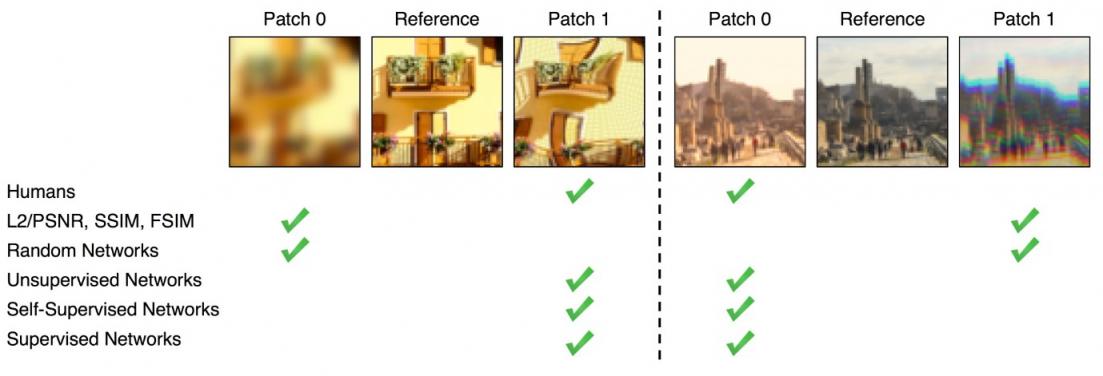
确定图像之间的相似性是计算机视觉领域的一个未解决的问题,对于评估机器生成图像的真实度至关重要。虽然有许多直接的方法可以估计图像相似性(例如,测量像素差异的低级指标,如 FSIM和SSIM ),但在许多情况下,测量到的相似性差异与人感知到的差异并不匹配。然而,最近的研究表明,在ImageNet上训练的神经网络分类器的中间表示(如AlexNet、VGG和SqueezeNet)表现出感知相似性作为一种突现属性。也就是说,与直接从图像像素估计感知相似性相比,ImageNet 训练模型的图像编码表示之间的欧几里得距离与人对图像之间差异的判断具有更好的相关性。
来自BAPPS 数据集的两组样本图像。与低级指标(PSNR、 SSIM 、 FSIM )相比,训练有素的网络与人类判断更加一致。图片来源:Zhang et al. (2018)。
在《机器学习研究汇刊》上发表的 “更好的 ImageNet 分类器是否能更好地评估感知相似性? ”一文中,我们对 ImageNet 分类器的准确性与其捕捉感知相似性的新兴能力之间的关系进行了广泛的实验研究。为了评估这种新兴能力,我们遵循了以前的工作来测量感知分数 (PS),这大致是人类偏好与BAPPS 数据集上图像相似性模型的偏好之间的相关性。虽然之前的研究研究了第一代 ImageNet 分类器,如 AlexNet、SqueezeNet 和 VGG,但我们显著扩大了分析范围,将现代分类器(如ResNets和Vision Transformers (ViTs))纳入了广泛的超参数。
准确度和感知相似度之间的关系
众所周知,通过 ImageNet 训练学习到的特征可以很好地迁移到许多下游 任务,这使得 ImageNet 预训练成为一种标准方法。此外,ImageNet 上更高的准确度通常意味着在一系列不同的下游任务上表现更好,例如对常见损坏的鲁棒性、分布外 泛化和较小分类数据集上的迁移学习。与普遍认为在 ImageNet 上具有高验证准确度的模型可能更好地迁移到其他任务的证据相反,令人惊讶的是,我们发现来自具有中等验证准确度的欠拟合 ImageNet 模型的表示获得了最佳感知分数。
64 × 64 BAPPS 数据集上的感知分数 (PS) (y 轴)与ImageNet 64 × 64 验证准确率(x 轴)的对比图。每个蓝点代表一个 ImageNet 分类器。更好的 ImageNet 分类器在某个点(深蓝色)之前可实现更好的 PS,超过该点后,提高准确率会降低 PS。最佳 PS 由具有中等准确率(20.0–40.0)的分类器实现。
我们研究感知分数随神经网络超参数变化的情况:宽度、深度、训练步数、权重衰减、标签平滑和dropout。对于每个超参数,都存在一个最佳准确度,在此范围内提高准确度可以提高 PS。这个最佳值相当低,并且在超参数扫描的早期就达到了。超过这个点,分类器准确度的提高对应着更差的 PS。
为了说明,我们展示了 PS 相对于两个超参数的变化:ResNets 中的训练步骤和 ViTs 中的宽度。ResNet-50 和 ResNet-200 的 PS 在训练的前几个时期很早就达到峰值。峰值过后,更好分类器的 PS 下降幅度更大。ResNets 的训练采用学习率计划,该计划导致准确率随着训练步骤逐步提高。有趣的是,在峰值过后,它们还表现出 PS 的逐步下降,与准确率的逐步提高相匹配。
早期停止的 ResNets 在 6、50 和 200 的不同深度上获得了最佳 PS。
