对用户界面 (UI) 的计算理解是实现智能 UI 行为的关键一步。之前,我们研究了各种 UI 建模任务,包括小部件字幕、屏幕摘要和命令基础,这些任务解决了自动化和可访问性等各种交互场景。我们还展示了机器学习如何通过诊断可点击性混淆并提供改进 UI 设计的见解来帮助用户体验从业者提高 UI 质量。这些工作以及该领域其他人开发的工作展示了深度神经网络如何潜在地改变最终用户体验和交互设计实践。
在解决单个 UI 任务方面取得这些成功后,一个自然而然的问题是,我们是否可以获得对 UI 的基本理解,从而使特定的 UI 任务受益。作为我们回答这个问题的首次尝试,我们开发了一个多任务模型来同时解决一系列 UI 任务。虽然这项工作取得了一些进展,但仍存在一些挑战。以前的 UI 模型严重依赖于UI 视图层次结构(即移动 UI 屏幕的结构或元数据,如网页的文档对象模型),这允许模型直接获取屏幕上 UI 对象的详细信息(例如,它们的类型、文本内容和位置)。这些元数据使以前的模型比仅基于视觉的模型更具优势。然而,视图层次结构并不总是可访问的,而且经常因缺少对象描述或结构信息不一致而损坏。因此,尽管使用视图层次结构在短期内会带来好处,但它最终可能会妨碍模型的性能和适用性。此外,以前的模型必须处理跨数据集和 UI 任务的异构信息,这通常会导致复杂的模型架构,难以在任务之间扩展或推广。
在被ICLR 2023接受发表的 “ Spotlight:使用视觉语言模型进行移动 UI 理解”中,我们提出了一种纯视觉方法,旨在完全从原始像素中实现一般 UI 理解。我们引入了一种统一的方法来表示不同的 UI 任务,这些任务的信息可以通过两种核心模态来普遍表示:视觉和语言。视觉模态捕捉人们从 UI 屏幕上看到的内容,语言模态可以是自然语言或与任务相关的任何标记序列。我们证明 Spotlight 显著提高了一系列 UI 任务的准确性,包括小部件字幕、屏幕摘要、命令基础和可点击性预测。
聚光灯模型
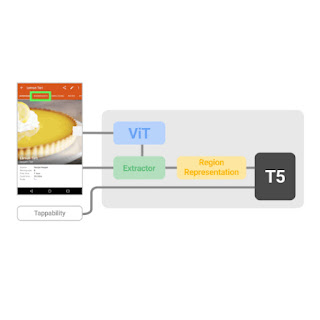
Spotlight 模型输入包括三个项目的元组:屏幕截图、屏幕上的关注区域和任务的文本描述。输出是关于关注区域的文本描述或响应。这种简单的模型输入和输出表示具有表现力,可以捕获各种 UI 任务,并允许可扩展的模型架构。这种模型设计允许一系列学习策略和设置,从特定于任务的微调到多任务学习,再到少量学习。如上图所示,Spotlight 模型利用了ViT和T5等在资源丰富的通用视觉语言领域预先训练的现有架构构建块,这使我们能够在这些通用领域模型的成功基础上进行构建。
由于 UI 任务通常与屏幕上的特定对象或区域有关,这需要模型能够聚焦于感兴趣的对象或区域,因此我们在视觉语言模型中引入了焦点区域提取器,使模型能够根据屏幕环境集中于该区域。
具体来说,我们设计了一个区域汇总器,它使用从区域边界框生成的注意查询,基于 ViT 编码获取屏幕区域的潜在表示(有关详细信息,请参阅论文)。具体而言,边界框的每个坐标(标量值,即左侧、顶部、右侧或底部)(在屏幕截图上表示为黄色框)首先通过多层感知器(MLP) 嵌入为密集向量的集合,然后沿着它们的坐标类型嵌入输入到 Transformer 模型。密集向量及其对应的坐标类型嵌入采用颜色编码以指示它们与每个坐标值的关联。然后,坐标查询通过交叉注意关注 ViT 输出的屏幕编码,并将 Transformer 的最终注意输出用作 T5 下游解码的区域表示。
通过使用边界框,通过注意机制从 ViT 查询屏幕编码,可以总结屏幕上的目标区域。
结果
