排名是各种领域(如搜索引擎、推荐系统或问答系统)的核心问题。因此,研究人员经常使用排名学习(LTR),这是一组监督机器学习技术,可优化整个项目列表(而不是一次单个项目)的效用。最近一个明显的重点是将 LTR 与深度学习相结合。现有的库(最著名的是TF-Ranking )为研究人员和从业人员提供了在工作中使用 LTR 的必要工具。但是,现有的 LTR 库都不能与JAX原生兼容,JAX 是一种新的机器学习框架,它提供了一个可扩展的函数转换系统,包括:自动微分、GPU/TPU 设备的 JIT 编译等。
今天,我们很高兴地推出Rax,这是 JAX 生态系统中的 LTR 库。Rax 将数十年的 LTR 研究带入 JAX 生态系统,使 JAX 能够应用于各种排名问题,并将排名技术与基于 JAX 的深度学习的最新进展相结合(例如T5X)。Rax 提供了最先进的排名损失、许多标准排名指标和一组函数转换,以实现排名指标优化。所有这些功能都提供了一个文档齐全且易于使用的 API,JAX 用户会觉得它很熟悉。请查看我们的论文了解更多技术细节。
使用 Rax 进行排名学习
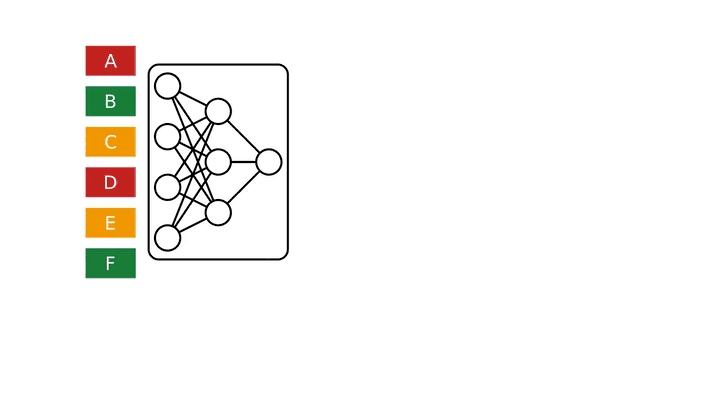
Rax 旨在解决 LTR 问题。为此,Rax 提供了对列表批次进行操作的损失和度量函数,而不是像其他机器学习问题中常见的那样对单个数据点批次进行操作。这种列表的一个例子是搜索引擎查询的多个潜在结果。下图说明了如何使用 Rax 的工具来训练神经网络进行排名任务。在这个例子中,绿色项目(B、F)非常相关,黄色项目(C、E)有点相关,红色项目(A、D)不相关。神经网络用于预测每个项目的相关性分数,然后根据这些分数对这些项目进行排序以产生排名。Rax 排名损失结合了整个分数列表来优化神经网络,从而提高项目的整体排名。经过几次随机梯度下降迭代后,神经网络学会对项目进行评分,以使最终排名达到最佳:相关项目放在列表顶部,不相关项目放在底部。
使用 Rax 优化神经网络以完成排序任务。绿色项目(B、F)非常相关,黄色项目(C、E)有些相关,红色项目(A、D)不相关。
近似度量优化
排名的质量通常使用排名指标来评估,例如归一化折扣累积增益(NDCG)。LTR 的一个重要目标是优化神经网络,使其在排名指标上得分很高。但是,像 NDCG 这样的排名指标会带来挑战,因为它们通常不连续且平坦,所以随机梯度下降不能直接应用于这些指标。Rax 提供了最先进的近似技术,可以生成排名指标的可微替代值,从而允许通过梯度下降进行优化。下图说明了使用rax.approx_t12nRax 独有的函数转换,它允许将 NDCG 指标转换为近似和可微的形式。
使用 Rax 的近似技术将 NDCG 排名指标转换为可微分和可优化的排名损失(approx_t12n和gumbel_t12n)。
首先,请注意 NDCG 指标(绿色)是平坦且不连续的,这使得使用随机梯度下降法进行优化变得困难。通过rax.approx_t12n对指标进行变换,我们得到了ApproxNDCG,这是一个近似指标,现在可以通过明确定义的梯度(红色)进行微分。然而,它可能有许多局部最优点——损失是局部最优的点,但不是全局最优的点——训练过程可能会在这些点上停滞不前。当损失遇到这样的局部最优时,像随机梯度下降这样的训练程序将很难进一步改善神经网络。
