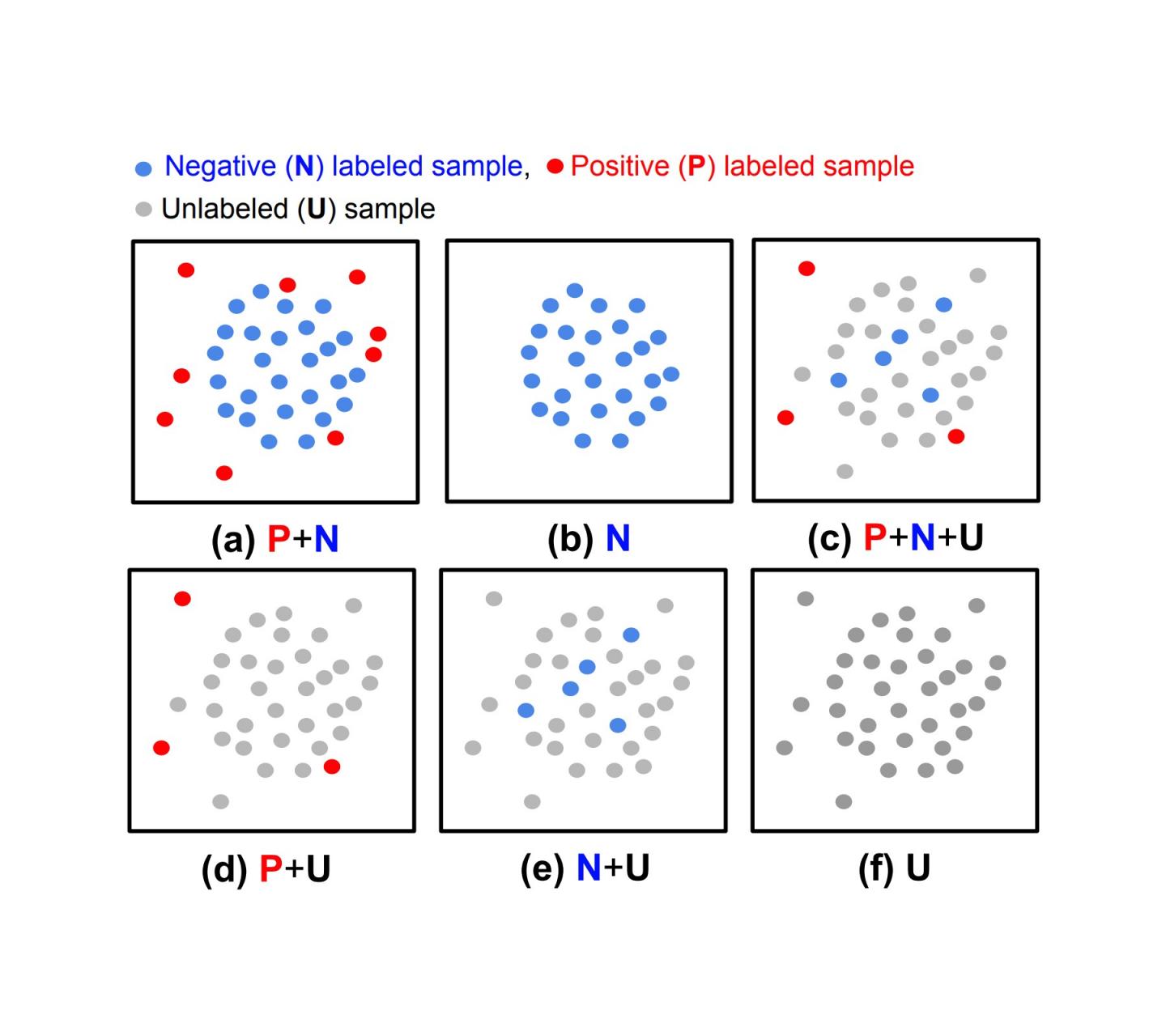
异常检测 (AD) 是一项将异常与正常数据区分开的任务,它在许多实际应用中起着至关重要的作用,例如通过制造业中的视觉传感器检测有缺陷的产品、金融交易中的欺诈行为或网络安全威胁。根据数据类型的可用性(负(正常)与正(异常)及其标签的可用性),AD 任务涉及不同的挑战。
(a)完全监督异常检测,(b)仅正常异常检测,(c、d、e)半监督异常检测,(f)无监督异常检测。
虽然大多数以前的研究都表明,对于具有完全标记数据的情况(上图中的 (a) 或 (b))是有效的,但这种设置在实践中并不常见,因为获取标签特别繁琐。在大多数情况下,用户的标记预算有限,有时在训练期间甚至没有任何标记样本。此外,即使有标记数据可用,样本的标记方式也可能存在偏差,从而导致分布差异。这种现实世界的数据挑战限制了先前方法在检测异常方面可达到的准确性。
这篇文章涵盖了我们最近在《机器学习研究汇刊》 (TMLR) 上发表的两篇关于 AD 的论文,这些论文解决了无监督和半监督设置中的上述挑战。使用以数据为中心的方法,我们在这两种情况下都展示了最先进的结果。在“自监督、改进、重复:改进无监督异常检测”中,我们提出了一种新颖的无监督 AD 框架,该框架依赖于无标签的自监督学习原理和基于一类分类器(OCC) 输出一致性的迭代数据改进。在“ SPADE:分布不匹配下的半监督异常检测”中,我们提出了一种新颖的半监督 AD 框架,即使在分布不匹配且标记样本有限的情况下也能实现稳健的性能。
使用 SRR 进行无监督异常检测:自监督、优化、重复
在完全无监督的环境中,发现单类(正态)分布(即 OCC 训练)的决策边界具有挑战性,因为未标记的训练数据包括两个类别(正常和异常)。随着未标记数据的异常率越来越高,挑战变得更加严峻。要使用未标记数据构建稳健的 OCC,从未标记数据中排除可能的阳性(异常)样本,这一过程称为数据细化,至关重要。经证实,具有较低异常率的细化数据可产生卓越的异常检测模型。
SRR 首先从未标记数据集中提炼数据,然后使用提炼数据迭代训练深度表示,同时通过排除可能的阳性样本来改进未标记数据的提炼。对于数据提炼,使用一组OCC,每个 OCC 都在未标记训练数据的不相交子集上进行训练。如果集合中的所有 OCC 都一致,则预测为负(正常)的数据将包含在提炼数据中。最后,使用提炼的训练数据训练最终 OCC 以生成异常预测。
使用数据细化模块(OCCs 集成)、表示学习器和最终 OCC 训练 SRR。(绿点/红点分别代表正常/异常样本)。
