尽管医学人工智能(AI)领域最近取得了进展,但大多数现有模型都是狭窄的单任务系统,需要大量标记数据进行训练。此外,这些模型无法在新的临床环境中轻松重复使用,因为它们通常需要为每个新的部署环境收集、去识别和注释站点特定数据,这既费力又昂贵。这种数据高效泛化问题(模型使用最少的新数据推广到新设置的能力)仍然是医学机器学习 (ML) 模型面临的关键转化挑战,进而阻碍了它们在现实世界医疗环境中的广泛应用。
基础模型 的出现为重新思考医疗 AI 的发展提供了重要机会,使其更高效、更安全、更公平。这些模型使用大规模数据进行训练,通常通过自我监督学习进行。这一过程产生了通用模型,这些模型可以快速适应新任务和新环境,而对监督数据的需求较少。借助基础模型,我们可能可以在各种临床背景和环境中安全高效地部署模型。
在《自然生物医学工程》上发表的 “稳健高效的自监督医学成像”(REMEDIS)中,我们介绍了一个统一的大规模自监督学习框架,用于构建基础医学成像模型。该策略将大规模监督迁移学习与自监督学习相结合,并且只需极少的任务特定定制。REMEDIS 在医学成像任务和模式的数据高效泛化方面表现出显著改善,并将站点特定数据减少了 3-100 倍,从而使模型能够适应新的临床环境和环境。在此基础上,我们很高兴地宣布推出医学 AI 研究基础(由PhysioNet主办),这是 2022 年胸部 X 光基础公开发布的扩展。医学 AI 研究基础是开源非诊断模型(从 REMEDIS 模型开始)、API 和资源的集合,可帮助研究人员和开发人员加速医学 AI 研究。
医学成像的大规模自监督
REMEDIS 使用自然(非医学)图像和未标记的医学图像的组合来开发强大的医学成像基础模型。其预训练策略包括两个步骤。第一步是使用Big Transfer (BiT) 方法 对大规模标记自然图像数据集(从Imagenet 21k或JFT中提取)进行监督表征学习。
第二步涉及中级自监督学习,它不需要任何标签,而是训练模型独立于标签学习医疗数据表示。用于预训练和学习表示的具体方法是SimCLR 。该方法的工作原理是通过具有多层感知器(MLP)输出的前馈神经网络的隐藏层中的对比损失,最大化同一训练示例的不同增强视图之间的一致性。然而,REMEDIS 与其他对比自监督学习方法同样兼容。这种训练方法适用于医疗保健环境,因为许多医院常规获取原始数据(图像)。虽然必须实施流程才能使这些数据可用于模型(即在收集数据之前征得患者同意、去除身份信息等),但使用 REMEDIS 可以避免标记数据这项昂贵、耗时且困难的任务。
REMEDIS 利用使用自然图像的大规模监督学习和使用未标记医疗数据的自监督学习来为医学成像创建强大的基础模型。
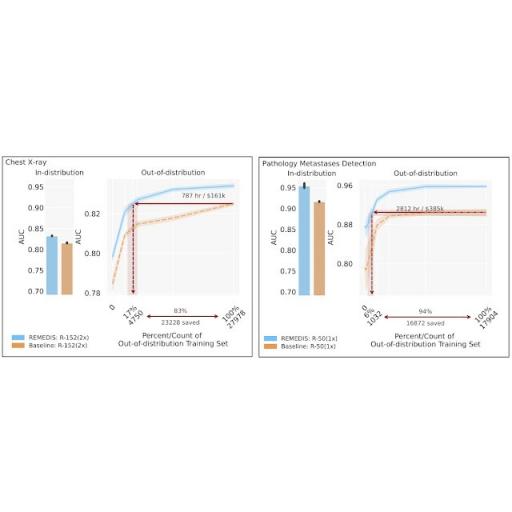
鉴于 ML 模型参数约束,我们提出的方法在使用小型和大型模型架构尺寸时都有效非常重要。为了详细研究这一点,我们考虑了两种具有常用深度和宽度乘数的 ResNet 架构,ResNet-50 (1×) 和ResNet-152 (2×) 作为主干编码器网络。
预训练后,使用标记的任务特定医疗数据对模型进行微调,并评估分布内任务表现。此外,为了评估数据效率的泛化,还可以选择使用少量分布外 (OOD) 数据对模型进行微调。
REMEDIS 首先使用遵循 Big Transfer (BiT) 方法的大规模自然图像预训练初始化表示。然后,我们使用中间对比自监督学习将模型调整到医学领域,而无需使用任何标记的医学数据。最后,我们对模型进行微调以适应特定的下游医学成像任务。我们在分布内 (ID) 设置和分布外 (OOD) 设置中评估 ML 模型,以确定模型的数据高效泛化性能。
评估与结果
为了评估 REMEDIS 模型的性能,我们使用回顾性的去识别数据模拟了广泛的医学成像任务和模式中的真实场景,包括皮肤病学、视网膜成像、胸部 X 光解释、病理学和乳房X 光检查。我们进一步引入了数据高效泛化的概念,捕捉了模型推广到新部署分布的能力,同时显著减少对新临床环境中专家注释数据的需求。分布内性能的衡量标准是 (1) 零样本泛化到 OOD 设置(在 OOD 评估集中评估性能,无法访问 OOD 数据集中的训练数据)的改进和 (2) 显著减少对 OOD 设置中注释数据的需求,以达到与临床专家相当的性能(或显示临床效用的阈值)。REMEDIS 表现出显着提高的分布内性能,与强监督基线相比,诊断准确率相对提高了 11.5%。
