深度学习最近在一系列问题和应用中取得了巨大进展,但模型在部署到未知域或分布中时往往会出乎意料地失败。无源域自适应(SFDA) 是一个研究领域,旨在设计方法,将预训练模型(在“源域”上训练)适配到新的“目标域”,仅使用后者的未标记数据。
设计深度模型的适应方法是一个重要的研究领域。虽然模型和训练数据集的规模不断扩大是其成功的关键因素,但这种趋势的一个负面后果是训练此类模型的计算成本越来越高,在某些情况下,大型模型训练变得更加困难,并且不必要地增加了碳足迹。缓解这一问题的一种方法是设计能够利用和重用已经训练过的模型来解决新任务或推广到新领域的技术。事实上,在迁移学习的范畴内,将模型适应新任务的研究非常广泛。
SFDA 是本研究中一个特别实用的领域,因为现实世界中许多需要适应性的应用都因缺乏目标域的标记示例而受苦。事实上,SFDA 正受到越来越多的关注 [ 1 , 2 , 3 , 4 ]。然而,尽管有雄心勃勃的目标,但大多数 SFDA 研究都基于一个非常狭窄的框架,仅考虑图像分类任务中的简单分布变化。
与这一趋势截然不同的是,我们将注意力转向了生物声学领域,该领域中自然发生的分布变化无处不在,通常以目标标记数据不足为特征,对从业者来说是一个障碍。因此,在这一应用中研究 SFDA 不仅可以让学术界了解现有方法的普遍性并确定开放的研究方向,还可以直接使该领域的从业者受益,并有助于解决本世纪最大的挑战之一:生物多样性保护。
在这篇文章中,我们宣布了“寻找一种可推广的无源域自适应方法”,该文章将在ICML 2023上发表。我们表明,当面对生物声学中真实的分布变化时,最先进的 SFDA 方法可能会表现不佳甚至崩溃。此外,现有方法彼此之间的表现与视觉基准中观察到的有所不同,令人惊讶的是,有时表现比根本没有适应还要差。我们还提出了 NOTELA,这是一种新的简单方法,它在这些变化上的表现优于现有方法,同时在一系列视觉数据集上表现出强大的性能。总的来说,我们得出的结论是,仅对常用数据集和分布变化评估 SFDA 方法会让我们对它们的相对性能和通用性产生短视的看法。为了实现他们的承诺,SFDA 方法需要在更广泛的分布变化上进行测试,我们主张考虑可以使高影响力应用受益的自然发生的方法。
生物声学的分布变化
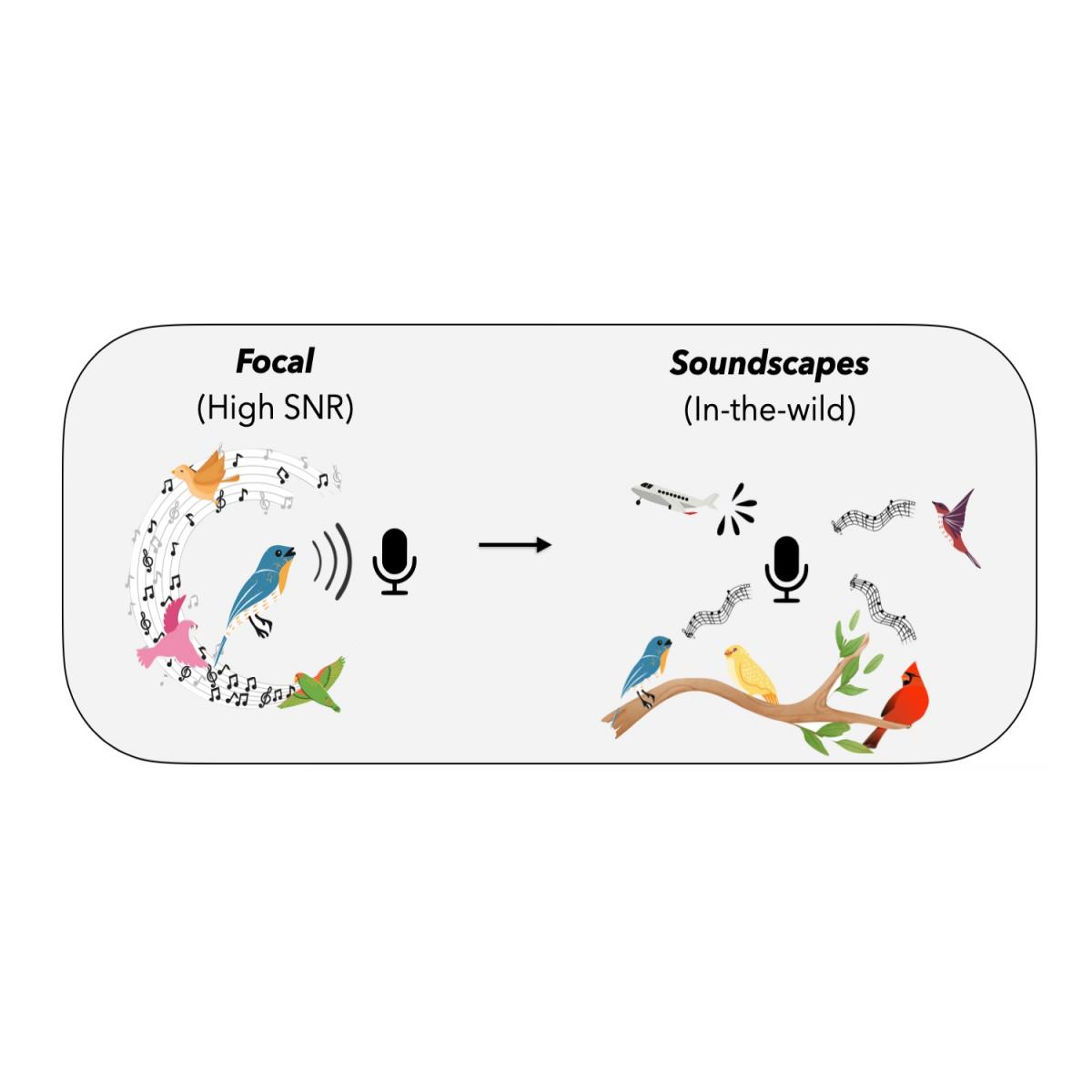
自然发生的分布变化在生物声学中普遍存在。最大的带标签鸟鸣数据集是Xeno-Canto (XC),它是用户贡献的来自世界各地的野生鸟类录音的集合。XC 中的录音是“焦点”的:它们以自然条件下捕获的个体为目标,其中已识别鸟的歌声位于前景。但出于持续监测和跟踪的目的,从业者往往对识别通过全向麦克风获得的被动录音(“声景”)中的鸟类更感兴趣。这是一个有据可查的问题,最近的 研究表明它非常具有挑战性。受这一现实应用的启发,我们使用在 XC 上预先训练的鸟类分类器作为源模型,以及来自不同地理位置的几个“声景”——内华达山脉(内华达州南部);美国宾夕法尼亚州Powdermill自然保护区;夏威夷;美国加利福尼亚州卡普尔斯流域;Sapsucker Woods、美国纽约州(SSW)和哥伦比亚— — 作为我们的目标域名。
