用于视觉任务(例如图像分类)的深度学习模型通常使用来自单个视觉域(例如自然图像或计算机生成的图像)的数据进行端到端训练。通常,完成多个域的视觉任务的应用程序需要为每个单独的域构建多个模型,独立训练它们(意味着域之间没有共享数据),然后在推理时每个模型都会处理特定于域的输入数据。然而,这些模型之间的早期层会生成相似的特征,即使对于不同的域也是如此,因此联合训练多个域可以更有效率 - 降低延迟和功耗,降低存储每个模型参数的内存开销,这种方法称为多域学习 (MDL)。此外,由于正向知识转移,MDL 模型还可以胜过单域模型,即在一个域上进行额外训练实际上会提高另一个域的性能。相反,也可能出现负向知识转移,具体取决于所涉及的方法和特定域组合。虽然之前对 MDL 的研究已经证明了跨多个领域联合学习任务的有效性,但它涉及手工制作的模型架构,而这种架构应用于其他工作效率低下。
在“用于设备上多域视觉分类的多路径神经网络”中,我们提出了一种通用的 MDL 模型,它可以:1)高效实现高精度(保持参数数量和FLOPS较低),2)学习增强正向知识传递,同时减轻负向传递,3)有效优化联合模型,同时处理各种特定领域的困难。因此,我们提出了一种多路径神经架构搜索(MPNAS) 方法来构建具有异构网络架构的统一模型,用于多个领域。MPNAS 通过联合为每个域寻找最佳路径,将高效的神经架构搜索 (NAS) 方法从单路径搜索扩展到多路径搜索。此外,我们引入了一种新的损失函数,称为自适应平衡域优先级 (ABDP),它可以适应特定领域的困难,帮助高效地训练模型。由此产生的 MPNAS 方法高效且可扩展;与单域方法相比,所得模型在保持性能的同时,将模型大小和 FLOPS 分别减少了 78% 和 32%。
多路径神经架构搜索
为了鼓励积极的知识转移并避免消极的转移,传统的解决方案是构建一个 MDL 模型,以便各个领域共享学习共享特征的大多数层(称为特征提取),然后在顶部添加一些特定于领域的层。然而,这种同质的特征提取方法无法处理具有显著不同特征的领域(例如,自然图像和艺术画作中的对象)。另一方面,为每个 MDL 模型手工制作统一的异构架构非常耗时,并且需要特定领域的知识。
NAS是用于自动设计深度学习架构的强大范例。它定义了一个搜索空间,由可能成为最终模型一部分的各种潜在构建块组成。搜索算法从搜索空间中找到最佳候选架构,以优化模型目标(例如分类准确性)。最近的 NAS 方法(例如TuNAS )通过使用端到端路径采样显著提高了搜索效率,这使我们能够将 NAS 从单个域扩展到 MDL。
受 TuNAS 的启发,MPNAS 分两个阶段构建 MDL 模型架构:搜索和训练。在搜索阶段,为了共同为每个域找到一条最佳路径,MPNAS 为每个域创建一个单独的强化学习 (RL) 控制器,该控制器从超网络(即搜索空间定义的候选节点之间所有可能子网络的超集)中采样一条端到端路径(从输入层到输出层)。经过多次迭代,所有 RL 控制器都会更新路径以优化所有域中的RL 奖励。在搜索阶段结束时,我们为每个域获得一个子网络。最后,将所有子网络组合起来,为 MDL 模型构建一个异构架构,如下所示。
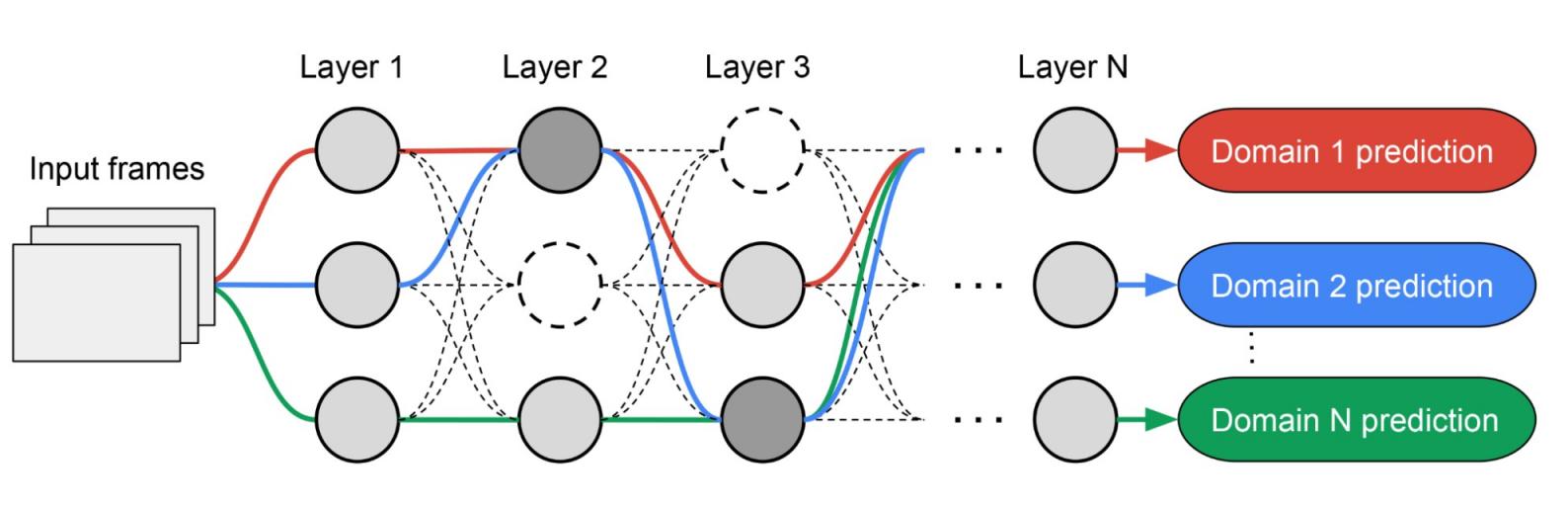
由于每个域的子网络都是独立搜索的,因此每层中的构建块可以由多个域共享(即深灰色节点),由单个域使用(即浅灰色节点),或者不由任何子网络使用(即虚线节点)。每个域的路径还可以在搜索期间跳过任何层。鉴于子网络可以自由选择沿路径使用哪些块以优化性能(而不是任意指定哪些层是同质的,哪些层是特定于域的),输出网络既是异构的又是高效的。
MPNAS 搜索的示例架构。虚线路径表示所有可能的子网络。实线路径表示每个域的选定子网络(以不同颜色突出显示)。每层中的节点表示搜索空间定义的候选构建块。
下图展示了视觉领域十项全能挑战赛十个领域中两个视觉领域的搜索架构。可以看出,这两个高度相关的领域(一个为红色,另一个为绿色)的子网络从重叠路径上共享了大部分构建块,但仍存在一些差异。