为了克服这个问题,我们可以使用转换获得ApproxNDCG 的 gumbel 版本rax.gumbel_t12n。这个 gumbel 版本在排名分数中引入了噪音,导致损失对许多不同的排名进行抽样,从而产生非零成本(蓝色)。这种随机处理可能有助于损失摆脱局部最优,并且通常是在排名指标上训练神经网络时更好的选择。Rax 在设计上允许近似和 gumbel 转换自由地与库提供的所有指标一起使用,包括具有top-k 截止值的指标,如召回率或准确率。事实上,甚至可以实现你自己的指标并对其进行转换以获得允许优化的 gumbel 近似版本,而无需任何额外的努力。
JAX 生态系统排名
Rax 旨在与 JAX 生态系统很好地集成,我们优先考虑与其他基于 JAX 的库的互操作性。例如,使用 JAX 的研究人员的常见工作流程是使用TensorFlow Datasets加载数据集、使用Flax构建神经网络以及使用Optax优化网络参数。这些库中的每一个都可以与其他库很好地组合,这些工具的组合使得使用 JAX 既灵活又强大。对于排名系统的研究人员和从业者来说,JAX 生态系统以前缺少 LTR 功能,而 Rax 通过提供排名损失和指标的集合来填补这一空白。我们精心构建了 Rax,使其能够与标准 JAX 转换(例如和)jax.jit以及jax.grad各种库(例如 Flax 和 Optax)一起原生运行。这意味着用户可以自由地将他们最喜欢的 JAX 和 Rax 工具一起使用。
T5排名
虽然T5 等大型语言模型在自然语言任务上表现出色,但如何利用排名损失来提高其在搜索或问答等排名任务上的表现仍未得到充分探索。借助 Rax,可以充分挖掘这一潜力。Rax 是作为 JAX-first 库编写的,因此很容易将其与其他 JAX 库集成。由于T5X是 JAX 生态系统中 T5 的实现,因此 Rax 可以与其无缝协作。
为此,我们举了一个例子来说明如何在 T5X 中使用 Rax。通过结合排名损失和指标,现在可以针对排名问题对 T5 进行微调,我们的结果表明,使用排名损失增强 T5 可以显著提高性能。例如,在MS-MARCO QNA v2.1基准测试中,我们能够通过使用 Rax 列表式 softmax交叉熵损失(而不是逐点S 形交叉熵损失) 对 T5-Base 模型进行微调,从而实现 +1.2% NDCG 和 +1.7% MRR 。
使用排名损失(softmax,蓝色)和非排名损失(逐点 sigmoid,红色)在 MS-MARCO QNA v2.1 上对 T5-Base 模型进行微调。
结论
总体而言,Rax 是不断壮大的 JAX 库生态系统的新成员。Rax 完全开源,可在github.com/google/rax上供所有人使用。更多技术细节也可以在我们的论文中找到。我们鼓励大家探索github 存储库中包含的示例: (1)使用 Flax 和 Optax 优化神经网络,(2)比较不同的近似度量优化技术,以及(3)如何将 Rax 与 T5X 集成。
致谢
谷歌内部的许多合作者使得该项目成为可能:Xuanhui Wang、Zhen Qin、Le Yan、Rama Kumar Pasumarthi、Michael Bendersky、Marc Najork、Fernando Diaz、Ryan Doherty、Afroz Mohiuddin和 Samer Hassan。
评论