肤色是一种可观察的主观特征,每个人的感知都不同(例如,取决于他们的位置或文化),因此注释起来很复杂。也就是说,可靠而准确地注释肤色的能力在计算机视觉中非常重要。这一点在 2018 年变得显而易见,当时Gender Shades研究强调计算机视觉系统难以检测肤色较深的人,并且对肤色较深的女性表现尤其不佳。该研究强调了计算机研究人员和从业人员在整个肤色范围内和身份交叉点评估他们的技术的重要性。除了评估模型在肤色方面的表现之外,肤色注释还使研究人员能够衡量图像检索系统、数据集收集和图像生成中的多样性和代表性。对于所有这些应用,收集有意义且包容性的肤色注释是关键。
去年,为了向更具包容性的计算机视觉系统迈进,Google负责任的 AI 和以人为本的技术研究团队与Ellis Monk 博士合作,公开发布了Monk 肤色(MST) 量表,这是一种可以捕捉各种肤色的肤色量表。与专为皮肤病学设计的Fitzpatrick 皮肤类型量表等行业标准量表相比,MST 提供了更具包容性的跨肤色范围表示,并且专为包括计算机视觉在内的广泛应用而设计。
今天,我们宣布推出Monk Skin Tone Examples (MST-E) 数据集,以帮助从业者了解 MST 量表并培训他们的人工注释者。此数据集已公开,使世界各地的从业者能够创建更一致、更包容、更有意义的肤色注释。除了此数据集外,我们还围绕 MST 量表和 MST-E 数据集提供了一组建议(如下所述),以便我们都能创建适合所有肤色的产品。
自从我们推出 MST 以来,我们一直在使用它来改进 Google 的计算机视觉系统,以便为每个人提供公平的图像工具,并改善搜索中肤色的表示。Google 以外的计算机视觉研究人员和从业者(例如 MetaAI 的 Casual Conversations数据集的管理员)都认识到 MST 注释的价值,它可以提供有关数据集多样性和表示的更多见解。将这些注释纳入广泛可用的数据集对于让每个人都能够确保他们正在构建更具包容性的计算机视觉技术以及能够在各种肤色中测试其系统和产品的质量至关重要。
我们的团队一直在进行研究,以了解如何继续加深对计算机视觉中肤色的理解。我们关注的核心领域之一是肤色注释,即要求人类注释者查看人物图像并选择最能代表其肤色的图像的过程。MST 注释可以更好地理解各种肤色数据集的包容性和代表性,从而使研究人员和从业人员能够评估其数据集和模型的质量和公平性。为了更好地了解 MST 注释的有效性,我们问了自己以下问题:
不同地理位置的人们对肤色有何看法?
全球范围内对于肤色的共识是什么样的?
我们如何有效地注释肤色以用于包容性机器学习(ML)?
MST-E 数据集
MST -E 数据集包含 19 个主题的 1,515 张图片和 31 个视频,涵盖 10 分制 MST 量表,主题和图片均来自TONL,这是一家专注于多样性的素材摄影公司。这 19 个主题包括不同种族和性别认同的个人,以帮助人类注释者将肤色概念与种族区分开来。该数据集的主要目标是使从业者能够训练他们的人类注释者,并在各种环境捕捉条件下测试一致的肤色注释。
为减少因季节或其他时间因素造成的肤色变化,我们在一天内收集了受试者的所有图像。每位受试者都以各种姿势、面部表情和光照条件拍照。此外,Monk 博士还为每个受试者标注了肤色标签,然后为每个受试者选择了一张最能代表其肤色的“黄金”图像。在我们的研究中,我们将人类注释者所做的注释与社会认知和不平等方面的学术专家 Monk 博士所做的注释进行了比较。
形成 MST 注释共识的挑战
尽管人们很容易看到肤色,但由于技术问题和人类社会感知的复杂性,对多个人的肤色进行系统地注释却具有挑战性。