从聚焦域到被动域的转变意义重大:后者的录音通常具有低得多的信噪比,几只鸟同时发出叫声,并且有明显的干扰和环境噪音,如雨或风。此外,不同的声音景观来自不同的地理位置,导致标签极端偏移,因为 XC 中只有很小一部分物种会出现在给定位置。此外,与现实世界数据中常见的情况一样,源域和目标域都存在严重的类别不平衡,因为某些物种比其他物种更常见。此外,我们考虑了一个多标签分类问题,因为每个录音中可能会识别出几只鸟,这与通常研究 SFDA 的标准单标签图像分类场景有很大不同。
“焦点→音景”转变的图示。在焦点域中,录音通常由前景中的单只鸟叫声组成,以高信噪比 (SNR) 捕获,尽管背景中可能还有其他鸟叫声。 另一方面,音景包含来自全向麦克风的录音,可以由多只鸟同时发声以及来自昆虫、雨水、汽车、飞机等的环境噪音组成。
音频文件 焦域
音景领域1
频谱图像
就每个数据集中代表性录音的音频文件(顶部)和频谱图图像(底部)而言,从焦点域(左)到声景域(右)的分布转移图示。请注意,在第二个音频片段中,鸟鸣声非常微弱;这是声景录音中的常见特性,因为鸟叫声不在“前景”中。鸣谢:左: Sue Riffe 的XC录音( CC-BY-NC 许可证)。右:摘自 Kahl、Charif 和 Klinck 提供的录音。(2022 年)“来自美国东北部的全注释声景录音集” [链接] 来自 SSW 声景数据集(CC-BY 许可证)。
最先进的 SFDA 模型在生物声学转变方面表现不佳
首先,我们根据生物声学基准对六种最先进的 SFDA 方法进行了基准测试,并将它们与未适应的基线(源模型)进行了比较。我们的发现令人惊讶:现有方法无一例外地无法在所有目标域上始终优于源模型。事实上,它们的表现往往远远低于源模型。
举例来说,最近提出的方法Tent旨在通过减少模型输出概率的不确定性,使模型对每个示例做出自信的预测。虽然 Tent 在各种任务中都表现良好,但对我们的生物声学任务却效果不佳。在单标签场景中,最小化熵会迫使模型为每个示例自信地选择一个类。但是,在我们的多标签场景中,不存在任何类都应被选择为存在的约束。再加上显著的分布变化,这可能会导致模型崩溃,导致所有类别的概率为零。其他基准测试方法,如SHOT、AdaBN、Tent、NRC、DUST和Pseudo-Labelling,它们是标准 SFDA 基准测试的强大基线,但在完成这项生物声学任务时也遇到了困难。
