在许多计算应用中,系统需要做出决策来处理以在线方式到达的请求。例如,考虑响应驾驶员请求的导航应用程序的示例。在这种情况下,问题的重要方面存在固有的不确定性。例如,驾驶员对路线特征的偏好通常是未知的,并且路段的延迟可能是不确定的。在线机器学习领域研究此类设置,并为不确定性下的决策问题提供各种技术。
导航引擎必须决定如何规划用户的路线。用户的满意度取决于两条路线的(不确定的)拥堵程度,以及用户对各种特征的未知偏好,例如路线的风景、安全性等。
这个框架中一个非常著名的问题是多臂老虎机问题,其中系统有一组n 个可用选项 (臂),要求系统在每一轮 (用户请求) 中进行选择,例如,导航中预先计算的一组备选路线。用户的满意度通过取决于未知因素 (如用户偏好和路段延误) 的奖励来衡量。通过遗憾值(最佳臂的奖励与算法在所有T轮中获得的奖励之间的差值),将算法在T轮中的表现与事后最佳固定动作进行比较。在多臂老虎机问题的专家版本中,每一轮后都会观察到所有奖励,而不仅仅是算法播放的奖励。
专家问题的一个实例。该表列出了在每一轮中跟随 3 位专家所获得的奖励 = 1、2、3、4。事后看来最好的专家(因此也是比较的基准)是中间的专家,总奖励为 21。例如,如果我们在前两轮中选择了专家 1,在后两轮中选择了专家 3(回想一下,我们需要在观察每轮的奖励之前进行选择),我们将获得奖励 17,这将产生等于 21 - 17 = 4 的遗憾。
这些问题已被广泛研究,现有算法可以实现次线性遗憾。例如,在多臂老虎机问题中,现有最佳算法可以实现 √T 阶的遗憾。然而,这些算法专注于针对最坏情况进行优化,并没有考虑到现实世界中大量可用数据,这些数据使我们能够训练能够帮助我们进行算法设计的机器学习模型。
在“在线学习和带查询提示的强盗” (在ITCS 2023上展示) 中,我们展示了为我们提供弱提示的 ML 模型如何显著提高算法在强盗类设置中的性能。许多 ML 模型都是使用相关的过去数据进行准确训练的。例如,在路线规划应用中,特定的过去数据可用于估计路段延迟,而驾驶员的过去反馈可用于了解某些路线的质量。在某些情况下,使用此类数据训练的模型可以提供非常准确的反馈。但是,即使模型的反馈形式是不太明确的弱提示,我们的算法也能实现强有力的保证。具体来说,我们只是要求模型预测两个选项中的哪一个会更好。在导航应用中,这相当于让算法选择两条路线并查询 ETA 模型以确定哪条路线更快,或者向用户展示两条具有不同特征的路线并让他们选择最适合他们的路线。通过设计利用这种提示的算法,我们可以:在对 T 的依赖性方面,以指数规模改善强盗设置的遗憾值,并将专家设置的遗憾值从√T 的量级改善为独立于 T。具体来说,我们的上限仅取决于专家的数量n,并且最多为 log( n )。
