深度学习的最新进展使得大量基于机器学习 (ML) 的高性能实时多媒体应用成为可能,例如用于视频和电话会议的人体分割、用于 3D 重建的深度估计、用于交互的手部和身体跟踪以及用于远程通信的音频处理。
然而,开发和迭代这些基于 ML 的多媒体原型可能具有挑战性且成本高昂。它通常需要一个由 ML 从业人员组成的跨职能团队来微调模型、评估稳健性、描述优势和劣势、检查最终使用环境中的性能并开发应用程序。此外,模型经常更新,需要反复集成才能进行评估,这使得工作流程不适合设计和实验。
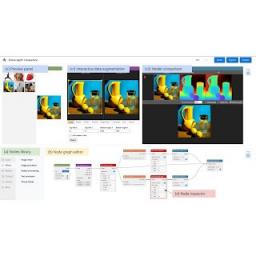
在CHI 2023上发表的 “ Rapsai:通过可视化编程加速多媒体应用的机器学习原型设计”中,我们描述了一个可视化编程平台,用于快速迭代开发端到端基于 ML 的多媒体应用。Visual Blocks for ML(以前称为 Rapsai)通过其节点图编辑器提供无代码图构建体验。用户可以创建和连接不同的组件(节点)以快速构建 ML 管道,并实时查看结果,而无需编写任何代码。我们展示了该平台如何通过交互式表征和可视化 ML 模型性能以及交互式数据增强和比较来实现更好的模型评估体验。我们发布了Visual Blocks for ML框架以及演示和Colab 示例。今天就亲自尝试一下吧。
Visual Blocks 使用节点图编辑器,有助于快速设计基于 ML 的多媒体应用程序的原型。
形成性研究:快速 ML 原型设计的目标
为了更好地了解现有快速原型 ML 解决方案( LIME、VAC-CNN、EnsembleMatrix) 所面临的挑战,我们使用概念模型界面进行了一项形成性研究(即在技术产品或系统设计过程的早期收集潜在用户反馈的过程)。研究参与者包括三个 ML 团队的七名计算机视觉研究人员、音频 ML 研究人员和工程师。
形成性研究使用概念模型界面来收集早期见解。
通过这项形成性研究,我们发现了现有原型解决方案中常见的六个挑战:
用于评估模型的输入通常在分辨率、纵横比或采样率方面与实际用户的野外输入不同。
参与者无法快速、交互地改变输入数据或调整模型。
研究人员利用一组固定数据的定量指标来优化模型,但现实世界的性能需要人工审阅者在应用环境中进行评估。
很难比较模型的不同版本,而且与其他团队成员分享最佳版本进行尝试也很麻烦。
一旦选定了模型,团队就需要花费大量时间来制作展示该模型的定制原型。
最终,该模型只是更大的实时管道的一部分,参与者希望检查中间结果以了解瓶颈。
这些已确定的挑战促成了 Visual Blocks 系统的开发,该系统包括六个设计目标:(1)开发一个用于快速构建 ML 原型的可视化编程平台,(2)支持野外实时多媒体用户输入,(3)提供交互式数据增强,(4)将模型输出与并排结果进行比较,(5)以最小的努力共享可视化效果,(6)提供现成的模型和数据集。
用于可视化编程 ML 管道的节点图编辑器
Visual Blocks 主要用 JavaScript 编写,利用TensorFlow.js和TensorFlow Lite实现机器学习功能,并利用three.js进行图形渲染。该界面允许用户使用三个协调视图快速构建机器学习模型并与之交互:(1)节点库,包含 30 多个节点(例如,图像处理、身体分割、图像比较)和用于筛选的搜索栏;(2)节点图编辑器,允许用户通过从节点库中拖动和添加节点来构建和调整多媒体管道;(3)预览面板,可可视化管道的输入和输出,更改输入和中间结果,并直观地比较不同的模型。
可视化编程界面允许用户通过编写和预览具有实时结果的节点图来快速开发和评估 ML 模型。
独特快速原型制作功能的迭代设计、开发和评估
在过去的一年中,我们一直在反复设计和改进 Visual Blocks 平台。与形成性研究中的三个 ML 团队进行的每周反馈会议表明,他们对该平台的独特功能及其通过以下方式加速 ML 原型设计的潜力表示赞赏:
支持各种类型的输入数据(图像、视频、音频)和输出模式(图形、声音)。
用于常见任务(身体分割、标志检测、肖像深度估计)和自定义模型导入选项的预训练 ML 模型库。
通过拖放操作和参数滑块进行交互式数据增强和操作。
