人们的写作方式与说话方式不同。书面语言是经过控制和深思熟虑的,而自发性语音记录(如采访)则难以阅读,因为语音杂乱无章且不太流畅。语音记录特别难读的一个方面是不流畅,包括自我纠正、重复和填充停顿(例如,“嗯”和“你知道”这样的词)。以下是LDC CALLHOME 语料库中一个不流畅的口语句子的示例:
但那不是,那不是,那只是你刚才说的话的文字游戏。
理解这个句子需要一些时间——听者必须过滤掉多余的单词并解决所有的不流畅之处。消除不流畅之处会使句子更容易阅读和理解:
但这只不过是你刚才说的话的一个文字游戏。
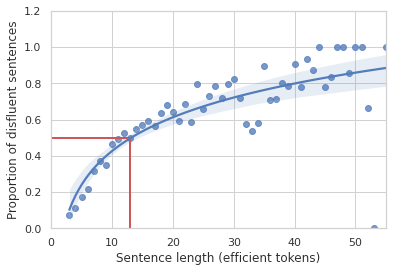
虽然人们通常不会注意到日常对话中的不流畅,但计算语言学的早期基础工作表明了不流畅是多么常见。1994 年,伊丽莎白·施里伯格 (Elizabeth Shriberg) 使用 Switchboard 语料库证明,一个包含 10-13 个单词的句子出现不流畅的概率为 50%,并且随着句子长度的增加,出现不流畅的概率也会增加。
Switchboard 数据集中至少有一个不流畅的句子比例与句子长度的关系图,以句子中不流畅(即有效)的标记来衡量。句子越长,包含不流畅的可能性就越大。
在“教 BERT 等待:平衡流式不流畅检测的准确性和延迟”中,我们介绍了如何“清理”口语文本记录的研究成果。我们通过查找和消除人们语音中的不流畅来创建更易读的人类语音记录和字幕。使用标记数据,我们创建了机器学习 (ML) 算法来识别人类语音中的不流畅之处。一旦识别出这些不流畅之处,我们就可以删除多余的单词以使记录更具可读性。这还可以提高处理人类语音记录的自然语言处理(NLP) 算法的性能。我们的工作特别重视确保这些模型能够在移动设备上运行,以便我们可以保护用户隐私并在连接性较差的情况下保持性能。
基础模型概述
我们的基础模型的核心是一个经过预训练的 BERT BASE编码器,它有 1.089 亿个参数。我们使用标准的每标记分类器配置,二进制分类头由每个标记的序列编码提供。
说明文本中的标记如何变成数字嵌入,然后导致输出标签。
我们通过继续对 2019 年Pushrift Reddit 数据集中 的评论进行预训练来改进 BERT 编码器。Reddit评论不是语音数据,但比 wiki 和书籍数据更非正式、更具对话性。这可以训练编码器更好地理解非正式语言,但可能会面临内化数据中固有的一些偏见的风险。然而,对于我们的特定用例,该模型仅捕获文本的语法或整体形式,而不是其内容,这避免了与数据中的语义级偏见相关的潜在问题。
我们对手动标记语料库(例如上文提到的Switchboard 语料库) 上的不流畅性分类模型进行了微调。使用Vizier优化了超参数(批量大小、学习率、训练周期数等)。
我们还使用一种称为“自我训练”的知识蒸馏技术 ,制作了一系列用于移动设备的“小型”模型。我们最好的小型模型基于具有 310 万个参数的Small-vocab BERT变体。这个较小的模型在 1% 的大小(以 MiB 为单位)下实现了与我们的基线相当的结果。您可以在我们的2021 年 Interspeech 论文中阅读有关我们如何实现此模型小型化的更多信息。
流媒体
自动语音转录的一些最新用例包括自动实时字幕,例如由 Android“实时字幕”功能生成的字幕,该功能可自动转录设备上正在播放的音频中的口语。为了在此设置下消除不流畅性以改善字幕的可读性,它必须快速且稳定地进行。也就是说,当模型在转录中看到新词时,它不应该改变其过去的预测。
我们将此称为实时逐个标记处理流式传输。由于时间依赖性,准确的流式传输很困难;大多数不流畅只能在之后才能识别。例如,直到第二次说出单词或短语时,重复才真正成为重复。
为了研究我们的不流畅检测模型在流式应用中是否有效,我们将训练集中的话语分成前缀段,其中在训练时仅提供话语的前N 个标记,对于N的所有值直到话语的整个长度。我们通过将前缀提供给模型并使用多个指标来衡量性能来模拟口头文本流,这些指标捕获模型准确性、稳定性和延迟,包括流式 F1、检测时间 (TTD)、编辑开销 (EO) 和平均等待时间 (AWT)。我们尝试了包含一个或两个标记的前瞻窗口,允许模型“提前查看”模型不需要生成预测的其他标记。本质上,我们要求模型在做出决定之前“等待”一两个证据标记。
