广告技术提供商广泛使用机器学习 (ML) 模型来预测和向用户展示最相关的广告,并衡量这些广告的有效性。随着对在线隐私的日益关注,我们有机会找到具有更好的隐私效用权衡的 ML 算法。差分隐私(DP) 已成为一种流行的框架,用于以可证明的隐私保证负责任地开发 ML 算法。它已在隐私文献中得到广泛研究,并已部署在工业应用中,并被美国人口普查所采用。直观地说,DP 框架使 ML 模型能够学习全民属性,同时保护用户级信息。
在训练 ML 模型时,算法将数据集作为输入,并生成经过训练的模型作为输出。随机梯度下降(SGD) 是一种常用的非私有训练算法,它从一组随机示例子集(称为小批量)计算平均梯度,并使用它来指示模型应朝哪个方向移动以适应该小批量。深度学习中最广泛使用的 DP 训练算法是 SGD 的扩展,称为DP 随机梯度下降(DP-SGD)。
DP-SGD 包括两个附加步骤:1)在求平均之前,如果梯度的L2 范数超过预定义阈值,则对每个示例的梯度进行范数剪裁;2)在更新模型之前,将高斯噪声添加到平均梯度中。通过将优化器(如 SGD 或Adam)替换为它们的 DP变体,DP-SGD 可以以最小的改动适应任何现有的深度学习流程。然而,在实践中应用 DP-SGD 可能会导致模型效用(即准确性)的显著损失,并且计算开销很大。因此,各种研究尝试将 DP-SGD 训练应用于更实际、更大规模的深度学习问题。最近的研究还表明,DP 训练在计算机 视觉和自然语言 处理问题上取得了有希望的结果。
在“使用 DP-SGD 进行隐私广告建模”中,我们系统地研究了 DP-SGD 在广告建模问题上的训练,与视觉和语言任务相比,这带来了独特的挑战。广告数据集的数据类别之间通常存在高度不平衡,并且由具有大量唯一值的分类特征组成,导致模型具有较大的嵌入层和高度稀疏的梯度更新。通过这项研究,我们证明了 DP-SGD 允许广告预测模型以比之前预期的更小的效用差距进行隐私训练,即使在高度隐私的制度下也是如此。此外,我们证明,通过适当的实施,可以显著减少 DP-SGD 训练的计算和内存开销。
评估
我们使用三个广告预测任务来评估私人训练:(1)预测广告的点击率 (pCTR),(2)预测点击后广告的转化率 (pCVR),以及 3)预测点击广告后的预期转化次数 (pConvs)。对于 pCTR,我们使用Criteo数据集,它是 pCTR 模型广泛使用的公共基准。我们使用内部 Google 数据集评估 pCVR 和 pConvs。pCTR 和 pCVR 是使用二元交叉熵损失训练的二元分类问题,我们报告测试AUC损失(即 1 - AUC)。pConvs 是一个使用泊松对数损失(PLL)训练的回归问题,我们报告测试 PLL。
对于每项任务,我们通过不同隐私预算下私人训练模型的损失相对增加(即隐私损失)来评估 DP-SGD 的隐私效用权衡。隐私预算用标量ε表示,其中较低的ε表示较高的隐私。为了衡量私人和非私人训练之间的效用差距,我们计算了与非私人模型相比的损失相对增加(相当于ε = ∞)。我们的主要观察是,在所有三个常见的广告预测任务中,即使在非常高的隐私(例如,ε <= 1)制度下,相对损失的增加也可以比之前预期的要小得多。
DP-SGD 在三个广告预测任务上的结果。损失的相对增加是根据每个任务的非隐私基线(即ε = ∞)模型计算的。
改进隐私会计
隐私核算在给定高斯噪声乘数和其他训练超参数的情况下, 估算 DP-SGD 训练模型的隐私预算 ( ε )。自原始论文发表以来,Rényi 差分隐私(RDP) 核算一直是 DP-SGD 中最广泛使用的方法。我们探索核算方法的最新进展,以提供更严格的估算。具体来说,我们使用基于隐私损失分布(PLD) 的连接点进行核算。下图将这种改进的核算与经典的 RDP 核算进行了比较,并表明 PLD 核算改善了所有隐私预算 ( ε )在 pCTR 数据集上的 AUC 。
