移动设备上的智能助手在执行简单的日常任务(例如设置计时器或打开手电筒)方面具有显著的语言交互能力。尽管取得了进展,但这些助手在支持移动用户界面 (UI) 中的对话交互方面仍然面临限制,因为许多用户任务都是在移动用户界面 (UI) 中执行的。例如,它们无法回答用户关于屏幕上显示的特定信息的问题。代理需要对图形用户界面(GUI) 具有计算理解能力才能实现此类功能。
先前的研究已经研究了几个重要的技术模块,以实现与移动用户界面的对话式交互,包括总结移动屏幕以便用户快速了解其用途、将语言指令映射到用户界面操作以及对 GUI 进行建模以使其更适合基于语言的交互。然而,这些技术都只解决了对话式交互的一个有限方面,并且需要在整理大规模数据集和训练专用模型方面投入大量精力。此外,移动用户界面上可以发生各种各样的对话式交互。因此,开发一种轻量级且可推广的方法来实现对话式交互势在必行。
在CHI 2023上发表的“使用大型语言模型实现与移动 UI 的对话交互” 中,我们研究了利用大型语言模型 (LLM) 实现与移动 UI 的多种基于语言的交互的可行性。最近经过预训练的 LLM,例如PaLM,已证明能够在使用少量目标任务示例提示时适应各种下游语言任务。我们提出了一组提示技术,使交互设计人员和开发人员能够快速原型化和测试与用户的新型语言交互,从而节省在投资专用数据集和模型之前的时间和资源。由于 LLM 仅将文本标记作为输入,我们贡献了一种生成移动 UI 文本表示的新算法。我们的结果表明,这种方法每个任务仅使用两个数据示例即可实现具有竞争力的性能。更广泛地说,我们展示了 LLM 从根本上改变未来对话交互设计工作流程的潜力。
通过用户界面 (UI) 提示法学硕士 (LLM)
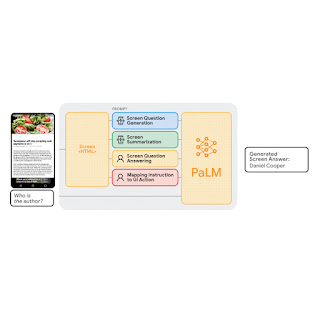
LLM 通过提示支持上下文中的小样本学习——人们可以使用目标任务中的一些输入和输出数据样本来提示 LLM,而不是为每个新任务微调或重新训练模型。对于许多自然语言处理任务(例如问答或翻译),小样本提示的表现可与为每个任务训练特定模型的基准方法相媲美。然而,语言模型只能接受文本输入,而移动 UI 是多模式的,其视图层次结构数据(即包含 UI 元素详细属性的结构数据)和屏幕截图中包含文本、图像和结构信息。此外,直接将移动屏幕的视图层次结构数据输入 LLM 是不可行的,因为它包含过多信息,例如每个 UI 元素的详细属性,这些信息可能超出 LLM 的输入长度限制。
为了应对这些挑战,我们开发了一套使用移动 UI 提示 LLM 的技术。我们贡献了一种算法,该算法使用深度优先搜索遍历将 Android UI 的视图层次结构转换为 HTML 语法,从而生成移动 UI 的文本表示。我们还利用思路链提示,即生成中间结果并将它们链接在一起以得出最终输出,以引出 LLM 的推理能力。
我们的提示设计以解释提示目的的序言开始。序言后面是多个示例,包括输入、思路链(如果适用)和每个任务的输出。每个示例的输入都是 HTML 语法中的移动屏幕。在输入之后,可以提供思路链以从 LLM 中引出逻辑推理。此步骤未在上面的动画中显示,因为它是可选的。任务输出是目标任务的期望结果,例如屏幕摘要或对用户问题的回答。如果提示中包含多个示例,则可以实现少量提示。在预测过程中,我们向模型提供提示,并在末尾附加一个新的输入屏幕。
实验
我们对四个关键建模任务进行了全面的实验:(1)屏幕问题生成、(2)屏幕摘要、(3)屏幕问答和(4)将指令映射到 UI 操作。实验结果表明,我们的方法在每个任务中仅使用两个数据示例即可实现具有竞争力的性能。
任务 1:筛选问题生成
给定一个移动 UI 屏幕,屏幕问题生成的目标是合成与需要用户输入的 UI 元素相关的连贯、语法正确的自然语言问题。
我们发现 LLM 可以利用 UI 上下文来生成相关信息的问题。在问题质量方面,LLM 明显优于启发式方法(基于模板的生成)。
我们还展示了 LLM 能够将相关输入字段组合成一个问题,以实现高效沟通。例如,询问最低和最高价格的过滤器被组合成一个问题:“价格范围是多少?”