SRR 结果
我们对来自不同领域的各种数据集进行了广泛的实验,包括语义 AD(CIFAR-10、Dog-vs-Cat)、真实世界制造业视觉 AD(MVTec)和真实世界表格 AD 基准,例如检测医疗(Thyroid)或网络安全(KDD 1999)异常。我们考虑使用浅层(例如,OC-SVM)和深度(例如,GOAD、CutPaste)模型的方法。由于真实世界数据的异常率可能有所不同,我们在未标记训练数据的不同异常率下评估模型,并表明 SRR 显著提高了 AD 性能。例如,与 CIFAR-10上最先进的单类深度模型相比,SRR 在 10% 的异常率下将平均精度(AP)提高了 15.0 以上。同样,在 MVTec 上,SRR 保持了稳定的性能,异常率为 10%,AUC下降不到 1.0 ,而现有最佳 OCC下降超过 6.0。最后,在甲状腺(表格数据)上,SRR 的表现比最先进的单类分类器高出22.9 F1分数,异常率为 2.5%。
在各个领域中,SRR(蓝线)在完全无监督的设置下显著提升了具有各种异常率的 AD 性能。
SPADE:基于集成的半监督伪标签异常检测
大多数半监督学习方法(例如FixMatch、VIME)都假设标记数据和未标记数据来自相同的分布。然而,在实践中,分布不匹配的情况很常见,标记数据和未标记数据来自不同的分布。一种这样的情况是正和未标记(PU) 或负和未标记 (NU) 设置,其中标记(正或负)和未标记(正和负)样本之间的分布不同。分布偏移的另一个原因是标记后收集了额外的未标记数据。例如,制造工艺可能会不断发展,导致相应的缺陷发生变化,标记时的缺陷类型与未标记数据中的缺陷类型不同。此外,对于金融欺诈检测和反洗钱等应用,数据标记过程后可能会出现新的异常,因为犯罪行为可能会适应。最后,标记者在标记简单样本时对它们更有信心;因此,简单/困难的样本更有可能包含在标记/未标记数据中。例如,在一些基于众包的标记中,只有对标签有一定共识的样本(作为置信度的衡量标准)才会被纳入标记集。
三种常见的分布不匹配的现实场景(蓝框:正常样本,红框:已知/容易异常的样本,黄框:新的/困难异常样本)。
标准半监督学习方法假设标记数据和未标记数据来自同一分布,因此对于分布不匹配的半监督 AD 来说不是最优的。SPADE 利用一组 OCC 来估计未标记数据的伪标签——它独立于给定的正标记数据进行此操作,从而减少了对标签的依赖。当分布不匹配时,这尤其有益。此外,SPADE 采用部分匹配来自动选择伪标记的关键超参数,而不依赖于标记验证数据,这是标记数据有限的一项关键功能。
