PAIR(People + AI Research)于 2017 年首次启动,其理念是“如果我们在构建系统之初就考虑到人,那么人工智能可以走得更远,对我们所有人都更有用。”我们将继续致力于让人工智能更易于理解、更易于解释、更有趣,并可供全世界更多人使用。鉴于生成式人工智能和聊天机器人的出现,这项使命尤为及时。
如今,PAIR 是 Google Research 内负责任的 AI 和以人为本的技术团队 的一部分,我们的工作涵盖了更大的研究领域:我们推进人机交互 (HAI) 和机器学习 (ML) 的基础研究;我们发布教育材料,包括PAIR 指南和Explorables(例如最近的 Explorable,探讨了模型有时会自信地做出错误预测的原因和方式);我们开发了学习可解释性工具等软件工具,帮助人们理解和调试 ML 行为。我们今年的灵感是“改变人们对 AI 的思考方式”。这一愿景受到生成式 AI 技术的快速兴起的启发,例如为Bard等聊天机器人提供支持的大型语言模型 (LLM),以及 Google 的Imagen、Parti和MusicLM等新的生成媒体模型。在这篇博文中,我们回顾了最近的 PAIR 工作,这些工作正在改变我们与 AI 互动的方式。
生成式人工智能研究
生成式人工智能正在引起人们的极大兴趣,PAIR 参与了一系列相关研究,从使用语言模型创建生成代理 ,到研究艺术家如何采用Imagen和Parti等生成式图像模型。这些“文本到图像”模型允许人们输入基于文本的图像描述,然后由模型生成(例如,“卡通风格的森林中的姜饼屋”)。在一篇即将发表的论文《及时艺术家》(将发表在《创造力与认知》2023 年)中,我们发现生成式图像模型的用户不仅努力创造美丽的图像,还努力创造独特、创新的风格。为了实现这些风格,有些人甚至会寻找独特的词汇来帮助发展他们的视觉风格。例如,他们可能会访问建筑博客,了解他们可以采用哪些领域特定的词汇来帮助制作独特的建筑图像。
我们还在研究如何解决提示创建者面临的挑战,他们使用生成式 AI 进行编程时,本质上无需使用编程语言。例如,我们开发了从自然语言提示中提取语义上有意义的结构的新方法。我们已将这些结构应用于提示编辑器,以提供与其他编程环境中类似的功能,例如语义突出显示、自动建议和结构化数据视图。
生成式 LLM 的发展也为解决长期存在的重要问题开辟了新的技术。敏捷分类器是我们利用 LLM 的语义和句法优势解决与更安全的在线言论相关的分类问题的方法之一,例如,灵活地阻止新类型的有害语言,因为这些语言在网上可能会迅速发展。这里最大的进步是能够从非常小的数据集(小到 80 个示例)开发高质量的分类器。这表明在线言论的未来是光明的,并且会对其进行更好的管理:个人或小型组织可以创建更敏捷的分类器,并根据其特定用例进行量身定制,并在一天的时间内进行迭代和调整(例如,阻止收到新的骚扰或纠正模型中的意外偏见),而不是收集数百万个示例以尝试在数月或数年内为所有用例创建通用安全分类器。
我们还开发了新的最先进的可解释性方法,以确定训练数据对模型行为和错误行为的作用。通过将训练数据归因方法与敏捷分类器相结合,我们还发现可以识别错误标记的训练示例。这使得减少训练数据中的噪音成为可能,从而显著提高模型准确性。
总的来说,这些方法对于帮助科学界改进生成模型至关重要。它们提供了快速有效的内容审核技术和对话安全方法,帮助支持内容是生成模型惊人成果基础的创作者。此外,它们还提供直接工具来帮助调试模型错误行为,从而实现更好的生成。
可视化与教育
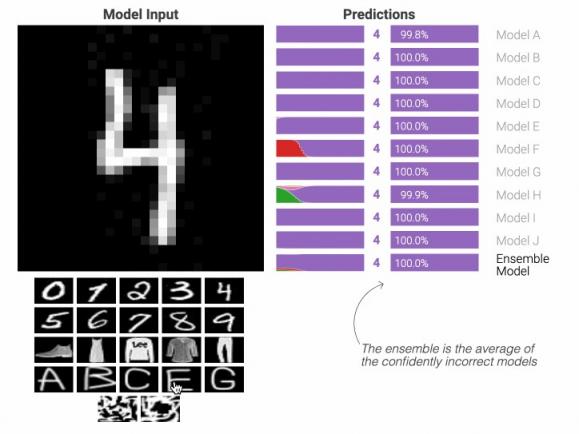
为了降低理解 ML 相关工作的障碍,我们定期设计和发布高度可视化、交互式的在线文章,称为AI Explorables,提供易于理解、亲自动手的方式来学习 ML 中的关键思想。例如,我们最近发布了关于模型置信度和意外偏差主题的新 AI Explorables。在我们最新的 Explorable“从自信错误的模型到谦逊的集成”中,我们讨论了模型置信度的问题:模型有时对其预测非常有信心……但却完全不正确。为什么会发生这种情况?我们该如何解决?我们的 Explorable 通过交互式示例逐步介绍这些问题,并展示如何使用一种称为ensembling的技术构建对其预测具有更适当置信度的模型,该技术的工作原理是取多个模型的输出平均值。另一个探索性内容“利用显著性寻找非预期偏差”展示了虚假相关性如何导致非预期偏差,以及显著性图等技术如何检测数据集中的某些偏差,但需要注意的是,当偏差在训练集中较为微妙和零星时,可能很难被发现。
