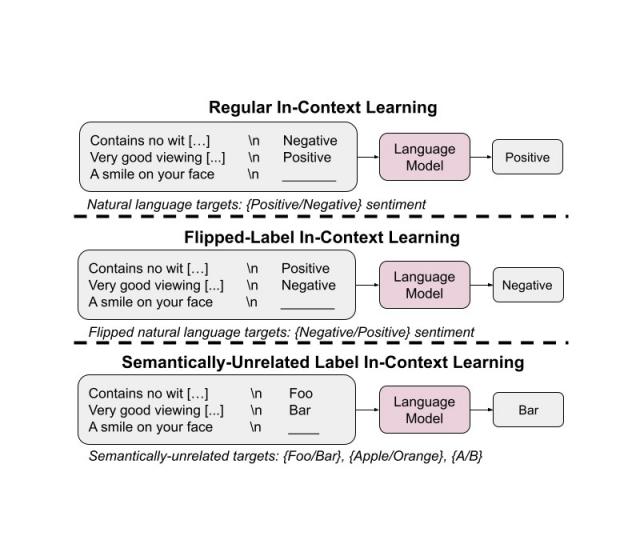
语言模型最近取得了巨大进步,部分原因是它们可以通过情境学习(ICL) 出色地完成任务,该过程通过向模型提供一些输入标签对示例,然后对未见过的评估示例执行任务。一般而言,模型在情境学习方面的成功取决于以下因素:
他们使用来自预训练的语义先验知识来预测标签,同时遵循上下文示例的格式(例如,查看以“积极情绪”和“消极情绪”作为标签的电影评论示例,并使用先验知识进行情绪分析)。
从所呈现的示例中学习上下文中的输入标签映射(例如,找到一个模式,即正面评价应该映射到一个标签,而负面评价应该映射到不同的标签)。
在“更大的语言模型以不同的方式进行上下文学习”中,我们旨在了解这两个因素(语义先验和输入标签映射)在 ICL 设置中如何相互作用,尤其是在所使用的语言模型的规模方面。我们调查了两种设置来研究这两个因素——带有翻转标签的 ICL(翻转标签 ICL)和带有语义无关标签的 ICL(SUL-ICL)。在翻转标签 ICL 中,上下文示例的标签被翻转,因此语义先验和输入标签映射彼此不一致。在 SUL-ICL 中,上下文示例的标签被替换为与上下文中呈现的任务在语义上无关的单词。我们发现,覆盖先验知识是模型规模的一种新兴能力,使用语义无关的标签进行上下文学习的能力也是如此。我们还发现,指令调整加强了先验知识的使用,而不是增加了学习输入标签映射的能力。
与常规 ICL 相比,翻转标签 ICL 和语义无关标签 ICL (SUL-ICL) 概述了情绪分析任务。翻转标签 ICL 使用翻转标签,迫使模型覆盖语义先验以遵循上下文示例。SUL-ICL 使用与任务在语义上不相关的标签,这意味着模型必须学习输入标签映射才能执行任务,因为它们不能再依赖自然语言标签的语义。
实验设计
对于多样化的数据集混合,我们对七种广泛使用的自然语言处理(NLP) 任务进行了实验:情绪分析、主观/客观分类、问题分类、重复问题识别、蕴涵识别、金融情绪分析和仇恨言论检测。我们测试了五种语言模型系列,PaLM、Flan-PaLM、GPT-3、InstructGPT和Codex。
翻转标签
在这个实验中,上下文示例的标签被翻转,这意味着先验知识和输入标签映射不一致(例如,包含积极情绪的句子被标记为“消极情绪”),从而让我们研究模型是否可以覆盖其先验知识。在这种情况下,能够覆盖先验知识并在上下文中学习输入标签映射的模型应该会经历性能下降(因为真实评估标签没有翻转)。
在呈现翻转的上下文示例标签时,覆盖语义先验的能力随着模型规模的扩大而显现。较小的模型无法翻转预测以遵循翻转的标签(性能仅略有下降),而较大的模型可以做到这一点(性能下降到 50% 以下)。
我们发现,当没有标签翻转时,较大的模型比较小的模型具有更好的性能(正如预期的那样)。但是当我们翻转越来越多的标签时,小模型的性能保持相对平稳,而大模型的性能会大幅下降,远低于随机猜测(例如,code-davinci-002 的 90% → 22.5%)。
这些结果表明,当上下文中出现相互矛盾的输入标签映射时,大型模型可以覆盖预训练中的先验知识。小型模型无法做到这一点,这使得这种能力成为模型规模的新兴现象。
语义不相关的标签
在这个实验中,我们用语义上不相关的标签替换标签(例如,对于情绪分析,我们使用“foo/bar”而不是“negative/positive”),这意味着模型只能通过从输入标签映射中学习来执行 ICL。如果模型主要依赖于 ICL 的先验知识,那么它的性能在这种变化之后应该会下降,因为它将不再能够使用标签的语义含义来进行预测。另一方面,能够在上下文中学习输入标签映射的模型将能够学习这些语义上不相关的映射,并且性能不会大幅下降。
