十年前,深度学习的爆发式增长部分得益于新算法和架构的融合、数据的显著增加以及更强大的计算能力。在过去的十年中,人工智能和机器学习模型变得更大、更复杂——它们更深入、更复杂、参数更多,并且经过更多数据训练,从而产生了机器学习历史上最具变革性的成果。
随着这些模型越来越多地被部署到生产和商业应用中,这些模型的效率和成本已从次要考虑因素变为主要制约因素。作为回应,谷歌继续在机器学习效率方面投入巨资,应对 (a) 高效架构、(b) 训练效率、(c) 数据效率和 (d) 推理效率方面的最大挑战。除了效率之外,这些模型还面临着许多其他挑战,包括事实性、安全性、隐私性和新鲜度。下面,我们重点介绍了一系列工作,这些工作展示了谷歌研究部门在开发新算法以应对上述挑战方面的努力。
· 高效的架构 · 数据效率
· 培训效率 · 推理效率
高效的架构
一个基本问题是“是否有更好的方法来参数化模型以提高效率?” 2022 年,我们专注于通过检索上下文增强模型来注入外部知识的新技术;专家混合;并使转换器(大多数大型 ML 模型的核心)更加高效。
情境增强模型
为了提高质量和效率,神经模型可以通过大型数据库或可训练内存中的外部上下文进行增强。通过利用检索到的上下文,神经网络可能不必在其内部参数中记住大量的世界知识,从而提高参数效率、可解释性和真实性。
在“上下文增强语言建模的解耦上下文处理”中,我们探索了一种基于解耦编码器-解码器架构将外部上下文合并到语言模型中的简单架构。这可以节省大量计算资源,同时在自回归语言建模和开放域问答任务上取得有竞争力的结果。然而,预训练的大型语言模型 (LLM) 通过对大型训练集进行自我监督消耗了大量信息。但是,尚不清楚此类模型的“世界知识”如何与所呈现的上下文交互。借助知识感知微调(KAFT),我们将反事实和不相关上下文合并到标准监督数据集中,从而增强了 LLM 的可控性和鲁棒性。
用于上下文合并的编码器-解码器交叉注意机制,允许将上下文编码与语言模型推理分离,从而产生高效的上下文增强模型。
在寻求模块化深度网络的过程中,一个问题是如何设计一个概念数据库和相应的计算模块。我们提出了一个理论架构,该架构将以草图的形式“记住事件”,这些草图存储在外部 LSH 表中,并带有指向处理此类草图的模块的指针。
上下文增强模型的另一个挑战是在加速器上快速检索大型数据库中的信息。我们开发了一种基于 TPU 的相似性搜索算法,该算法与 TPU 的性能模型一致,并对预期召回率提供分析保证,从而实现最佳性能。搜索算法通常涉及大量超参数和设计选择,这使得很难在新任务上对其进行调整。我们提出了一种新的约束优化算法来自动进行超参数调整。将所需的成本或召回率固定为输入,所提出的算法会生成经验上非常接近速度召回率帕累托前沿的调整,并在标准基准上提供领先的性能。
混合专家模型
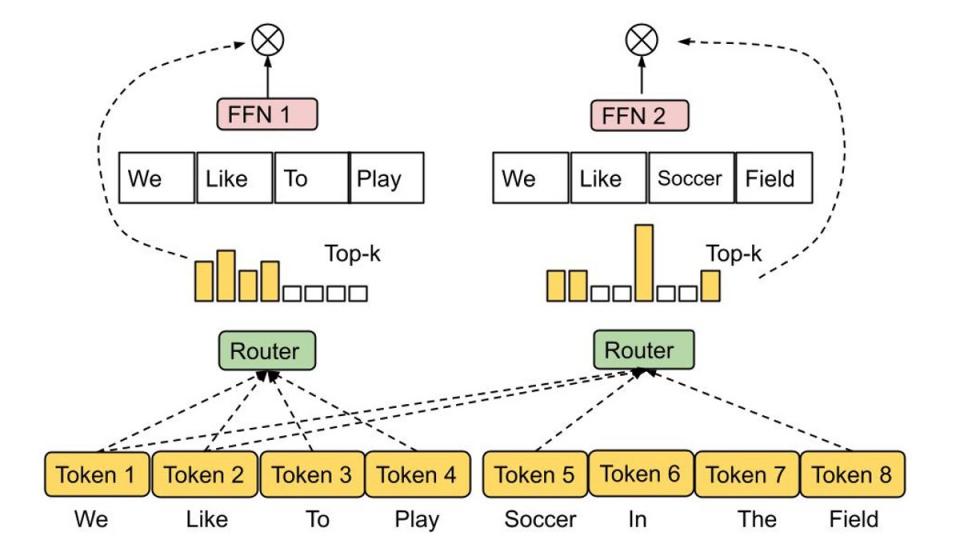
混合专家(MoE) 模型已被证明是一种有效的方法,可以提高神经网络模型的容量,而不会过度增加其计算成本。MoE 的基本思想是从多个专家子网络构建一个网络,其中每个输入都由合适的专家子集处理。因此,与标准神经网络相比,MoE 仅调用整个模型的一小部分,从而实现高效率,如GLaM等语言模型应用程序所示。
GLaM 的架构中,每个输入标记被动态路由到 64 个选定专家网络中的两个进行预测。
对于给定的输入,哪些专家应该处于活动状态的决定由路由功能 决定,路由功能的设计具有挑战性,因为人们希望防止每个专家的利用不足或过度利用。在最近的一项工作中,我们提出了专家选择路由,这是一种新的路由机制,它不是将每个输入令牌分配给前k 个专家,而是将每个专家分配给前k 个令牌。这可以自动确保专家的负载平衡,同时也自然允许多个专家处理一个输入令牌。
专家选择路由。具有预定缓冲容量的专家被分配前 k 个令牌,从而保证负载平衡。每个令牌可以由可变数量的专家处理。