在六个音景数据集的整个适应过程中,测试平均精度(mAP)(多标签分类的标准指标)的演变。我们对我们提出的 NOTELA 和 Dropout Student(见下文)以及SHOT、AdaBN、Tent、NRC、DUST和Pseudo-Labelling进行了基准测试。除了 NOTELA 之外,所有其他方法都无法持续改进源模型。
引入带拉普拉斯调整的 NOisy student TEacher (NOTELA)
尽管如此,一个令人惊讶的积极结果脱颖而出:不那么出名的Noisy Student原则似乎很有希望。这种无监督方法鼓励模型在某些目标数据集上重建自己的预测,但会应用随机噪声。虽然噪声可能通过各种渠道引入,但我们力求简单,并使用模型 dropout作为唯一的噪声源:因此我们将这种方法称为Dropout Student (DS)。简而言之,它鼓励模型在对特定目标数据集进行预测时限制单个神经元(或过滤器)的影响。
DS 虽然有效,但在各种目标域上都面临模型崩溃问题。我们假设发生这种情况是因为源模型最初对这些目标域缺乏信心。我们建议通过直接使用特征空间作为辅助事实来源来提高 DS 稳定性。NOTELA 通过鼓励对特征空间中的附近点使用类似的伪标签来实现这一点,其灵感来自NRC 方法和拉普拉斯正则化。这种简单的方法如下所示,在音频和视觉任务中都始终显著优于源模型。
NOTELA 实际运行。音频记录通过完整模型进行转发,以获得第一组预测,然后通过拉普拉斯正则化(一种基于聚类附近点的后处理形式)进行细化。最后,细化的预测被用作噪声模型重建的目标。
结论
标准人工图像分类基准无意中限制了我们对 SFDA 方法的真正通用性和稳健性的理解。我们主张扩大范围,采用一种新的评估框架,将自然发生的生物声学分布变化纳入其中。我们还希望 NOTELA 可以作为一个强大的基线,促进该方向的研究。NOTELA 的出色表现或许表明有两个因素可以导致开发更具通用性的模型:首先,开发方法时着眼于更困难的问题;其次,倾向于简单的建模原理。然而,未来仍有工作要做,以查明和理解现有方法在更困难问题上的失败模式。我们相信我们的研究代表了朝这个方向迈出的重要一步,为设计具有更高通用性的 SFDA 方法奠定了基础。
致谢
本文作者之一 Eleni Triantafillou 目前就职于 Google DeepMind。我们代表 NOTELA 论文的作者发布这篇博文:Malik Boudiaf、Tom Denton、Bart van Merriënboer、Vincent Dumoulin*、Eleni Triantafillou*(其中 * 表示贡献相同)。我们感谢我们的合著者为本文付出的辛勤工作,以及 Perch 团队其他成员的支持和反馈。
评论