在评估中,我们征求了人工评分,以判断问题在语法上是否正确(语法)以及是否与生成问题的输入字段相关(相关性)。除了人工标记的语言质量外,我们还自动检查了 LLM 对生成问题所需的所有元素的覆盖程度(覆盖率F1)。我们发现 LLM 生成的问题语法近乎完美(4.98/5),并且与屏幕上显示的输入字段高度相关(92.8%)。此外,LLM 在全面覆盖输入字段方面表现良好(95.8%)。
任务 2:屏幕摘要
屏幕摘要是自动生成描述性语言概述的过程,涵盖移动屏幕的基本功能。此任务可帮助用户快速了解移动 UI 的用途,当 UI 无法直观访问时,此功能尤其有用。
我们的结果表明,LLM 可以有效地总结移动 UI 的基本功能。它们可以生成比我们之前使用 UI 特定文本引入的Screen2Words基准模型更准确的摘要,如下方彩色文本和方框中突出显示的那样。
有趣的是,我们观察到 LLM 在创建摘要时使用他们的先验知识推断出 UI 中未显示的信息。在下面的示例中,LLM 推断地铁站属于伦敦地铁系统,而输入 UI 不包含此信息。
人工评估认为 LLM 摘要比基准更准确,但它们在BLEU等指标上的得分较低。感知质量和指标得分之间的不匹配与最近的研究结果相呼应,该研究表明,尽管自动指标没有反映这一点,但 LLM 撰写的摘要更好。
任务 3:屏幕问答
给定一个移动用户界面和一个询问有关用户界面信息的开放式问题,模型应该提供正确的答案。我们专注于事实问题,这些问题需要根据屏幕上显示的信息给出答案。
我们使用四个指标来报告性能:精确匹配(预测答案与基本事实相同)、包含 GT(答案完全包含基本事实)、GT 的子字符串(答案是基本事实的子字符串)以及基于整个数据集上预测答案和基本事实之间共享词的 Micro-F1分数。
我们的结果表明,LLM 可以正确回答与 UI 相关的问题,例如“标题是什么?”。LLM 的表现明显优于基线 QA 模型DistillBERT,完全正确答案率达到 66.7%。值得注意的是,0-shot LLM 的精确匹配得分为 30.7%,表明该模型具有内在的问答能力。
任务 4:将指令映射到 UI 操作
给定一个移动 UI 屏幕和用于控制 UI 的自然语言指令,模型需要预测对象的 ID 以执行指示的操作。例如,当使用“打开 Gmail”指令时,模型应该正确识别主屏幕上的 Gmail 图标。此任务对于使用语言输入(例如语音访问)控制移动应用很有用。我们之前介绍过这个基准测试任务。
我们使用Seq2Act论文 中的部分和完整指标评估了我们方法的性能。部分是指正确预测的单个步骤的百分比,而完整则衡量准确预测的整个交互轨迹的比例。虽然我们基于 LLM 的方法没有超越在海量数据集上训练的基准,但它仍然仅使用两个提示数据示例就取得了非凡的性能。
模型 部分的 完全的
0 次法学硕士 1.29 0.00
1 次 LLM 课程 (跨应用程序) 74.69 31.67
2 次 LLM 学习 (跨应用程序) 75.28 34.44
1 次法学硕士 (应用内) 78.35 40.00
2 次法学硕士 (应用内) 80.36 45.00
顺序2动作 89.21 70.59
总结
我们的研究表明,在移动 UI 上设计新颖的语言交互原型就像设计数据样本一样简单。因此,交互设计师可以快速创建功能模型,以便与最终用户一起测试新想法。此外,开发人员和研究人员可以在投入大量精力开发新数据集和模型之前探索目标任务的不同可能性。
我们研究了使用 LLM 实现移动 UI 上各种对话交互的可行性。我们提出了一套用于将 LLM 适配到移动 UI 的提示技术。我们对四个重要的建模任务进行了广泛的实验,以评估我们方法的有效性。结果表明,与由昂贵的数据收集和模型训练组成的传统机器学习流程相比,人们可以使用 LLM 快速实现新颖的基于语言的交互,同时获得具有竞争力的性能。
致谢
我们感谢论文合著者 Gang Li,并感谢同事 Chin-Yi Cheng、Tao Li、Yu Hsiao、Michael Terry 和 Minsuk Chang 的讨论和反馈。特别感谢 Muqthar Mohammad 和 Ashwin Kakarla 在协调数据收集方面提供的宝贵帮助。我们感谢 John Guilyard 帮助在博客中创建动画和图形。
评论