高效变压器
Transformer是一种流行的序列到序列模型,在从视觉到自然语言理解等一系列具有挑战性的问题中取得了显著的成功。此类模型的核心组件是注意层,它识别“查询”和“键”之间的相似性,并利用这些相似性构建合适的“值”加权组合。虽然有效,但注意机制对序列长度的缩放效果较差(即二次)。
随着 transformer 的规模不断扩大,研究学习模型中是否存在任何自然发生的结构或模式来帮助我们解读它们的工作原理是很有趣的。为此,我们研究了中间 MLP 层中学习到的嵌入,发现它们非常稀疏——例如,T5-Large 模型的非零条目不到 1%。稀疏性进一步表明,我们可以在不影响模型性能的情况下减少 FLOP。
我们最近提出了Treeformer ,这是依赖决策树的标准注意力计算的替代方案。直观地说,这可以快速识别与查询相关的一小部分键,并且仅对该集合执行注意力操作。从经验上讲,Treeformer 可以将注意力层的 FLOP 减少 30 倍。我们还引入了顺序注意力,这是一种将注意力与贪婪算法相结合的可微分特征选择方法。该技术对线性模型具有强大的可证明保证,并且可以无缝扩展到大型嵌入模型。
在 Treeformer 中,注意力计算被建模为最近邻检索问题。分层决策树用于查找每个查询需要关注的键,从而大幅降低传统注意力的二次成本。
提高 transformer 效率的另一种方法是加快注意力层中的softmax计算速度。基于我们之前对 softmax 核低秩近似的研究,我们提出了一类新的随机特征,它提供了 softmax 核的第一个“正且有界”的随机特征近似,并且在序列长度上具有计算线性。我们还提出了第一种以可扩展的方式(即与输入序列长度成二次函数)整合各种注意力掩蔽机制(如因果和相对位置编码)的方法。
顶部
训练效率
高效的优化方法是现代 ML 应用的基石,在大规模环境中尤为重要。在这种环境中,即使是像Adam这样的一阶自适应方法也往往成本高昂,训练稳定性也变得具有挑战性。此外,这些方法通常与神经网络的架构无关,从而忽略了架构的丰富结构,导致训练效率低下。这促使人们开发新技术来更高效、更有效地优化现代神经网络模型。我们正在开发新的架构感知训练技术,例如用于训练变压器网络,包括新的尺度不变变压器网络和新颖的裁剪方法,当与普通随机梯度下降(SGD) 结合使用时,可以加快训练速度。使用这种方法,我们首次能够使用简单的 SGD 有效地训练BERT,而无需自适应性。
此外,我们利用LocoProp提出了一种新方法,该方法使用与一阶优化器相同的计算和内存资源,实现与二阶优化器相似的性能。LocoProp通过将神经网络分解为多个层,对神经网络采取模块化视图。然后,每一层都可以拥有自己的损失函数以及输出目标和权重正则化器。在这种设置下,经过合适的前向-后向传递后,LocoProp 将继续对每一层的“局部损失”进行并行更新。事实上,从理论上和经验上看,这些更新都与高阶优化器的更新相似。在深度自动编码器基准测试中,LocoProp 实现了与高阶优化器相当的性能,同时速度明显更快。
与反向传播类似,LocoProp 应用前向传递来计算激活。在后向传递中,LocoProp 为每个层设置每个神经元的“目标”。最后,LocoProp 将模型训练拆分为跨层的独立问题,其中可以并行对每个层的权重应用多个局部更新。
诸如 SGD 之类的优化器中的一个关键假设是,每个数据点都是从分布中独立且相同地采样的。不幸的是,这在强化学习等实际环境中很难满足,因为模型(或代理)必须从基于其自身预测生成的数据中学习。我们提出了一种名为SGD 的具有反向经验重放的新算法方法,该方法可以在线性动态系统、非线性动态系统和强化学习的 Q 学习等多种环境中找到最优解。此外,该方法的增强版本IER被证明是最先进的,并且是各种流行 RL 基准中最稳定的经验重放技术。
顶部
数据效率