大批量训练
批次大小是一个超参数,会影响 DP-SGD 训练的不同方面。例如,在相同的隐私保证下,增加批次大小可以减少训练期间添加的噪声量,从而降低训练方差。批次大小还通过其他参数影响隐私保证,例如子采样概率和训练步骤。没有简单的公式可以量化批次大小的影响。但是,批次大小和噪声规模之间的关系是使用隐私核算量化的,隐私核算计算在使用特定批次大小时给定隐私预算 ( ε ) 下所需的噪声规模(以标准差衡量) 。下图在两种不同情况下绘制了这种关系。第一种情况使用固定时期,其中我们固定了训练数据集的传递次数。在这种情况下,随着批次大小的增加,训练步骤的数量会减少,这可能导致模型训练不足。第二种更直接的情况是使用固定训练步骤(固定步骤)。
批次大小与噪声尺度之间的关系。隐私核算需要噪声标准差,该标准差会随着批次大小的增加而减小,以满足给定的隐私预算。因此,通过使用比非隐私基线(由垂直虚线表示)大得多的批次大小,可以显著降低 DP-SGD 添加的高斯噪声的尺度。
除了允许更小的噪声规模外,更大的批量大小还允许我们使用更大的阈值对每个示例梯度进行范数剪裁,这是 DP-SGD 所要求的。由于范数剪裁步骤会在平均梯度估计中引入偏差,因此这种放宽可以减轻这种偏差。下表比较了 Criteo 数据集上 pCTR 的结果,其中标准批量大小(1,024 个示例)和大批量大小(16,384 个示例),结合了大剪裁和增加的训练周期。我们观察到大批量训练显著提高了模型效用。请注意,只有大批量才有可能进行大剪裁。大批量训练对于语言和计算机 视觉领域的 DP-SGD 训练也至关重要。
大批量训练的效果。对于三种不同的隐私预算 ( ε ),我们观察到,在训练具有大批量 (16,384) 的 pCTR 模型时,AUC 明显高于常规批量 (1,024)。
快速计算每个示例的梯度范数
DP-SGD 使用的每个示例梯度范数计算通常会导致计算和内存开销。这种计算消除了加速器(如 GPU)上标准反向传播的效率,标准反向传播计算批次的平均梯度而不实现每个示例的梯度。但是,对于某些神经网络层类型,高效的梯度范数计算算法允许计算每个示例的梯度范数,而无需实现每个示例的梯度向量。我们还注意到,该算法可以有效处理依赖嵌入层和完全连接层来解决广告预测问题的神经网络模型。结合这两个观察结果,我们使用该算法实现了 DP-SGD 算法的快速版本。我们表明,pCTR 上的 Fast-DP-SGD 可以在单个 GPU 核心上处理与非私有基线相似数量的训练示例和相同的最大批次大小。
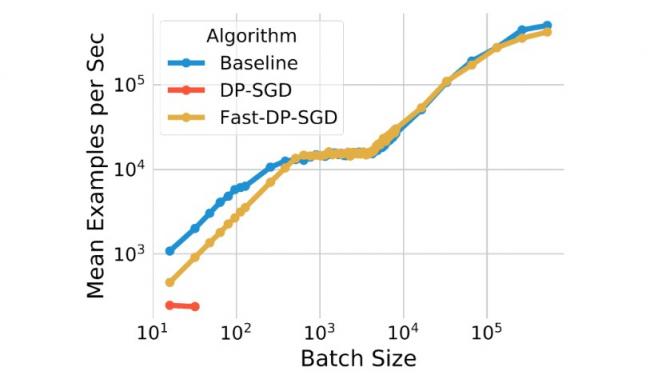
我们的快速实现(Fast-DP-SGD)在 pCTR 上的计算效率。
与非私有基线相比,训练吞吐量相似,但批处理大小非常小。我们还将其与使用JAX 即时(JIT) 编译的实现进行了比较,后者已经比原始 DP-SGD 实现快得多。我们的实现不仅速度更快,而且内存效率更高。基于 JIT 的实现无法处理大于 64 的批处理大小,而我们的实现可以处理高达 500,000 的批处理大小。内存效率对于实现大批处理训练非常重要,而大批处理训练对于提高实用性非常重要,这一点已在上文中得到证实。
结论
我们已经证明,使用 DP-SGD 训练隐私广告预测模型是可行的,与非隐私基线相比,其效用差距较小,并且计算和内存消耗的开销最小。我们相信,通过预训练等技术,效用差距还有进一步缩小的空间。请参阅论文了解实验的完整细节。
致谢
这项工作是与 Carson Denison、Badih Ghazi、Pritish Kamath、Ravi Kumar、Pasin Manurangsi、Amer Sinha 和 Avinash Varadarajan 合作完成的。我们感谢 Silvano Bonacina 和 Samuel Ieong 的许多有益讨论。
评论