我们使用两个未标记的数据集(一个基于C4 语料库的内部数据集和一个内部移动数据集)对 Spotlight 模型进行预训练,其中包含 250 万个移动 UI 屏幕和 8000 万个网页。然后,我们分别针对四个下游任务(字幕、摘要、基础和可点击性)微调预训练模型。对于小部件字幕和屏幕摘要任务,我们报告CIDEr分数,该分数衡量模型文本描述与人工评分者创建的一组参考的相似程度。对于命令基础,我们报告准确度,该准确度衡量模型响应用户命令成功定位目标对象的次数百分比。对于可点击性预测,我们报告F1 分数,该分数衡量模型区分可点击对象和不可点击对象的能力。
在这个实验中,我们将 Spotlight 与几个基准模型进行了比较。Widget Caption使用视图层次结构和每个 UI 对象的图像来为该对象生成文本描述。同样,Screen2Words使用视图层次结构和屏幕截图以及辅助功能(例如应用程序描述)来生成屏幕摘要。同样,VUT结合屏幕截图和视图层次结构来执行多项任务。最后,原始的Tappability模型利用来自视图层次结构和屏幕截图的对象元数据来预测对象可点击性。Taperception是Tappability的后续模型,它使用仅限视觉的可点击性预测方法。我们根据其 ViT 构建块的大小检查了两个 Spotlight 模型变体,包括B/16 和 L/16。Spotlight在四个 UI 建模任务中大大超越了最先进的技术。
模型
字幕
总结
接地
可点击性
基线
小部件标题 97 - - -
屏幕转文字 - 61.3 - -
真空压力测试 99.3 65.6 82.1 -
锥度感知 - - - 85.5
可点击性 - - - 87.9
聚光灯
B/16
136.6
103.5
95.7
86.9
L/16 141.8 106.7 95.8 88.4
然后,我们进行一个更具挑战性的设置,要求模型同时学习多个任务,因为多任务模型可以大大减少模型占用空间。如下表所示,实验表明我们的模型仍然具有竞争力。
模型 字幕 总结 接地 可点击性
VUT 多任务 99.3 65.1 80.8 -
聚光灯 B/16 140 102.7 90.8 89.4
聚光灯 L/16 141.3 99.2 94.2 89.5
为了了解 Region Summarizer 如何使 Spotlight 能够聚焦于屏幕上的目标区域和相关区域,我们分析了小部件字幕和屏幕摘要任务的注意力权重(指示模型注意力在屏幕截图上的位置)。在下图中,对于小部件字幕任务,模型预测左侧复选框的选项为“选择切尔西队”,该复选框以红色边界框突出显示。我们可以从右侧的注意力热图(说明注意力权重的分布)中看到,模型不仅学会关注复选框的目标区域,还学会关注最左侧的文本“切尔西”以生成字幕。对于屏幕摘要示例,模型根据左侧的屏幕截图预测“显示学习应用程序教程的页面”。在此示例中,目标区域是整个屏幕,模型学会关注屏幕上的重要部分以进行摘要。
对于小部件字幕任务,注意力热图显示模型在为对象生成字幕时关注复选框(即目标对象)及其左侧的文本标签。图中的红色边界框用于说明目的。
对于目标区域包含整个屏幕的屏幕摘要任务,注意力热图显示模型关注屏幕上有助于生成摘要的各个位置。
结论
我们证明 Spotlight 优于以前使用屏幕截图和视图层次结构作为输入的方法,并在多个代表性 UI 任务上建立了最先进的结果。这些任务包括可访问性、自动化、交互设计和评估。我们用于移动 UI 理解的纯视觉方法减轻了使用视图层次结构的需要,使架构能够轻松扩展,并受益于针对一般领域预先训练的大型视觉语言模型的成功。与最近的大型视觉语言模型(如Flamingo和PaLI)相比,Spotlight 相对较小,我们的实验表明,较大的模型会产生更好的性能。Spotlight 可以轻松应用于更多 UI 任务,并有可能推动许多交互和用户体验任务的前沿发展。
致谢
我们感谢 Mandar Joshi 和 Tao Li 在处理网络预训练数据集方面提供的帮助,以及 Chin-Yi Cheng 和 Forrest Huang 在校对论文方面提供的反馈。感谢 Tom Small 在本文制作动画人物方面提供的帮助。
评论