代码日益复杂,对软件工程的生产力构成了重大挑战。代码补全已成为帮助缓解集成开发环境(IDE) 中这种复杂性的重要工具。传统上,代码补全建议是通过基于规则的语义引擎(SE) 实现的,这些引擎通常可以访问完整的存储库并了解其语义结构。最近的研究表明,大型语言模型(例如Codex和PaLM)可以提供更长、更复杂的代码建议,因此出现了一些有用的产品(例如Copilot )。然而,除了感知的生产力和接受的建议之外,机器学习 (ML) 驱动的代码补全如何影响开发人员的生产力,这一问题仍未得到解答。
今天,我们将介绍如何结合 ML 和 SE 来开发一种新颖的基于Transformer的混合语义 ML 代码补全,现在可供 Google 内部开发人员使用。我们讨论了如何通过 (1) 使用 ML 对 SE 单个标记建议重新排序,(2) 使用 ML 应用单行和多行补全并使用 SE 检查正确性,或 (3) 使用 ML 对单个标记语义建议进行单行和多行延续,来结合 ML 和 SE。我们将 10,000 多名 Google 员工(超过三个月,涉及八种编程语言)的混合语义 ML 代码补全与对照组进行比较,发现在使用单行ML 补全时,编码迭代时间(构建和测试之间的时间)减少了 6%。这些结果表明,ML 和 SE 的结合可以提高开发人员的工作效率。目前,3% 的新代码(以字符为单位)是通过接受 ML 补全建议生成的。
完成变压器
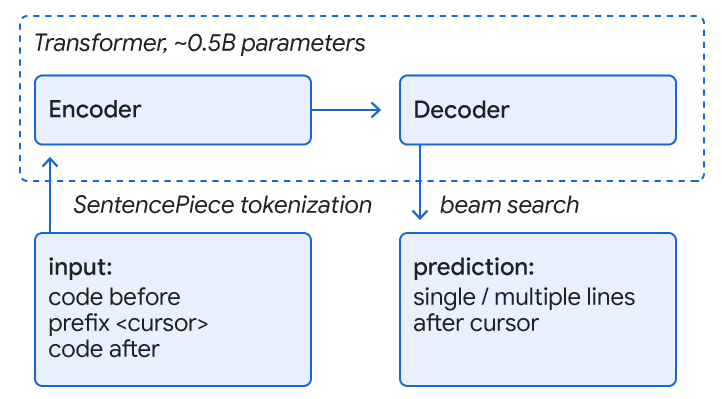
代码补全的一种常见方法是训练 Transformer 模型,该模型使用自注意力机制进行语言理解,以实现代码理解和补全预测。我们将代码视为类似于语言,用子词标记和SentencePiece词汇表表示,并使用在TPU上运行的编码器-解码器 Transformer 模型进行补全预测。输入是光标周围的代码(约 1000-2000 个标记),输出是一组用于完成当前或多行的建议。序列是通过解码器上的波束搜索(或树探索)生成的。
在 Google 的monorepo上进行训练时,我们会屏蔽一行的剩余部分和一些后续行,以模拟正在积极开发的代码。我们用八种语言(C++、Java、Python、Go、Typescript、Proto、Kotlin 和 Dart)训练一个模型,并观察到所有语言的性能都有所提高或持平,无需使用专用模型。此外,我们发现约 0.5B 个参数的模型大小在高预测精度与低延迟和资源成本之间取得了良好的平衡。该模型极大地受益于 monorepo 的质量,这是由指南和评论强制执行的。对于多行建议,我们迭代地应用单行模型和学习到的阈值来决定是否开始预测下一行的完成情况。
编码器-解码器变换器模型用于预测代码行的剩余部分。
使用机器学习对单个标记建议进行重新排序
当用户在 IDE 中输入时,后端会同时以交互方式从 ML 模型和 SE 请求代码完成。SE 通常只预测一个标记。我们使用的 ML 模型会预测多个标记,直到行尾,但我们只考虑第一个标记以匹配 SE 的预测。我们确定 SE 建议中也包含的前三个 ML 建议,并将其排名提升到顶部。然后,重新排名的结果会在 IDE 中显示为用户的建议。
实际上,我们的 SE 在云端运行,提供开发人员熟悉的语言服务(例如语义补全、诊断等),因此我们将 SE 并置在与执行 ML 推理的 TPU 相同的位置上运行。SE 基于内部库,该库提供类似编译器的功能,且延迟低。由于设计设置,请求是并行完成的,并且 ML 通常服务速度更快(中位数约为 40 毫秒),我们不会在补全中添加任何延迟。我们观察到实际使用中质量显著提高。对于 28% 的已接受补全,由于提升,补全的排名更高,而在 0.4% 的情况下排名更差。此外,我们发现用户在接受补全建议之前输入的字符减少了 10% 以上。
检查单行/多行 ML 补全的语义正确性
在推理时,ML 模型通常无法识别输入窗口之外的代码,训练期间看到的代码可能会错过在不断变化代码库中完成代码所需的最新添加内容。这导致了 ML 驱动的代码完成的一个常见缺陷,即模型可能会建议看起来正确但无法编译的代码。根据内部用户体验研究,这个问题可能会导致用户信任度随着时间的推移而下降,同时降低生产率。