视觉领域十项全能挑战赛十个领域中两个领域( ImageNet和Describable Textures )的架构块。红色和绿色路径分别表示ImageNet和Describable Textures的子网络。深粉色节点表示多个领域共享的块。浅粉色节点表示每个路径使用的块。该模型基于MobileNet V3 类搜索空间构建。图中的“dwb”块表示dwbottleneck块。图中的“zero”块表示子网络跳过该块。
下面我们展示了视觉领域十项全能挑战赛 十个领域之间的路径相似性。相似性通过每个领域子网络之间的Jaccard 相似度得分来衡量,得分越高表示路径越相似。正如人们所预料的那样,更相似的领域在 MPNAS 生成的路径中共享更多节点,这也是强烈正向知识转移的信号。例如,相似领域的路径(如ImageNet、CIFAR-100和VGG Flower,它们都包含自然图像中的对象)得分较高,而不同领域的路径(如戴姆勒行人分类和UCF101 动态图像,分别包含灰度图像中的行人和自然彩色图像中的人类活动)得分较低。
十个域的路径之间的 Jaccard 相似度得分的混淆矩阵。得分值范围为 0 到 1。值越大表示两条路径共享的节点越多。
训练异构多领域模型
在第二阶段,MPNAS 产生的模型会针对所有领域从头开始进行训练。要做到这一点,必须为所有领域定义一个统一的目标函数。为了成功处理各种各样的领域,我们设计了一种在整个学习过程中不断适应的算法,以使损失在各个领域之间保持平衡,这种算法称为自适应平衡领域优先级 (ABDP)。
下面我们展示了在不同设置下训练的模型的准确率、模型大小和 FLOPS。我们将 MPNAS 与其他三种方法进行了比较:
领域独立 NAS:为每个领域分别搜索和训练模型。
单路径多头:使用预先训练的模型作为所有域的共享主干,每个域有分开的分类头。
多头 NAS:为所有域寻找统一的骨干架构,每个域有独立的分类头。
从结果中我们可以看出,领域独立 NAS需要为每个领域构建一组模型,从而导致模型大小较大。虽然单路径多头和多头 NAS可以显著减少模型大小和 FLOPS,但强制领域共享相同的主干会引入负面知识转移,从而降低整体准确性。
模型 参数个数比 每秒千万亿次浮点运算 平均 Top-1 准确率
域独立 NAS 5.7x 1.08 69.9
单路多头 1.0x 0.09 35.2
多头 NAS 0.7x 0.04 45.2
网络存储服务 1.3x 0.73 71.8
Visual Decathlon 数据集上 MDL 模型的参数数量、gigaFLOPS 和 Top-1 准确率(%)。所有方法均基于类似 MobileNetV3 的搜索空间构建。
MPNAS 可以构建一个小型而高效的模型,同时仍保持较高的整体准确率。MPNAS 的平均准确率甚至比领域独立的 NAS方法 高出 1.9%,因为该模型能够实现积极的知识转移。下图比较了这些方法在每个领域的top-1 准确率。
每个视觉十项全能领域的 Top-1 准确率。
我们的评估表明,通过在搜索和训练阶段使用 ABDP,top-1 准确率从 69.96% 提高到 71.78%(增量:+1.81%)。
使用和不使用 ABDP 的 MPNAS 训练的每个 Visual Decathlon 域的 Top-1 准确率。
未来工作
我们发现 MPNAS 是一种构建异构网络的有效解决方案,可以解决 MDL 中可能存在的参数共享策略的数据不平衡、领域多样性、负迁移、领域可扩展性和大搜索空间等问题。通过使用类似 MobileNet 的搜索空间,生成的模型也适用于移动设备。我们将继续扩展 MPNAS 以用于与现有搜索算法不兼容的任务的多任务学习,并希望其他人可以使用 MPNAS 构建统一的多领域模型。
致谢
这项工作是 Google 多个团队通力合作的结果。我们非常感谢 Junjie Ke、Joshua Greaves、Grace Chu、Ramin Mehran、Gabriel Bender、Xuhui Jia、Brendan Jou、Yukun Zhu、Luciano Sbaiz、Alec Go、Andrew Howard、Jeff Gilbert、Peyman Milanfar 和 Ming-Hsuan Yang 的贡献。
评论