对于许多任务而言,深度神经网络严重依赖大型数据集。除了大型数据集带来的存储成本和潜在的安全/隐私问题之外,在此类数据集上训练现代深度神经网络还会产生高昂的计算成本。解决这个问题的一个有希望的方法是数据子集选择,学习者的目标是从大量训练样本中找到信息量最大的子集,以接近(甚至改进)整个训练集的训练效果。
我们分析了一个子集选择框架,该框架旨在与实际批量设置中的任意模型系列配合使用。在这样的设置中,学习者可以一次抽样一个示例,同时访问上下文和真实标签,但为了限制间接成本,只有在选择了足够大的示例批次后才能更新其状态(即进一步训练模型权重)。我们开发了一种称为IWeS的算法,该算法通过重要性抽样来选择示例,其中分配给每个示例的抽样概率基于在先前选择的批次上训练的模型的熵。我们提供理论分析,证明泛化和采样率界限。
训练大型网络的另一个问题是,它们可能对训练数据和部署时看到的数据之间的分布变化高度敏感,尤其是在使用有限数量的训练数据(可能无法覆盖所有部署时场景)时。最近的一项研究假设“极端简单偏差”是神经网络脆弱性背后的关键问题。我们的最新研究使这一假设变得可行,从而产生了两种新的互补方法——DAFT和FRR——它们结合起来可以提供更强大的神经网络。具体来说,这两种方法使用对抗性微调以及逆特征预测来使学习到的网络变得强大。
顶部
推理效率
事实证明,增加神经网络的规模在提高其预测准确性方面非常有效。然而,在现实世界中实现这些收益具有挑战性,因为大型模型的推理成本可能高得令人望而却步。这促使我们采取策略来提高服务效率,而不会牺牲准确性。2022 年,我们研究了实现这一目标的不同策略,特别是基于知识提炼和自适应计算的策略。
蒸馏
蒸馏是一种简单而有效的模型压缩方法,它极大地扩展了大型神经模型的潜在适用性。蒸馏已被证明在一系列实际应用中非常有效,例如广告推荐。蒸馏的大多数用例都涉及将基本配方直接应用于给定领域,但对于何时以及为什么应该这样做的理解有限。我们今年的研究着眼于根据特定设置定制蒸馏,并正式研究决定蒸馏成功的因素。
在算法方面,通过仔细建模教师标签中的噪声,我们开发了一种原则性的方法来重新加权训练示例,并开发了一种强大的方法来对数据子集进行采样以获得教师标签。在“教师指导训练”中,我们提出了一个新的蒸馏框架:我们不是被动地使用教师来注释固定数据集,而是主动使用教师来指导选择要注释的信息样本。这使得蒸馏过程在有限数据或长尾设置中大放异彩。
我们还研究了从交叉编码器(例如BERT)到分解对偶编码器的新的蒸馏方法,这是对 [查询,文档]对的相关性进行评分的重要设置。我们研究了交叉编码器和对偶编码器之间性能差距的原因,并指出这可能是由于 双编码器的泛化而不是容量限制造成的。精心构建蒸馏的损失函数可以缓解这种情况并缩小交叉编码器和双编码器性能之间的差距。随后,在EmbedDistill中,我们研究了通过匹配来自教师模型的嵌入来进一步改进双编码器蒸馏。此策略还可用于从大型到小型的双编码器模型进行蒸馏,其中继承和冻结教师的文档嵌入可以证明是非常有效的。
在 EmbedDistill 中,教师对学生的蒸馏是通过设计新的损失函数来完成的,除了匹配最终预测之外,该损失函数还将学生嵌入的几何形状与老师的几何形状相匹配。
在理论方面,我们通过监督复杂度的视角为蒸馏提供了一个新视角,监督复杂度是衡量学生预测教师标签能力的指标。借鉴神经正切核(NTK) 理论,这提供了概念性见解,例如容量差距可能会影响蒸馏,因为这些教师标签在学生看来可能类似于纯随机标签。我们进一步证明,蒸馏可能会导致学生对教师模型认为“难以”建模的点进行欠拟合。直观地说,这可能有助于学生将其有限的容量集中在可以合理建模的样本上。
自适应计算
虽然蒸馏是降低推理成本的有效方法,但它对所有样本都起到了统一的作用。然而,直观地看,一些“简单”样本可能天生就比“困难”样本需要更少的计算。自适应计算的目标是设计出能够实现这种基于样本的计算的机制。