ViT 由应用于输入图像的变压器块堆栈组成。ViT 模型的宽度是单个变压器块的输出神经元数量。增加其宽度是提高其准确性的有效方法。在这里,我们改变了两个 ViT 变体 B/8 和 L/4(即,分别具有 4 和 8 的补丁大小的 Base 和 Large ViT 模型)的宽度,并评估了准确性和 PS。与我们对早期停止的 ResNet 的观察结果类似,准确度较低的较窄 ViT 的表现优于默认宽度。令人惊讶的是,ViT-B/8 和 ViT-L/4 的最佳宽度分别是其默认宽度的 6% 和 12%。有关涉及 ResNets 和 ViT 中的其他超参数(例如宽度、深度、训练步数、权重衰减、标签平滑和 dropout)的更全面的实验列表,请查看我们的论文。
狭窄的 ViT 可获得最佳 PS。
缩小模型可提高感知分数
我们的结果规定了一种简单的策略来提高架构的 PS:缩小模型以降低其准确率,直到达到最佳感知分数。下表总结了通过缩小每个超参数的每个模型获得的 PS 改进。除了 ViT-L/4,无论架构如何,早期停止都能产生最高的 PS 改进。此外,早期停止是最有效的策略,因为不需要昂贵的网格搜索。
模型 默认 宽度 深度 权重
衰减 中央
作物 训练
步骤 最好的
ResNet-6 69.1 +0.4 - +0.3 0.0 +0.5 69.6
ResNet-50 68.2 +0.4 - +0.7 +0.7 +1.5 69.7
ResNet-200 67.6 +0.2 - +1.3 +1.2 +1.9 69.5
维生素 B/8 67.6 +1.1 +1.0 +1.3 +0.9 +1.1 68.9
维生素 L/4 67.9 +0.4 +0.4 -0.1 -1.1 +0.5 68.4
通过缩小 ImageNet 模型,感知分数会有所提高。每个值表示通过缩小给定超参数的模型相对于具有默认超参数的模型所获得的改进。
整体感知功能
在先前的工作中,感知相似性函数是使用图像空间维度上的欧几里得距离计算的。这假设像素之间存在直接对应关系,但对于扭曲、平移或旋转的图像,这可能不成立。相反,我们采用两个依赖于图像全局表示的感知函数,即来自神经风格迁移工作的风格损失函数(可捕捉两幅图像之间的风格相似性)和归一化均值池距离函数。风格损失函数比较两幅图像之间的通道间互相关矩阵,而均值池函数比较空间平均的全局表示。
全局感知函数在使用默认超参数训练的网络(顶部)和 ResNet-200 中作为训练周期函数(底部)持续改善 PS。
我们探讨了许多假设来解释准确率和 PS 之间的关系,并得出了一些额外的见解。例如,没有常用跳跃连接的模型的准确率也与 PS 呈负相关,并且与靠近输出的层相比,靠近输入的层的平均 PS 较低。有关涉及失真灵敏度、ImageNet 类粒度和空间频率灵敏度的进一步探索,请查看我们的论文。
结论
在本文中,我们探讨了提高分类准确率是否会产生更好的感知指标的问题。我们研究了 ResNets 和 ViT 上许多不同超参数的准确率和 PS 之间的关系,并观察到 PS 与准确率呈现倒 U 关系,其中准确率与 PS 相关到某一点,然后呈现反相关。最后,在我们的论文中,我们详细讨论了准确率和 PS 之间观察到的关系的多种解释,包括跳过连接、全局相似性函数、失真敏感度、分层感知分数、空间频率敏感度和 ImageNet 类粒度。虽然 ImageNet 准确率和感知相似性之间观察到的权衡的确切解释是一个谜,但我们很高兴我们的论文为该领域的进一步研究打开了大门。
致谢
这是与 Neil Houlsby 和 Nal Kalchbrenner 的合作。我们还要感谢 Basil Mustafa、Kevin Swersky、Simon Kornblith、Johannes Balle、Mike Mozer、Mohammad Norouzi 和 Jascha Sohl-Dickstein 的有益讨论。
评论