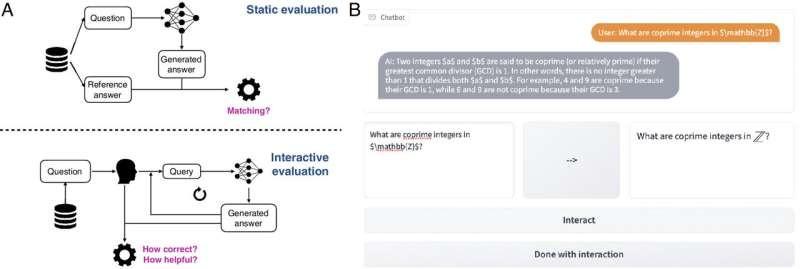
由剑桥大学领导的计算机科学家、工程师、数学家和认知科学家团队开发了一个名为 CheckMate 的开源评估平台,该平台允许人类用户与大型语言模型 (LLM) 进行交互并评估其性能。
研究人员在一项实验中测试了 CheckMate,其中人类参与者使用三个 LLM——InstructGPT、ChatGPT 和 GPT-4——作为解决本科数学问题的助手。
该团队研究了法学硕士 (LLM) 如何帮助参与者解决问题。尽管聊天机器人的正确性与感知帮助性之间通常呈正相关,但研究人员也发现了一些法学硕士不正确但对参与者仍然有用的情况。然而,参与者认为某些不正确的法学硕士输出是正确的。这在针对聊天优化的法学硕士中最为明显。
研究人员建议,如果模型能够传达不确定性,能够很好地响应用户的纠正,并能为其建议提供简明的理由,那么它们就能成为更好的助手。鉴于 LLM 目前存在的缺陷,人类用户应该仔细验证其输出。
该研究结果发表在美国科学院院刊上,它既可以为人工智能素养培训提供参考,也可以帮助开发人员改进 LLM 以用于更广泛的用途。
虽然法学硕士 (LLM) 变得越来越强大,但它们也可能犯错误并提供不正确的信息,这可能会随着这些系统越来越融入我们的日常生活而产生负面影响。
“法学硕士已经变得非常受欢迎,以量化的方式评估其表现非常重要,但我们还需要评估这些系统与人类合作和支持的效果,”共同第一作者、剑桥大学计算机科学与技术系的 Albert Jiang 表示。“我们还没有全面的方法来评估法学硕士在与人类互动时的表现。”
评估法学硕士的标准方法依赖于静态的输入和输出对,这忽略了聊天机器人的交互性质,以及这种性质如何改变它们在不同场景中的实用性。研究人员开发了 CheckMate 来帮助回答这些问题,其设计目的包括但不限于数学应用。
“当与数学家谈论法学硕士时,他们中的许多人主要分为两大阵营:要么他们认为法学硕士可以自己产生复杂的数学证明,要么认为法学硕士无法进行简单的算术,”来自工程系的共同第一作者凯蒂·柯林斯 (Katie Collins) 表示。“当然,事实可能介于两者之间,但我们希望找到一种方法来评估法学硕士适合哪些任务,哪些不适合。”
研究人员招募了 25 名数学家,从本科生到高级教授,与三名不同的 LLM(InstructGPT、ChatGPT 和 GPT-4)进行互动,并使用 CheckMate 评估他们的表现。参与者在 LLM 的帮助下完成了本科水平的数学定理,并被要求对每个 LLM 的回答的正确性和实用性进行评分。参与者不知道他们正在与哪位 LLM 互动。
本站全部资讯来源于实验室原创、合作机构投稿及网友汇集投稿,仅代表个人观点,不作为任何依据,转载联系作者并注明出处:https://www.lvsky.net/479.html
评论