更重要的是,我们的策略可以实现医学成像模型的数据高效泛化,匹配强监督基线,从而将重新训练数据的需求减少 3-100 倍。虽然 SimCLR 是研究中使用的主要自监督学习方法,但我们还表明 REMEDIS 与其他方法兼容,例如MoCo-V2、RELIC和Barlow Twins。此外,该方法适用于各种模型架构大小。
REMEDIS 在各种医疗任务中的表现都优于在 JFT-300M 上预训练的监督基线,并展示了改进的数据高效泛化能力,将模型适应新临床环境所需的数据减少了 3-100 倍。这可能意味着临床医生注释数据的时间大大减少,开发强大的医学成像系统的成本也大大降低。
REMEDIS 与MoCo-V2、RELIC和Barlow Twins兼容,可作为替代的自监督学习策略。所有 REMEDIS 变体都比强监督基线在皮肤病分类 ( T1 )、糖尿病性黄斑水肿分类 ( T2 ) 和胸部 X 光片状况分类 ( T3 ) 方面实现了数据效率更高的泛化改进。灰色阴影区域表示在 JFT 上预训练的强监督基线的性能。
医疗人工智能研究基础
在 REMEDIS 的基础上,我们很高兴地宣布推出医疗 AI 研究基础,这是 2022 年公开发布的胸部 X 光基础的扩展。医疗 AI 研究基础是由 PhysioNet 托管的开源医疗基础模型库。这扩展了以前基于 API 的方法,还涵盖了非诊断模型,以帮助研究人员和开发人员加速他们的医疗 AI 研究。我们相信 REMEDIS 和医疗 AI 研究基础的发布是朝着构建可在医疗保健环境和任务中推广的医疗模型迈出的一步。
我们正在为医学 AI 研究基金会提供用于胸部 X 光和病理学的 REMEDIS 模型(附相关 代码)。现有的胸部 X 光基金会方法侧重于从在多个大型私有数据集上训练的模型提供用于特定应用微调的冻结嵌入,而 REMEDIS 模型(在公共数据集上训练)使用户能够针对其应用进行端到端微调,并在本地设备上运行。我们建议用户根据其所需应用的独特需求测试不同的方法。我们希望在未来添加更多用于训练医学基础模型的模型和资源,例如数据集和基准。我们也欢迎医学 AI 研究社区为此做出贡献。
结论
这些结果表明,REMEDIS 有可能显著加速医学成像 ML 系统的开发,这些系统可以在各种不断变化的环境中部署时保持其强大的性能。我们相信这是医学成像 AI 产生广泛影响的重要一步。除了所介绍的实验结果之外,这里描述的方法和见解已被整合到Google 的多个医学成像研究项目中,例如皮肤病学、乳房 X 线摄影和放射学等。我们在非成像基础模型工作中使用了类似的自监督学习方法,例如Med-PaLM和Med-PaLM 2。
通过 REMEDIS,我们展示了基础模型在医学成像应用中的潜力。此类模型在医学应用中具有令人兴奋的可能性,并具有多模态表示学习的机会。医学实践本质上是多模态的,并结合了来自图像、电子健康记录、传感器、可穿戴设备、基因组学等的信息。我们相信,使用自我监督学习大规模利用这些数据的机器学习系统,并仔细考虑隐私、安全、公平和道德,将有助于为下一代学习医疗系统奠定基础,该系统将世界一流的医疗保健扩展到每个人。
致谢
这项工作涉及来自 Google Health AI 和 Google Brain 的多学科研究人员、软件工程师、临床医生和跨职能贡献者的广泛协作。我们尤其要感谢我们的第一位合著者 Jan Freyberg 以及这些项目的首席高级作者 Vivek Natarajan、Alan Karthikesalingam、Mohammad Norouzi 和 Neil Houlsby 的宝贵贡献和支持。我们还要感谢 Lauren Winer、Sami Lachgar、Yun Liu 和 Karan Singhal 对这篇文章的反馈,以及 Tom Small 在创建视觉效果方面的支持。最后,我们还要感谢 PhysioNet 团队对托管医疗 AI 研究基金会的支持。有疑问的用户可以通过 google.com 联系 medical-ai-research-foundations。
评论