线)。架构表示底层变压器的大小,从左(S/32)到右(L/16)递增。按照标准惯例,S(小)、B(基)和 L(大)指的是模型规模。数字指的是补丁大小,其中较小的补丁意味着更大的架构。
LiT和BASIC将密集双塔模型的零样本准确率分别提高到 84.5% 和 85.6%。除了扩展之外,这些方法还利用了专门的预训练方法,重新利用了本来就质量极高的图像模型。LIMoE-H/14 并未受益于任何预训练或特定于模态的组件,但从头开始训练仍实现了相当的 84.1% 的零样本准确率。这些模型的规模也值得比较:LiT 和 BASIC 分别是 2.1B 和 3B 参数模型。LIMoE-H/14 总共有 5.6B 参数,但通过稀疏性,它每个 token 仅应用 675M 参数,使其显著减轻了重量。
训练期间看到的数据
模型 预训练 图文 全部的 每个 token 的参数 ImageNet 准确率
夹子 - 12.8亿 12.8亿 ~2亿 76.2%
对齐 - 19.8亿 19.8亿 ~4.1亿 76.4%
锂 25.8亿 18.2B 44.0亿 1.1B 84.5%
基本的 19.7B 32.8亿 52.5亿 15亿 85.6%
豪华轿车 H/14 - 23.3B 23.3B 6.75亿 84.1%
理解 LIMoE 的行为
LIMoE 的灵感来源于这样一种直觉:稀疏条件计算使通用多模态模型仍能发展出理解每种模态所需的专业化。我们分析了 LIMoE 的专家层,发现了一些有趣的现象。
首先,我们看到了专注于模态的专家的出现。在我们的训练设置中,图像标记比文本标记多得多,因此所有专家都倾向于处理至少一些图像,但有些专家要么主要处理图像,要么主要处理文本,或者两者兼而有之。
八位专家的 LIMoE 分布;百分比表示专家处理的图像标记数量。有一两位专家明显专注于文本(以蓝色专家为主),通常有两到四位图像专家(以红色为主),其余专家则处于中间位置。
图像专家之间也存在一些明显的定性模式——例如,在大多数 LIMoE 模型中,都有一个专家负责处理所有包含文本的图像块。在下面的例子中,一个专家负责处理动物和绿色植物,另一个专家负责处理人手。
LIMoE 为每个标记选择一位专家。这里我们展示了哪些图像标记在 LIMoE-H/14 的某一层上分配给哪些专家。尽管没有接受过这方面的培训,但我们观察到专门研究特定主题(例如植物或车轮)的语义专家的出现。
展望
处理多项任务的多模态模型是一条有前途的前进之路,成功的关键因素有两个:规模,以及避免不同任务和模态之间干扰并利用协同效应的能力。稀疏条件计算是实现这两点的绝佳方式。它使高性能和高效的通用模型成为可能,同时还具有在单个任务中脱颖而出所需的专业化能力和灵活性,正如 LIMoE 在较少计算量的情况下实现的稳定性能所证明的那样。
致谢
我们感谢本论文的合著者:Joan Puigcerver、Rodolphe Jenatton 和 Neil Houlsby。我们还要感谢 Andreas Steiner、Xiao Wang 和 Xiaohua Zhai,他们领导了对比多模态学习的密集单塔模型的早期探索,并且在提供数据访问方面发挥了重要作用。我们与 André Susano Pinto、Maxim Neumann、Barret Zoph、Liam Fedus、Wei Han、Daniel Keysers 和 Josip Djolonga 进行了有益的讨论。最后,我们还要感谢并感谢 Tom Small 在本篇文章中使用的精彩动画人物。
评论