算法思想
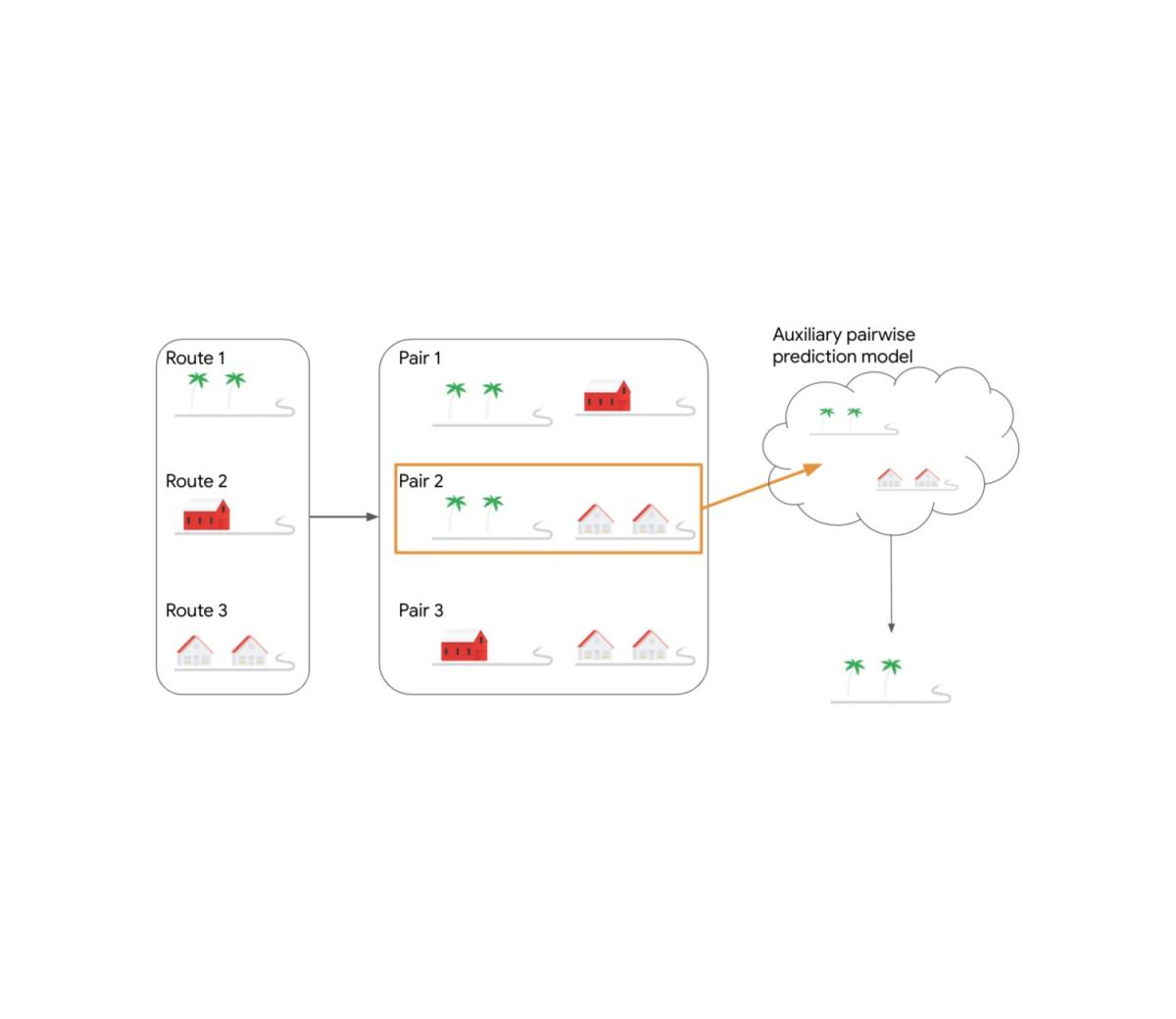
我们针对老虎机设置的算法采用了众所周知的置信上限(UCB) 算法。UCB 算法将迄今为止在该臂上观察到的平均奖励作为每个臂的分数,并向其添加一个乐观参数,该参数会随着臂被拉动的次数而变小,从而在探索和利用之间取得平衡。我们的算法将 UCB 分数应用于臂对,主要是为了利用可用的成对比较模型来指定两个臂中更好的一个。每对臂i和j被分组为一个元臂( i , j ),其每轮的奖励等于两个臂之间的最大奖励。我们的算法观察元臂的 UCB 分数并选择得分最高的对 ( i , j )。然后将这对臂作为查询传递给 ML 辅助成对预测模型,该模型会以两个臂中最好的一个做出响应。此响应是算法最终使用的臂。
决策问题考虑三条候选路线。我们的算法则考虑所有候选路线对。假设第 2 条路线对是当前轮次得分最高的路线对。该路线对被提供给辅助 ML 成对预测模型,该模型输出当前轮次中两条路线中哪条更好。
我们针对专家设置的算法采用跟随正则化领导者(FtRL) 方法,该方法保持每个专家的总奖励并向每个专家添加随机噪声,然后选择当前轮次的最佳专家。我们的算法重复此过程两次,绘制两次随机噪声并在两次迭代中每次选择奖励最高的专家。然后使用两个选定的专家来查询辅助 ML 模型。模型对两个专家之间最佳专家的响应就是算法所扮演的角色。
结果
我们的算法利用弱提示的概念在理论保证方面实现了显著的改进,包括遗憾对时间范围的依赖性呈指数级改善,甚至完全消除这种依赖性。为了说明该算法如何能够超越现有的基线解决方案,我们提出了一种设置,其中n 个候选臂中的 1 个始终比剩余的n -1 个臂略好。我们将我们的 ML 探测算法与使用标准 UCB 算法挑选两个臂提交给成对比较模型的基线进行比较。我们观察到 UCB 基线不断积累遗憾,而探测算法可以快速识别最佳臂并继续播放,而不会积累遗憾。
我们的算法优于基于 UCB 的基线的一个例子。该实例考虑了n 个分支,其中一个分支总是比其余n -1 个分支略好。
结论
在这项研究中,我们探索了一个简单的成对比较 ML 模型如何提供简单的提示,这些提示在专家和老虎机问题等环境中非常有效。在我们的论文中,我们进一步介绍了这些想法如何应用于更复杂的环境,例如在线线性和凸优化。我们相信我们的提示模型可以在 ML 和组合优化问题中拥有更有趣的应用。
致谢
我们感谢我们的合著者 Aditya Bhaskara(犹他大学)、Sungjin Im(加州大学默塞德分校)和 Kamesh Munagala(杜克大学)。
评论