虽然添加这种固定的前瞻性确实在许多情况下提高了稳定性和流式 F1 分数,但我们发现在某些情况下,即使没有前瞻性地查看下一个标记,标签也已经很清楚了,模型不一定能从等待中受益。其他时候,等待一个额外的标记就足够了。我们假设模型本身可以学习何时应该等待更多上下文。我们的解决方案是一种经过修改的模型架构,其中包括一个“等待”分类头,它决定模型何时已经看到足够的证据来信任不流畅分类头。
该图显示了模型如何在输入标记到达时对其进行标记。BERT 嵌入层将输入送入两个单独的分类头,然后将它们组合起来形成输出。
我们构建了一个训练损失函数,它是三个因素的加权和:
不流畅分类头的 传统交叉熵损失
交叉熵项仅考虑第一个带有“等待”分类的标记
延迟惩罚会阻止模型等待太长时间才做出预测
我们评估了这个流式模型以及没有前瞻和具有 1 个和 2 个标记前瞻值的标准基线:
流式 F1 得分与平均等待时间(以 token 为单位)的图表。三个数据点表示在多个等待时间内 F1 得分均高于 0.82。与固定前瞻模型相比,所提出的流式模型实现了接近顶级的性能,而等待时间却短得多。
流式模型的流式 F1 得分比没有前瞻的标准基线和前瞻为 1 的模型都要好。它的表现几乎与固定前瞻为 2 的变体一样好,但等待时间要少得多。平均而言,该模型仅等待 0.21 个上下文标记。
国际化
到目前为止,我们最好的成果是英语转录本。这主要是由于资源问题:虽然有许多相对较大的标记对话数据集包含英语不流利,但其他语言通常很少有这样的数据集。因此,为了使不流利检测模型在英语之外可用,需要一种方法来构建模型,而这种方法不需要在每种目标语言中查找和标记数十万条话语。一个有希望的解决方案是利用 BERT 的多语言版本将模型学到的关于英语不流利的知识转移到其他语言,以便在数据少得多的情况下实现类似的性能。这是一个活跃的研究领域,但我们确实有一些有希望的结果可以在此概述。
作为验证此方法的首次尝试,我们为来自德语 CALLHOME数据集的约 10,000 行对话添加了标签。然后,我们开始使用Geotrend 英语和德语双语 BERT模型(从多语言 BERT 中提取),并使用约 77,000 个不流畅标记的英语 Switchboard 示例和来自Fisher Corpus的 130 万个自标记转录本示例对其进行微调。然后,我们使用来自德语 CALLHOME 数据集的约 7,500 个内部标记的示例进行了进一步微调。
该图展示了我们最佳多语言训练设置中标记数据和自训练输出的流程。通过对英语和德语数据进行训练,我们能够通过迁移学习提高性能。
我们的结果表明,使用零样本迁移到德语等类似语言,对大型英语语料库进行微调可以产生可接受的精度,但至少需要适量的德语标签才能将召回率从不到 60% 提高到 80% 以上。对英德双语模型进行两阶段微调可产生最高的精度和整体 F1 分数。
方法 精确 记起 F1
德语 BERT BASE模型针对 7,300 个人工标记的德语 CALLHOME 示例进行了微调 89.1% 81.3% 85.0
与上文相同,但增加了 7,500 个自标德语 CALLHOME 示例 91.5% 83.3% 87.2
英语/德语双语 BERTbase 模型在英语 Switchboard+Fisher 上进行微调,在德语 CALLHOME(零样本语言迁移)上进行评估 87.2% 59.1% 70.4
与上述相同,但随后使用 14,800 个德语 CALLHOME(人类和自我标记)示例进行微调 95.5% 82.6% 88.6
结论
清除转录文本中的不流畅性不仅可以提高文本的可读性,还可以提高使用转录文本的其他模型的性能。我们展示了识别不流畅性的有效方法,并将我们的不流畅性模型扩展到资源受限的环境、新语言和更具交互性的用例。
致谢
感谢 Vicky Zayats、Johann Rocholl、Angelica Chen、Noah Murad、Dirk Padfield 和 Preeti Mohan 编写代码、运行实验并撰写本文讨论的论文。我们还要感谢我们的技术产品经理 Aaron Schneider、Cerebra Data Ops 团队的 Bobby Tran 和 Speech Data Ops 的 Chetan Gupta 为获取更多数据标签提供的支持。
评论