并排比较多个模型并检查其在管道不同阶段的输出。
快速将多媒体管道直接发布并共享到网络上。
评估:四个案例研究
为了评估 Visual Blocks 的可用性和有效性,我们与 15 名 ML 从业者进行了四项案例研究。他们使用该平台为不同的多媒体应用程序制作原型:具有重新照明效果的肖像深度、具有视觉效果的场景深度、用于虚拟会议的 alpha 遮罩以及用于通信的音频降噪。
该系统简化了两个肖像深度模型的比较,包括定制的可视化和效果。
通过简短的介绍和视频教程,参与者能够快速识别模型之间的差异,并根据自己的用例选择更好的模型。我们发现 Visual Blocks 有助于快速、深入地了解模型的优点和缺点:
“它让我直观地了解我的模型对哪些数据增强操作更敏感,然后我可以回到我的训练流程,也许可以增加那些使我的模型更敏感的特定步骤的数据增强量。”(参与者 13)
“添加一些背景噪音需要做大量的工作,我有一个脚本,但每次我都必须找到该脚本并进行修改。我总是一次性完成这项工作。这很简单,但也非常耗时。这个非常方便。”(参与者 15)
该系统允许研究人员比较不同噪声水平下的多个肖像深度模型,帮助机器学习从业者识别每个模型的优缺点。
在使用七点李克特量表的事后调查中,参与者报告称,Visual Blocks 在得出最终结果的方式上比 Colab 更透明(Visual Blocks 6.13 ± 0.88 vs. Colab 5.0 ± 0.88,𝑝 < .005),并且在与用户合作得出输出方面更具协作性(Visual Blocks 5.73 ± 1.23 vs. Colab 4.15 ± 1.43,𝑝 < .005)。尽管 Colab 帮助用户思考任务并通过编程更有效地控制管道,但用户报告称,他们能够在几分钟内完成 Visual Blocks 中的任务,而这些任务通常需要一个小时或更长时间。例如,在观看 4 分钟的教程视频后,所有参与者都能够在 15 分钟内从头开始在 Visual Blocks 中构建自定义管道(10.72 ± 2.14)。参与者通常花费不到五分钟(3.98 ± 1.95)获得初步结果,然后尝试管道的不同输入和输出。
Rapsai(Visual Blocks 的初始原型)和 Colab 在五个维度上的用户评分。
我们论文 中的更多结果表明,Visual Blocks 帮助参与者加速工作流程,对模型选择和调整做出更明智的决策,分析不同模型的优缺点,并根据现实世界的输入全面评估模型行为。
结论和未来方向
Visual Blocks降低了基于 ML 的多媒体应用程序的开发门槛。它使用户能够进行实验,而无需担心编码或技术细节。它还通过提供描述 ML 管道的通用语言来促进设计人员和开发人员之间的协作。未来,我们计划向社区开放此框架,以贡献自己的节点并将其集成到许多不同的平台中。我们希望机器学习的可视化编程将来成为跨 ML 工具的通用接口。
致谢
这项工作是 Google 多个团队合作的成果。项目的主要贡献者包括 Ruofei Du、Na Li、Jing Jin、Michelle Carney、Xiuxiu Yuan、Kristen Wright、Mark Sherwood、Jason Mayes、Lin Chen、Jun Jiang、Scott Miles、Maria Kleiner、Yinda Zhang、Anuva Kulkarni、Xingyu “Bruce” Liu、Ahmed Sabie、Sergio Escolano、Abhishek Kar、Ping Yu、Ram Iyengar、Adarsh Kowdle 和 Alex Olwal。
我们要感谢 Jun Zhang、Satya Amarapalli 和 Sarah Heimlich 提供的几个早期原型,以及 Sean Fanello、Danhang Tang、Stephanie Debats、Walter Korman、Anne Menini、Joe Moran、Eric Turner 和 Shahram Izadi 为手稿和博客文章提供的初步反馈。我们还要感谢 CHI 2023 审稿人提供的深刻反馈。
评论