自信自适应语言模型 (CALM) 为基于 Transformer 的文本生成器(例如T5)引入了受控的早期退出功能。在这种自适应计算形式中,模型会动态修改每个解码步骤使用的 Transformer 层数。早期退出门使用置信度度量和经过校准以满足统计性能保证的决策阈值。通过这种方式,模型只需要为最具挑战性的预测计算完整的解码器层堆栈。较简单的预测只需要计算几个解码器层。在实践中,该模型平均使用大约三分之一的层进行预测,在保持相同生成质量水平的同时将速度提高了 2-3 倍。
使用常规语言模型(顶部)和 CALM(底部)生成文本。 CALM 尝试做出早期预测。 一旦信心足够(深蓝色调),它就会跳过并节省时间。
一种流行的自适应计算机制是两个或多个基础模型的级联。使用级联的一个关键问题是决定是只使用当前模型的预测,还是将预测推迟到下游模型。了解何时推迟需要设计一个合适的损失函数,该函数可以利用适当的信号作为推迟决策的监督。我们正式研究了现有的损失函数以实现这一目标,表明由于隐式应用了标签平滑,它们可能与训练样本不匹配。我们表明,可以通过事后训练推迟规则来缓解这种情况,这不需要以任何方式修改模型内部结构。
对于检索应用,标准语义搜索技术对大型模型生成的每个嵌入使用固定表示。也就是说,无论下游任务及其相关的计算环境或约束如何,表示大小和能力大多是固定的。Matryoshka表示学习引入了根据部署环境调整表示的灵活性。也就是说,它强制表示在其坐标内具有自然顺序,使得对于资源受限的环境,我们只能使用表示的前几个坐标,而对于更丰富和精度至关重要的设置,我们可以使用更多的表示坐标。当与ScaNN等标准近似最近邻搜索技术相结合时,MRL 能够在相同的召回率和准确率指标下提供高达 16 倍的计算成本。
顶部
总结
大型 ML 模型在多个领域都展现出了变革性成果,但训练和推理的效率正成为使这些模型在现实世界中实用的关键需求。Google Research 一直在通过开发新的基础技术来提高大型 ML 模型的效率。这是一项持续不断的努力,在接下来的几个月里,我们将继续探索核心挑战,使 ML 模型更加强大和高效。
致谢
高效深度学习的工作是 Google Research 众多研究人员的合作,包括 Amr Ahmed、Ehsan Amid、Rohan Anil、Mohammad Hossein Bateni、Gantavya Bhatt、Srinadh Bhojanapalli、Zhifeng Chen、Felix Chern、Gui Citovsky、Andrew Dai、Andy Davis , 邓子豪, Giulia DeSalvo, Nan Du, Avi Dubey, Matthew Fahrbach, 郭瑞琪, Blake Hechtman, Yanping Huang, Prateek Jain, Wittawat Jitkrittum, Seungyeon Kim, Ravi Kumar, Aditya Kusupati, James Laudon, Quoc Le, Dailiang Li, Zonglin Li、Lovish Madaan、David Majnemer、Aditya Menon、Don Metzler、Vahab Mirrokni、Vaishnavh Nagarajan、Harikrishna Narasimhan、Rina Panigrahy、Srikumar Ramalingam、 Ankit Singh Rawat、Sashank Reddi、Aniket Rege、Afshin Rostamizadeh、Tal Schuster、Si Si、Apurv Suman、Phil Sun、Erik Vee、Ke Ye、Chong You、Felix Yu、Manzil Zaheer 和 Yanqi Zhou。
评论