从技术角度来看,像素化、图像的光照条件或个人显示器设置等因素都会影响肤色在屏幕上的显示效果。下次您在观看节目时更改显示设置时,您可能会注意到这一点。色调、饱和度和亮度都可能影响肤色在显示器上的显示效果。尽管存在这些挑战,但我们发现,人类注释者在注释肤色时能够学会不受图像光照条件的影响。
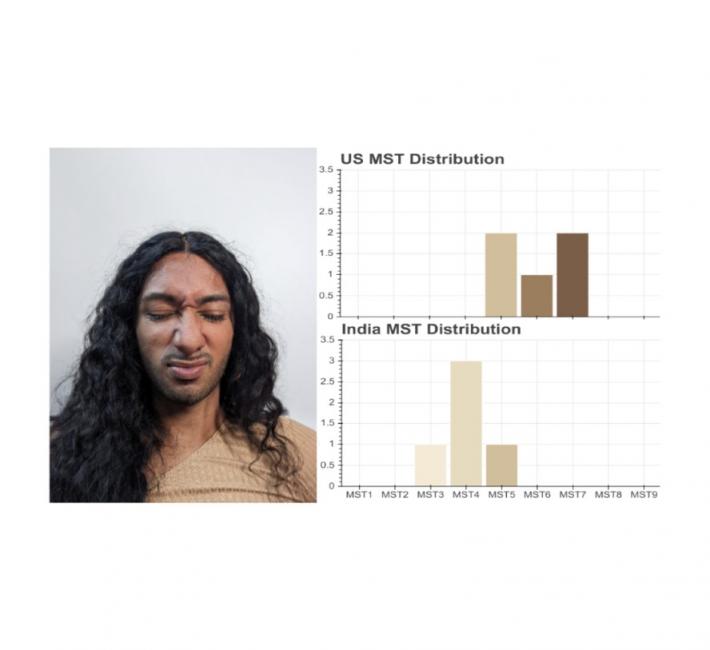
在社会认知方面,一个人的生活的各个方面,例如他们的位置、文化和生活经历,可能会影响他们如何注释各种肤色。当我们要求美国摄影师和印度摄影师注释同一张照片时,我们发现了一些证据。美国摄影师认为这个人的肤色介于 MST-5 和 MST-7 之间。然而,印度摄影师认为这个人的肤色介于 MST-3 和 MST-5 之间。
为了继续探索,我们邀请了来自五个不同地理区域(印度、菲律宾、巴西、匈牙利和加纳)的经过培训的注释者,让他们根据 MST 尺度注释肤色。每个市场中的每张图片都有 5 名注释者,他们来自该地区更广泛的注释者群体。例如,我们可以在一个市场中有 20 名注释者,并从中选择 5 名来审核特定图片。
通过这些注释,我们发现了两个重要的细节。首先,同一区域内的注释者对单幅图像的一致性程度相似。其次,不同区域之间的注释平均而言存在显著差异。(p<0.05)。这表明来自同一地理区域的人可能对肤色有相似的心理模型,但这种心理模型并不具有普遍性。
然而,即使存在这些区域差异,我们也发现所有五个区域之间的共识都接近 Monk 博士提供的 MST 值。这表明地理上分散的注释者群体可以接近 MST 专家注释的 MST 值。此外,经过训练后,我们发现光线充足的图像和光线不足的图像上的注释之间没有显著差异,这表明注释者可以对图像中的不同光照条件保持不变——这对于 ML 模型来说是一项不简单的任务。
MST-E 数据集允许研究人员研究注释者在控制潜在混杂因素的情况下跨精选子集的行为。我们在注释包含更多受试者的更大数据集时观察到了类似的区域差异。
肤色注释建议
我们的研究包括四个主要发现。首先,相似地理区域内的注释者对肤色具有一致且共享的心理模型。其次,这些心理模型在不同的地理区域有所不同。第三,来自地理上分散的注释者的 MST 注释共识与社会认知和不平等专家提供的注释一致。第四,注释者在注释 MST 时可以学会不受光照条件影响。
根据我们的研究结果,在使用 MST 进行肤色注释时,有几点建议。
拥有一批来自不同地理位置的注释者对于获得准确或接近真实的肤色估计非常重要。
使用MST-E 数据集训练人工注释者,该数据集涵盖整个 MST 光谱,包含各种光照条件下的图像。这将有助于注释者不受光照条件的影响,并理解 MST 点之间的细微差别和差异。
鉴于注释范围广泛,我们建议至少在五个不同的地理区域配备两名注释者(每幅图像 10 个评级)。
与其他主观注释任务一样,肤色注释虽然困难,但并非不可能。这些类型的注释可以让我们更细致地了解模型性能,最终帮助我们创造出适合各种肤色的每个人的产品。
致谢
我们要感谢 Google 内部致力于计算机视觉公平性和包容性的同事对这项工作的贡献,特别是 Marco Andreetto、Parker Barnes、Ken Burke、Benoit Corda、Tulsee Doshi、Courtney Heldreth、Rachel Hornung、David Madras、Ellis Monk、Shrikanth Narayanan、Utsav Prabhu、Susanna Ricco、Sagar Savla、Alex Siegman、Komal Singh、Biao Wang 和 Auriel Wright。我们还要感谢 Annie Jean-Baptiste、Florian Koenigsberger、Marc Repnyek、Maura O'Brien 和 Dominique Mungin 以及团队中帮助监督、资助和协调我们数据收集的其他成员。
评论