PAIR 设计并发布 AI Explorables、有关机器学习研究中的及时主题和新方法的交互式文章,例如“从自信错误的模型到谦逊的集成”,该文研究模型如何以及为何以高置信度提供错误预测,以及如何“集成”许多模型的输出来帮助避免这种情况。
透明度和数据卡手册
为了继续推进帮助人们了解 ML 的目标,我们提倡透明的文档。过去,PAIR 和 Google Cloud 开发了模型卡。最近,我们在ACM FAccT'22上展示了我们在数据卡方面的工作,并开源了数据卡手册,这是与技术、人工智能、社会和文化团队(TASC)的共同努力。数据卡手册是一套参与活动和框架工具包,可帮助团队和组织在建立透明度工作时克服障碍。它是使用一种迭代、多学科方法创建的,这种方法植根于 Google 20 多个团队的经验,并包含四个模块:询问、检查、回答和审核。这些模块包含各种资源,可帮助您根据组织的需求自定义数据卡:
18 个基础:任何人都可以在任何数据集类型上使用的可扩展框架
19 透明度模式:大规模生产高质量数据卡的循证指导
33 项参与活动:跨职能研讨会,帮助团队应对透明度挑战
交互式实验室:在浏览器中通过 Markdown 生成交互式数据卡
数据卡剧本可以作为初创企业、大学和其他研究团体的学习途径。
软件工具
我们的团队致力于创建工具、工具包、库和可视化,以扩展访问权限并提高对 ML 模型的理解。了解您的数据就是这样一种资源,它允许研究人员通过交互式定性探索数据集来测试模型在各种场景下的性能,他们可以使用这些数据集来查找和修复意外的数据集偏差。
最近,PAIR 发布了新版学习可解释性工具(LIT),用于模型调试和理解。LIT v0.5 提供了对图像和表格数据的支持、用于表格特征归因的新解释器、用于分面数据探索的“Dive”可视化,以及允许 LIT 扩展到 10 万个数据集条目的性能改进。您可以在 GitHub 上找到发行说明和代码。
PAIR 的学习可解释性工具(LIT),一个用于可视化和理解 ML 模型的开源平台。
PAIR 还为MakerSuite 做出了贡献,这是一款使用即时编程快速进行 LLM 原型设计的工具。MakerSuite 以我们之前对PromptMaker的研究为基础,该研究在CHI 2022上获得了荣誉奖。MakerSuite 通过扩大可以编写这些原型的人员类型并将原型设计模型所花费的时间从数月缩短到数分钟,降低了原型设计 ML 应用程序的门槛。
MakerSuite 的屏幕截图,MakerSuite 是一种使用基于提示的编程快速制作新 ML 模型原型的工具,它源于 PAIR 的提示编程研究。
正在进行的工作
随着人工智能世界的快速发展,PAIR 很高兴继续开发新的工具、研究和教育材料,以帮助改变人们对如何使用人工智能的看法。
例如,我们最近与五位设计师进行了一项探索性研究(今年在CHI上进行了展示),研究没有 ML 编程经验或培训的人如何使用快速编程快速制作功能性用户界面模型。这种原型制作速度可以帮助设计师了解如何将 ML 模型集成到产品中,并使他们能够在产品设计过程中更快地进行用户研究。
基于这项研究,PAIR 的研究人员开发了PromptInfuser,这是一款用于编写 LLM 注入模型的设计工具插件。该插件引入了两种新颖的 LLM 交互:输入输出,使内容具有交互性和动态性;以及框架更改,根据用户的自然语言输入将用户引导到不同的框架。结果是更紧密集成的 UI 和 ML 原型设计,所有这些都在一个界面中完成。
人工智能的最新进展代表了研究人员在定制和控制模型以实现其研究目标和目的方面发生了重大转变。这些功能正在改变我们思考与人工智能互动的方式,并为研究界创造了许多新的机会。PAIR 对如何利用这些功能让更多人更轻松地使用人工智能感到非常兴奋。
致谢
感谢 PAIR 中的每个人、Reena Jana 以及我们所有的合作者。
评论