SPADE 的框图,其中放大了所提出的伪标签器的详细框图。
SPADE 结果
我们进行了广泛的实验,以展示 SPADE 在分布不匹配的半监督学习的各种现实环境中的优势。我们考虑了多个 AD 数据集,包括图像(包括MVTec)和表格(包括Covertype、Thyroid)数据。
SPADE 在各种场景中都展现出了最先进的半监督异常检测性能:(i)新型异常,(ii)易于标记的样本,以及(iii)未标记的正样本。如下所示,对于新型异常,SPADE 的平均 AUC 比最先进的替代方案高出 5%。
AD 在各种数据集(Covertype、MVTec、Thyroid)的三种不同场景中的 AUC 表现。一些基线仅适用于某些场景。其他基线和数据集的更多结果可在论文中找到。
我们还在现实世界的金融欺诈检测数据集上评估了 SPADE:Kaggle 信用卡欺诈和Xente 欺诈检测。对于这些数据集,异常会不断演变(即它们的分布会随时间而变化),为了识别演变中的异常,我们需要不断标记新的异常并重新训练 AD 模型。然而,标记成本高昂且耗时。即使没有额外的标记,SPADE 也可以使用标记数据和新收集的未标记数据来提高 AD 性能。
使用两个现实世界的欺诈检测数据集(标记率为 10%),对具有时变分布的 AD 性能进行测试。更多基线可以在论文中找到。
如上所示,SPADE 在两个数据集上的表现始终优于其他方法,它充分利用了未标记的数据,并表现出对不断变化的分布的稳健性。
结论
AD 具有广泛的用例,在实际应用中具有重要意义,从检测金融系统中的安全威胁到识别制造机器的故障行为。
构建 AD 系统的一个挑战和成本问题是异常很少见,而且不容易被人发现。为此,我们提出了 SRR,这是一个规范的 AD 框架,可实现高性能 AD,而无需手动标记进行训练。SRR 可以灵活地与任何 OCC 集成,并应用于原始数据或可训练的表示。
半监督 AD 是另一个非常重要的挑战——在许多情况下,标记和未标记样本的分布不匹配。SPADE 引入了一种强大的伪标记机制,使用一组 OCC 和一种结合监督和自监督学习的明智方法。此外,SPADE 引入了一种有效的方法来选择关键超参数,而无需验证集,这是数据高效 AD 的关键组成部分。
总体而言,我们证明 SRR 和 SPADE 在多种类型的数据集中的各种场景中始终优于替代方案。
致谢
我们衷心感谢 Kihyuk Sohn、Chun-Liang Li、Chen-Yu Lee、Kyle Ziegler、Nate Yoder 和 Tomas Pfister 的贡献。
评论