小型模型比大型模型更依赖语义先验,当使用语义不相关的标签(即目标)而不是自然语言标签时,小型模型的性能下降幅度大于大型模型。对于每个图,模型按模型大小的增加顺序显示(例如,对于 GPT-3 模型,a小于b, b 小于c)。
事实上,我们发现使用语义上不相关的标签会导致小型模型的性能下降。这表明小型模型主要依赖于其语义先验来进行 ICL,而不是从所呈现的输入标签映射中学习。另一方面,当标签的语义性质被移除时,大型模型能够在上下文中学习输入标签映射。
我们还发现,包含更多的上下文示例(即范本)会给大型模型带来比小型模型更大的性能提升,这表明大型模型比小型模型更善于从上下文示例中学习。
在 SUL-ICL 设置中,较大的模型比较小的模型从额外的示例中受益更多。
指令调优
指令调优是一种提高模型性能的流行技术,它涉及在各种以指令形式表达的 NLP 任务上调优模型(例如,“问题:以下句子‘这部电影很棒。’的情绪是什么。答案:积极”)。然而,由于该过程使用自然语言标签,因此一个悬而未决的问题是它是否提高了学习输入标签映射的能力,或者它是否增强了识别和应用语义先验知识的能力。这两者都会导致标准 ICL 任务的性能提升,因此不清楚其中哪一种会发生。
我们通过运行与之前相同的两个设置来研究这个问题,只是这次我们专注于比较标准语言模型(具体来说,PaLM)与它们的指令调整变体(Flan-PaLM)。
首先,我们发现,当我们使用语义不相关的标签时,Flan-PaLM 比 PaLM 更好。这种效果在小型模型中非常明显,因为 Flan-PaLM-8B 的表现比 PaLM-8B 高出 9.6%,几乎赶上了 PaLM-62B。这一趋势表明指令调整增强了学习输入标签映射的能力,这并不奇怪。
指令调整语言模型在学习输入标签映射方面比仅有预训练的语言模型更好。
更有趣的是,我们发现 Flan-PaLM 在遵循翻转标签方面实际上比 PaLM 更差,这意味着指令调整模型无法覆盖其先验知识(Flan-PaLM 模型在 100% 翻转标签的情况下无法达到随机猜测以下的准确率,但没有指令调整的 PaLM 模型在相同设置下可以达到 31% 的准确率)。这些结果表明,指令调整必须增加模型在可用时对语义先验的依赖程度。
当在上下文中呈现翻转标签时,指令调整模型在学习覆盖语义先验方面比仅有预训练的模型更差。
结合前面的结果,我们得出结论:虽然指令调整提高了学习输入标签映射的能力,但它更多地加强了语义先验知识的使用。
结论
我们研究了语言模型利用预训练期间学到的先验知识与上下文中呈现的输入标签映射进行上下文学习的程度。
我们首先表明,大型语言模型在呈现足够多的翻转标签时可以学会覆盖先验知识,并且这种能力随着模型规模的扩大而出现。然后我们发现,使用语义上不相关的标签成功进行 ICL 是模型规模的另一个新兴能力。最后,我们分析了指令调整语言模型,发现指令调整不仅提高了学习输入标签映射的能力,而且还进一步加强了语义先验知识的使用。
未来工作
这些结果强调了语言模型的 ICL 行为如何根据其规模而变化,并且更大的语言模型具有将输入映射到多种类型标签的新兴能力,这是一种推理形式,其中可以学习任意符号的输入标签映射。未来的研究可以帮助深入了解为什么这些现象与模型规模有关。
致谢
这项工作由 Jerry Wei、Jason Wei、Yi Tay、Dustin Tran、Albert Webson、Yifeng Lu、Xinyun Chen、Hanxiao Liu、Da Huang、Denny Zhou 和 Tengyu Ma 完成。我们要感谢 Sewon Min 和 Google Research 的同事们提供的建议和有益的讨论。
评论