我们使用 SE 在给定的延迟预算内(端到端完成时间小于 100 毫秒)执行快速语义正确性检查,并使用缓存的抽象语法树来实现“完整”的结构理解。典型的语义检查包括引用解析(即,此对象是否存在)、方法调用检查(例如,确认方法调用时带有正确数量的参数)和可分配性检查(确认类型符合预期)。
例如,对于编码语言Go,在语义检查之前,约 8% 的建议包含编译错误。但是,语义检查的应用过滤掉了 80% 的不可编译建议。在引入该功能的前六周内,单行补全的接受率提高了 1.9 倍,这可能是由于用户信任度的提高。相比之下,对于我们没有添加语义检查的语言,我们只看到接受率提高了 1.3 倍。
可以访问源代码的语言服务器和 ML 后端共置在云端。它们都对 ML 补全建议进行语义检查。
结果
有 10,000 多名 Google 内部开发人员在其 IDE 中使用补全设置,我们测量到的用户接受率为 25-34%。我们确定基于转换器的混合语义 ML 代码补全可完成 3% 以上的代码,同时将 Google 员工的编码迭代时间缩短 6%(置信度为 90%)。转变的大小对应于通常仅影响一小部分人群的转换特征(例如关键框架)的典型影响,而 ML 有可能适用于大多数主要语言和工程师。
ML 添加的所有代码的比例 2.6%
减少编码迭代持续时间 6%
接受率(针对可见时间 >750 毫秒的建议) 25%
每次接受的平均字符数 21
超过 10,000 名 Google 内部开发人员在日常开发中使用八种语言来测量单行代码完成的关键指标。
ML 添加的所有代码的分数(建议中有 >1 行) 0.6%
每次接受的平均字符数 73
接受率(针对可见时间 >750 毫秒的建议) 34%
在 5,000 多名 Google 内部开发人员在日常开发中使用八种语言进行多行代码完成的关键指标的生产测量中。
在探索 API 时提供长补全
我们还将语义补全与全行补全紧密集成。当出现包含语义单个标记补全的下拉列表时,我们会内联显示从 ML 模型返回的单行补全。后者表示下拉列表焦点项的延续。例如,如果用户查看 API 的可能方法,内联全行补全会显示完整的方法调用,还包含调用的所有参数。
通过 ML 集成的全行补全继续关注语义下拉补全。
ML 的多行完成建议。
结论和未来工作
我们展示了如何结合使用基于规则的语义引擎和大型语言模型来显著提高开发人员的工作效率,并实现更好的代码完成。下一步,我们希望通过在推理时向 ML 模型提供额外信息来进一步利用 SE。一个例子是长期预测在 ML 和 SE 之间来回传递,其中 SE 会反复检查正确性并向 ML 模型提供所有可能的延续。在添加由 ML 提供支持的新功能时,我们希望注意超越“智能”结果,确保对生产力产生积极影响。
致谢
这项研究是 Google Core 与 Google Research 和 Brain Team 两年合作的成果。特别感谢 Marc Rasi、Yurun Shen、Vlad Pchelin、Charles Sutton、Varun Godbole、Jacob Austin、Danny Tarlow、Benjamin Lee、Satish Chandra、Ksenia Korovina、Stanislav Pyatykh、Cristopher Claeys、Petros Maniatis、Evgeny Gryaznov、Pavel Sychev、Chris Gorgolewski、Kristof Molnar、Alberto Elizondo、Ambar Murillo、Dominik Schulz、David Tattersall、Rishabh Singh、Manzil Zaheer、Ted Ying、Juanjo Carin、Alexander Froemmgen、Maxim Kachurovskiy 和 Marcus Revaj 的贡献。
评论